CIEC: Coupling Implicit and Explicit Cues for Multimodal Weakly Supervised Manipulation Localization
作者: Xinquan Yu, Wei Lu, Xiangyang Luo
分类: cs.CV
发布日期: 2026-02-02
💡 一句话要点
提出CIEC框架,利用弱监督实现多模态图像-文本篡改定位。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 弱监督学习 篡改定位 图像文本对 虚假信息检测
📋 核心要点
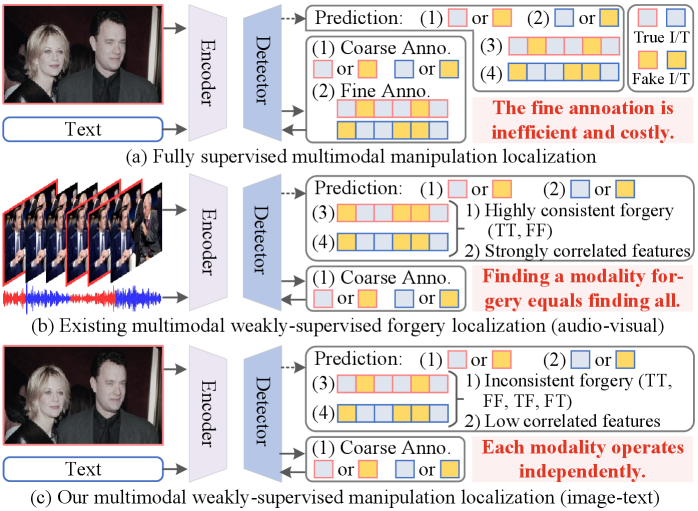
- 现有方法依赖于细粒度标注,成本高昂,限制了多模态篡改定位的应用。
- CIEC框架通过耦合隐式和显式线索,仅使用粗粒度标注实现弱监督篡改定位。
- 实验结果表明,CIEC在多个评估指标上可达到与全监督方法相当的性能。
📝 摘要(中文)
为了减轻虚假信息带来的威胁,多模态篡改定位日益受到关注。现有方法依赖于昂贵且耗时的细粒度标注,例如patch/token级别的标注。本文提出了一种名为耦合隐式和显式线索(CIEC)的新框架,旨在仅利用粗粒度的图像/句子级别标注,实现图像-文本对的多模态弱监督篡改定位。该框架包含两个分支:基于图像的弱监督定位和基于文本的弱监督定位。对于前者,我们设计了文本引导的精细化Patch选择(TRPS)模块,它整合了来自视觉和文本角度的伪造线索,并在空间先验的辅助下锁定可疑区域,然后通过背景抑制和空间对比约束来抑制来自不相关区域的干扰。对于后者,我们设计了视觉偏差校准的Token Grounding(VCTG)模块,它专注于有意义的内容词,并利用相对视觉偏差来辅助token定位,然后通过非对称稀疏和语义一致性约束来减轻标签噪声并确保可靠性。大量的实验表明了CIEC的有效性,其结果在多个评估指标上与完全监督方法相当。
🔬 方法详解
问题定义:本文旨在解决多模态(图像-文本)篡改定位问题,即确定图像中被篡改的区域以及文本中对应的篡改描述。现有方法依赖于patch/token级别的细粒度标注,这需要大量的人工成本,限制了其在实际场景中的应用。因此,如何在只有图像/句子级别粗粒度标注的情况下,实现有效的篡改定位是一个关键挑战。
核心思路:CIEC的核心思路是耦合图像和文本的隐式和显式线索,利用弱监督学习的方式进行篡改定位。具体来说,图像分支通过文本引导来选择更具欺骗性的图像区域,文本分支则通过视觉偏差来定位文本中与篡改相关的token。通过图像和文本之间的互补信息,可以更准确地定位篡改区域和描述。
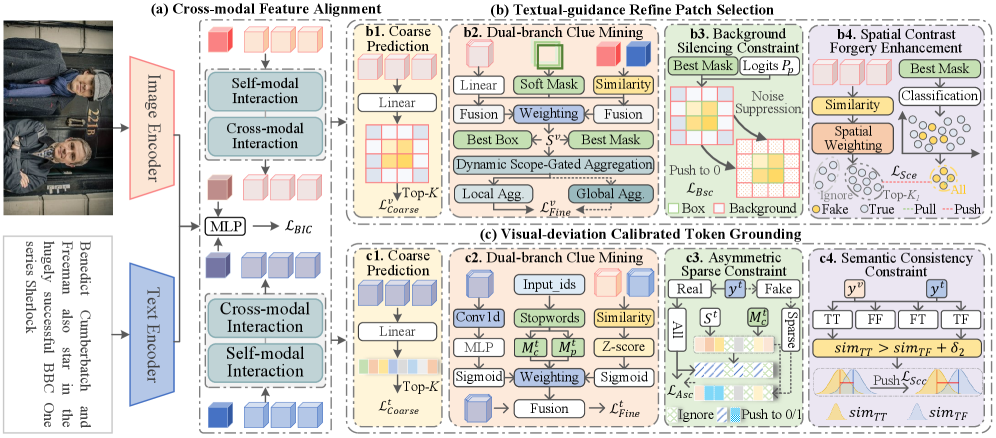
技术框架:CIEC框架包含两个主要分支:基于图像的弱监督定位和基于文本的弱监督定位。图像分支包含Textual-guidance Refine Patch Selection (TRPS)模块,用于选择可疑的图像区域,并使用背景抑制和空间对比约束来减少干扰。文本分支包含Visual-deviation Calibrated Token Grounding (VCTG)模块,用于定位文本中与篡改相关的token,并使用非对称稀疏和语义一致性约束来提高可靠性。两个分支的结果可以相互验证和补充,从而提高整体的定位精度。
关键创新:CIEC的关键创新在于:1) 提出了TRPS模块,利用文本信息引导图像区域的选择,从而更准确地定位篡改区域。2) 提出了VCTG模块,利用视觉偏差来校准token grounding,从而更准确地定位文本中与篡改相关的token。3) 通过耦合图像和文本的隐式和显式线索,实现了多模态弱监督篡改定位,避免了对细粒度标注的依赖。
