Rethinking Genomic Modeling Through Optical Character Recognition
作者: Hongxin Xiang, Pengsen Ma, Yunkang Cao, Di Yu, Haowen Chen, Xinyu Yang, Xiangxiang Zeng
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出OpticalDNA以解决基因组建模中的信息浪费问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 基因组建模 光学字符识别 视觉布局 信息压缩 生物信息学
📋 核心要点
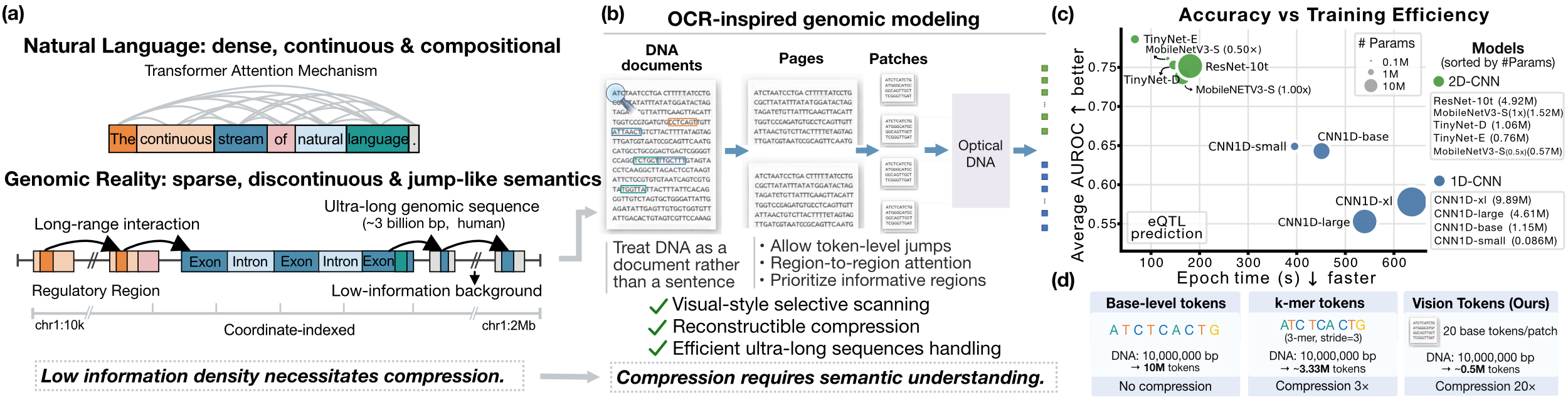
- 现有基因组模型通常将DNA视为一维序列,导致信息处理效率低下,无法有效捕捉基因组的复杂语义。
- 本文提出OpticalDNA框架,通过将DNA转化为结构化视觉布局,利用OCR技术进行基因组建模,提升信息压缩和理解能力。
- 在多个基因组基准测试中,OpticalDNA表现优异,处理长达450k碱基的序列时,使用的有效标记数量减少近20倍,且参数调优仅需256k可训练参数。
📝 摘要(中文)
近年来的基因组基础模型大多采用将DNA视为一维标记序列的大型语言模型架构。然而,全面的顺序读取与稀疏和不连续的基因组语义在结构上不匹配,导致在低信息背景上浪费计算资源,并阻碍了基于理解的长上下文压缩。本文提出了OpticalDNA,一个基于视觉的框架,将基因组建模重新构想为光学字符识别(OCR)风格的文档理解。OpticalDNA将DNA呈现为结构化的视觉布局,并训练一个具有OCR能力的视觉-语言模型,使用视觉DNA编码器和文档解码器,生成紧凑的可重构视觉标记以实现高保真压缩。基于这种表示,OpticalDNA定义了基于提示的目标,涵盖核心基因组原语,从而学习布局感知的DNA表示,在减少有效标记预算的同时保留细粒度的基因组信息。
🔬 方法详解
问题定义:现有基因组模型在处理DNA时,采用一维标记序列的方式,导致在低信息背景上浪费计算资源,无法有效捕捉稀疏和不连续的基因组语义。
核心思路:OpticalDNA通过将DNA转化为结构化的视觉布局,借助OCR技术进行文档理解,旨在提升基因组建模的效率和准确性。
