LoopViT: Scaling Visual ARC with Looped Transformers
作者: Wen-Jie Shu, Xuerui Qiu, Rui-Jie Zhu, Harold Haodong Chen, Yexin Liu, Harry Yang
分类: cs.CV
发布日期: 2026-02-02
备注: 8 pages, 11 figures
🔗 代码/项目: GITHUB
💡 一句话要点
LoopViT:利用循环Transformer以提升视觉ARC问题的泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉推理 循环Transformer 动态退出 ARC-AGI 迭代计算
📋 核心要点
- 现有视觉Transformer在视觉推理任务中计算深度受限于参数规模,无法有效模拟人类迭代推理过程。
- Loop-ViT通过权重绑定的循环结构解耦推理深度和模型容量,并引入动态退出机制。
- 实验表明,Loop-ViT在ARC-AGI-1基准上超越了更大参数规模的模型,验证了迭代计算的有效性。
📝 摘要(中文)
视觉推理领域的最新进展利用视觉Transformer来解决ARC-AGI基准测试。然而,我们认为前馈架构,其中计算深度严格受限于参数大小,不足以捕捉人类归纳的迭代和算法特性。在这项工作中,我们提出了一种名为Loop-ViT的递归架构,它通过权重绑定的递归将推理深度与模型容量解耦。Loop-ViT迭代一个权重绑定的混合块,结合局部卷积和全局注意力,形成潜在的思维链。至关重要的是,我们引入了一种基于预测熵的无参数动态退出机制:当模型的内部状态“结晶”成低不确定性吸引子时,模型停止推理。在ARC-AGI-1基准测试上的实验结果验证了这一观点:我们18M参数的模型实现了65.8%的准确率,优于73M参数的大型集成模型。这些发现表明,自适应迭代计算为视觉推理提供了一个比简单增加网络宽度更有效的扩展轴。
🔬 方法详解
问题定义:论文旨在解决视觉推理任务中,现有Transformer模型计算深度受限于参数规模的问题。传统前馈网络难以模拟人类迭代、算法式的推理过程,导致模型在ARC-AGI等需要抽象推理的benchmark上表现不佳。现有方法主要通过增加模型宽度或深度来提升性能,但效率较低,且容易过拟合。
核心思路:论文的核心思路是通过引入循环机制,将推理深度与模型参数规模解耦。通过循环迭代一个权重绑定的模块,模型可以在不显著增加参数量的情况下,进行多次推理,从而更好地捕捉数据中的潜在关系。此外,动态退出机制允许模型根据自身状态决定何时停止推理,避免不必要的计算。
技术框架:Loop-ViT的核心是一个循环迭代的Hybrid Block。该Hybrid Block结合了局部卷积和全局注意力机制,用于提取图像特征并进行推理。模型首先通过一个初始的卷积层提取浅层特征,然后将特征输入到循环迭代的Hybrid Block中。在每个迭代步骤中,Hybrid Block更新模型的内部状态。动态退出机制根据模型内部状态的预测熵决定是否停止迭代。最终,模型输出推理结果。
关键创新:Loop-ViT的关键创新在于:1) 权重绑定的循环结构,允许模型在不增加参数量的情况下进行多次推理;2) 基于预测熵的动态退出机制,使模型能够自适应地决定何时停止推理,提高计算效率。这种设计使得模型能够更有效地利用计算资源,并更好地泛化到新的任务中。
关键设计:Hybrid Block由局部卷积和全局注意力组成,卷积用于提取局部特征,注意力用于捕捉全局关系。动态退出机制基于预测熵,当预测熵低于某个阈值时,模型停止迭代。该阈值是一个超参数,可以通过实验进行调整。损失函数为交叉熵损失,用于训练模型进行分类。
🖼️ 关键图片

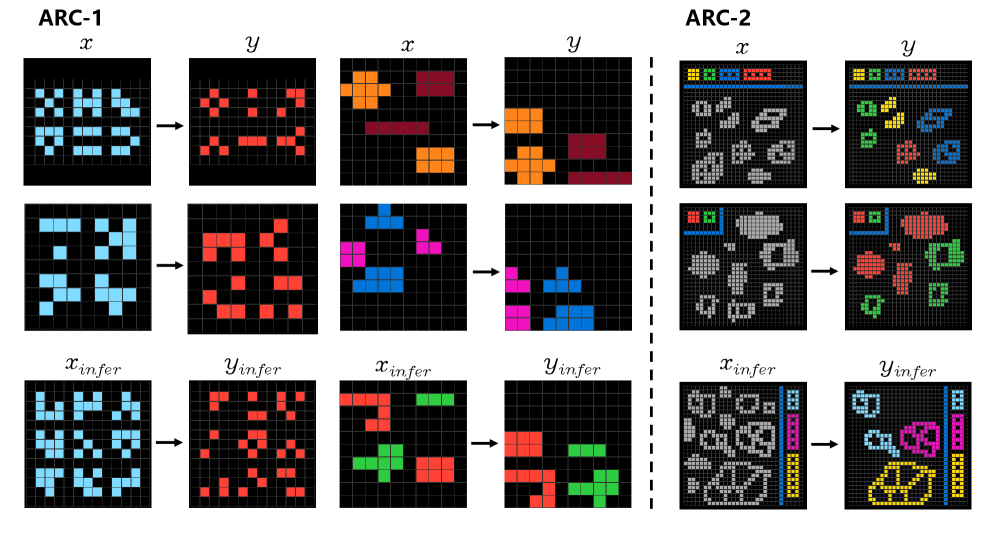

📊 实验亮点
Loop-ViT在ARC-AGI-1基准测试上取得了显著成果,仅使用18M参数的模型就达到了65.8%的准确率,超越了参数量高达73M的集成模型。这一结果表明,通过自适应迭代计算,可以更有效地提升视觉推理模型的性能,而不仅仅是增加网络宽度。
🎯 应用场景
Loop-ViT的潜在应用领域包括通用人工智能、机器人视觉、自动驾驶等。该研究提出的循环推理和动态退出机制可以应用于其他需要迭代推理的任务中,例如视频理解、自然语言处理等。通过提高模型的推理效率和泛化能力,Loop-ViT有望推动人工智能技术在实际应用中的发展。
📄 摘要(原文)
Recent advances in visual reasoning have leveraged vision transformers to tackle the ARC-AGI benchmark. However, we argue that the feed-forward architecture, where computational depth is strictly bound to parameter size, falls short of capturing the iterative, algorithmic nature of human induction. In this work, we propose a recursive architecture called Loop-ViT, which decouples reasoning depth from model capacity through weight-tied recurrence. Loop-ViT iterates a weight-tied Hybrid Block, combining local convolutions and global attention, to form a latent chain of thought. Crucially, we introduce a parameter-free Dynamic Exit mechanism based on predictive entropy: the model halts inference when its internal state ``crystallizes" into a low-uncertainty attractor. Empirical results on the ARC-AGI-1 benchmark validate this perspective: our 18M model achieves 65.8% accuracy, outperforming massive 73M-parameter ensembles. These findings demonstrate that adaptive iterative computation offers a far more efficient scaling axis for visual reasoning than simply increasing network width. The code is available at https://github.com/WenjieShu/LoopViT.