关键设计:TRPS模块的关键设计包括:使用文本特征来指导patch的选择,并使用空间先验来约束patch的位置。VCTG模块的关键设计包括:使用视觉偏差来校准token grounding,并使用非对称稀疏和语义一致性约束来减轻标签噪声。此外,CIEC还使用了多种损失函数来优化模型的性能,例如对比损失、稀疏损失和一致性损失。
🖼️ 关键图片

📊 实验亮点
CIEC框架在多个评估指标上取得了与全监督方法相当的性能,证明了其有效性。具体来说,CIEC在篡改区域定位的准确率和召回率方面都取得了显著的提升。此外,CIEC还具有较强的鲁棒性,能够有效地处理各种类型的篡改。
🎯 应用场景
CIEC框架可应用于新闻真实性检测、社交媒体内容审核、图像取证等领域。通过自动定位图像和文本中的篡改区域,可以帮助人们识别虚假信息,提高信息的可信度。该研究的成果有助于构建更安全、更可靠的网络环境,减少虚假信息带来的负面影响。
📄 摘要(原文)
To mitigate the threat of misinformation, multimodal manipulation localization has garnered growing attention. Consider that current methods rely on costly and time-consuming fine-grained annotations, such as patch/token-level annotations. This paper proposes a novel framework named Coupling Implicit and Explicit Cues (CIEC), which aims to achieve multimodal weakly-supervised manipulation localization for image-text pairs utilizing only coarse-grained image/sentence-level annotations. It comprises two branches, image-based and text-based weakly-supervised localization. For the former, we devise the Textual-guidance Refine Patch Selection (TRPS) module. It integrates forgery cues from both visual and textual perspectives to lock onto suspicious regions aided by spatial priors. Followed by the background silencing and spatial contrast constraints to suppress interference from irrelevant areas. For the latter, we devise the Visual-deviation Calibrated Token Grounding (VCTG) module. It focuses on meaningful content words and leverages relative visual bias to assist token localization. Followed by the asymmetric sparse and semantic consistency constraints to mitigate label noise and ensure reliability. Extensive experiments demonstrate the effectiveness of our CIEC, yielding results comparable to fully supervised methods on several evaluation metrics.