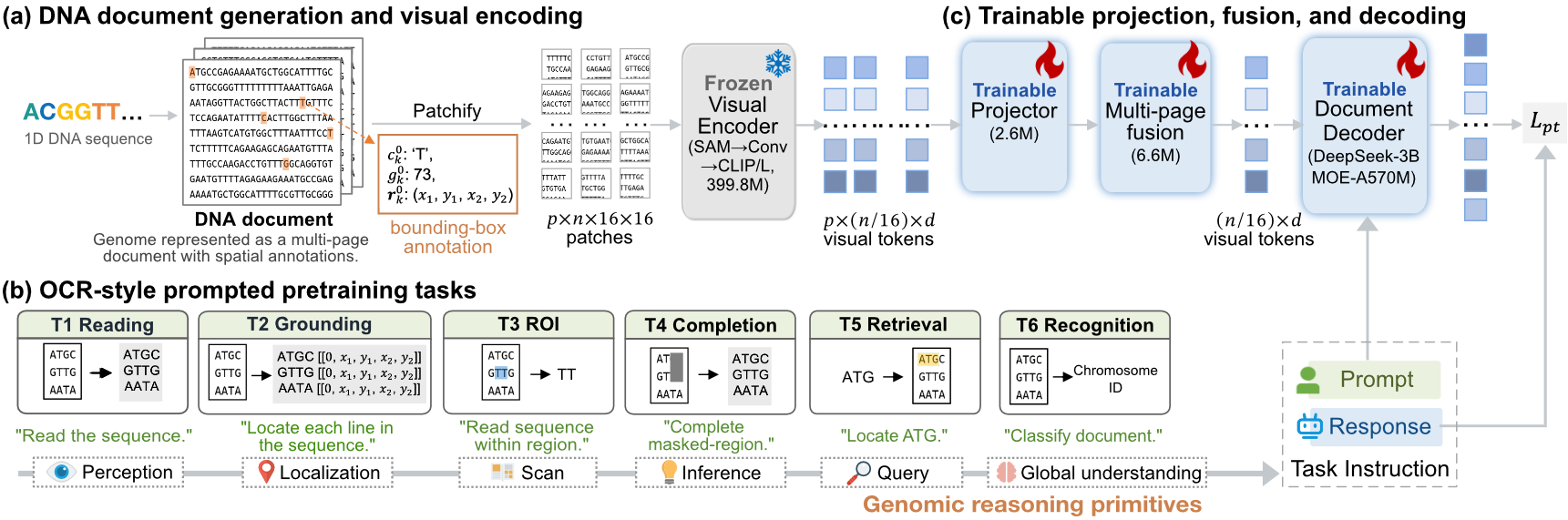
技术框架:OpticalDNA的整体架构包括视觉DNA编码器和文档解码器。编码器生成紧凑的可重构视觉标记,解码器则负责将这些标记转化为可理解的基因组信息。
关键创新:OpticalDNA的主要创新在于将基因组建模视为OCR任务,通过视觉布局的方式处理DNA,显著提高了信息压缩的效率,与传统方法形成鲜明对比。
关键设计:在设计中,OpticalDNA采用了提示条件目标,涵盖基因组的核心原语,如读取、区域定位、子序列检索和掩码跨度补全,确保在减少有效标记预算的同时,保留细粒度的基因组信息。
🖼️ 关键图片
📊 实验亮点
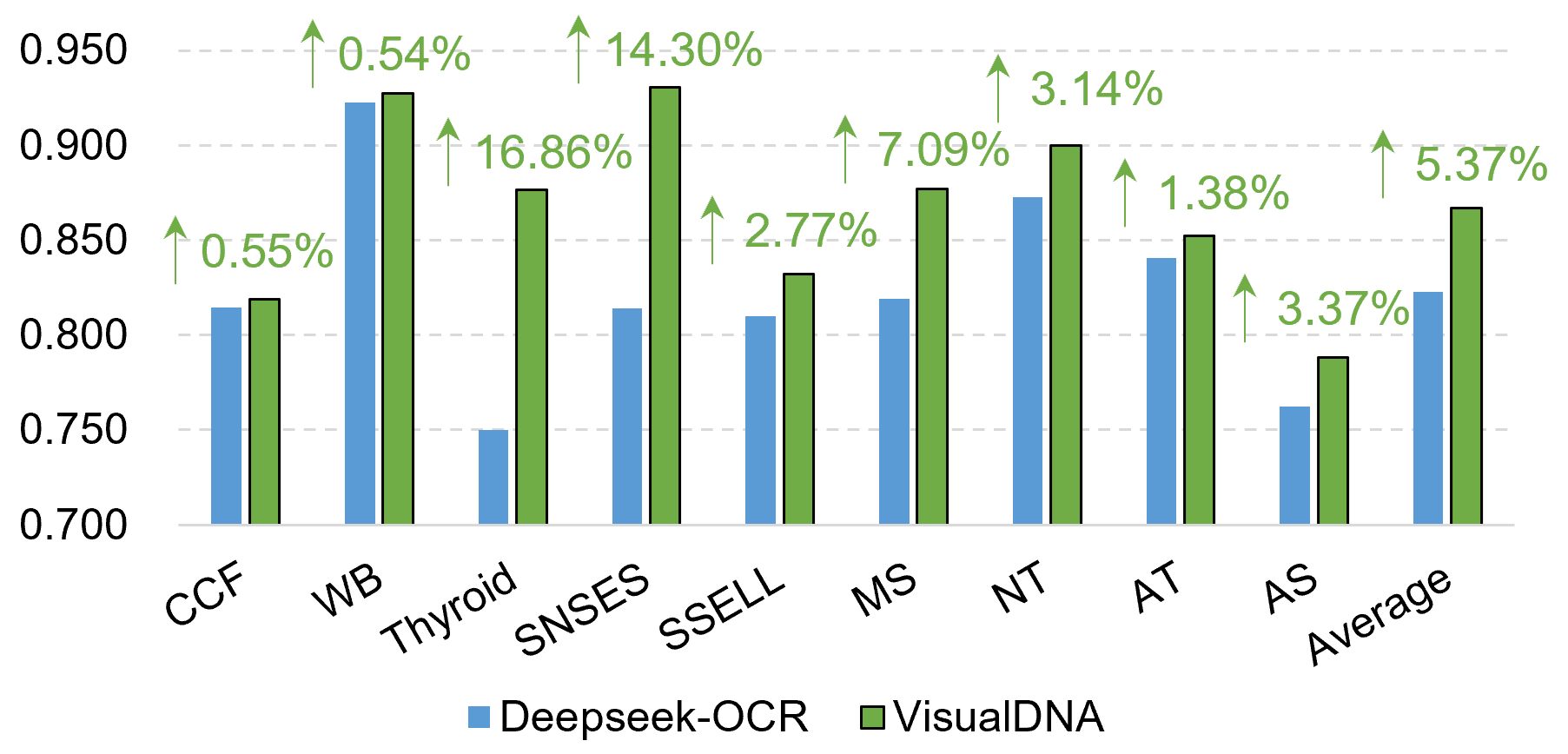
OpticalDNA在多个基因组基准测试中表现出色,处理长达450k碱基的序列时,使用的有效标记数量减少近20倍,且在参数调优方面仅需256k可训练参数,超越了使用985倍更多激活参数的模型。
🎯 应用场景
该研究的潜在应用领域包括基因组学、个性化医疗和生物信息学等。通过提高基因组数据的处理效率,OpticalDNA能够帮助研究人员更好地理解基因组结构与功能之间的关系,推动精准医疗的发展。
📄 摘要(原文)
Recent genomic foundation models largely adopt large language model architectures that treat DNA as a one-dimensional token sequence. However, exhaustive sequential reading is structurally misaligned with sparse and discontinuous genomic semantics, leading to wasted computation on low-information background and preventing understanding-driven compression for long contexts. Here, we present OpticalDNA, a vision-based framework that reframes genomic modeling as Optical Character Recognition (OCR)-style document understanding. OpticalDNA renders DNA into structured visual layouts and trains an OCR-capable vision--language model with a \emph{visual DNA encoder} and a \emph{document decoder}, where the encoder produces compact, reconstructible visual tokens for high-fidelity compression. Building on this representation, OpticalDNA defines prompt-conditioned objectives over core genomic primitives-reading, region grounding, subsequence retrieval, and masked span completion-thereby learning layout-aware DNA representations that retain fine-grained genomic information under a reduced effective token budget. Across diverse genomic benchmarks, OpticalDNA consistently outperforms recent baselines; on sequences up to 450k bases, it achieves the best overall performance with nearly $20\times$ fewer effective tokens, and surpasses models with up to $985\times$ more activated parameters while tuning only 256k \emph{trainable} parameters.