ClueTracer: Question-to-Vision Clue Tracing for Training-Free Hallucination Suppression in Multimodal Reasoning
作者: Gongli Xi, Kun Wang, Zeming Gao, Huahui Yi, Haolang Lu, Ye Tian, Wendong Wang
分类: cs.CV, cs.AI
发布日期: 2026-02-02
备注: 20 pages, 7 figures
💡 一句话要点
提出ClueTracer,无需训练即可抑制多模态推理中的幻觉问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 幻觉抑制 视觉问答 线索追踪 推理漂移
📋 核心要点
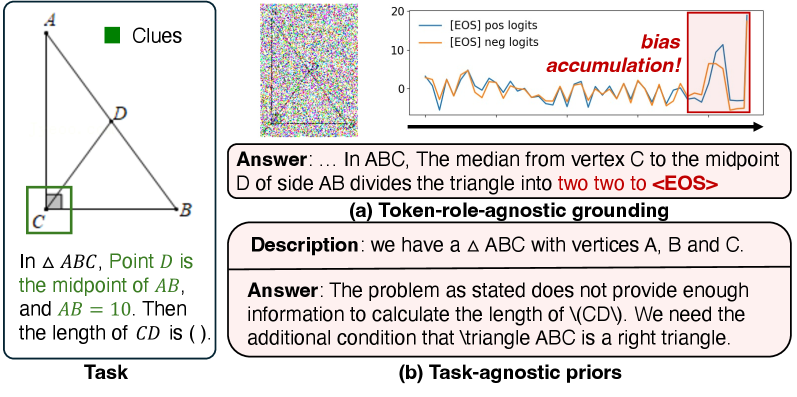
- 现有方法在多模态推理中易产生幻觉,即生成内容与图像或问题不符,根本原因是推理过程中视觉线索的偏离。
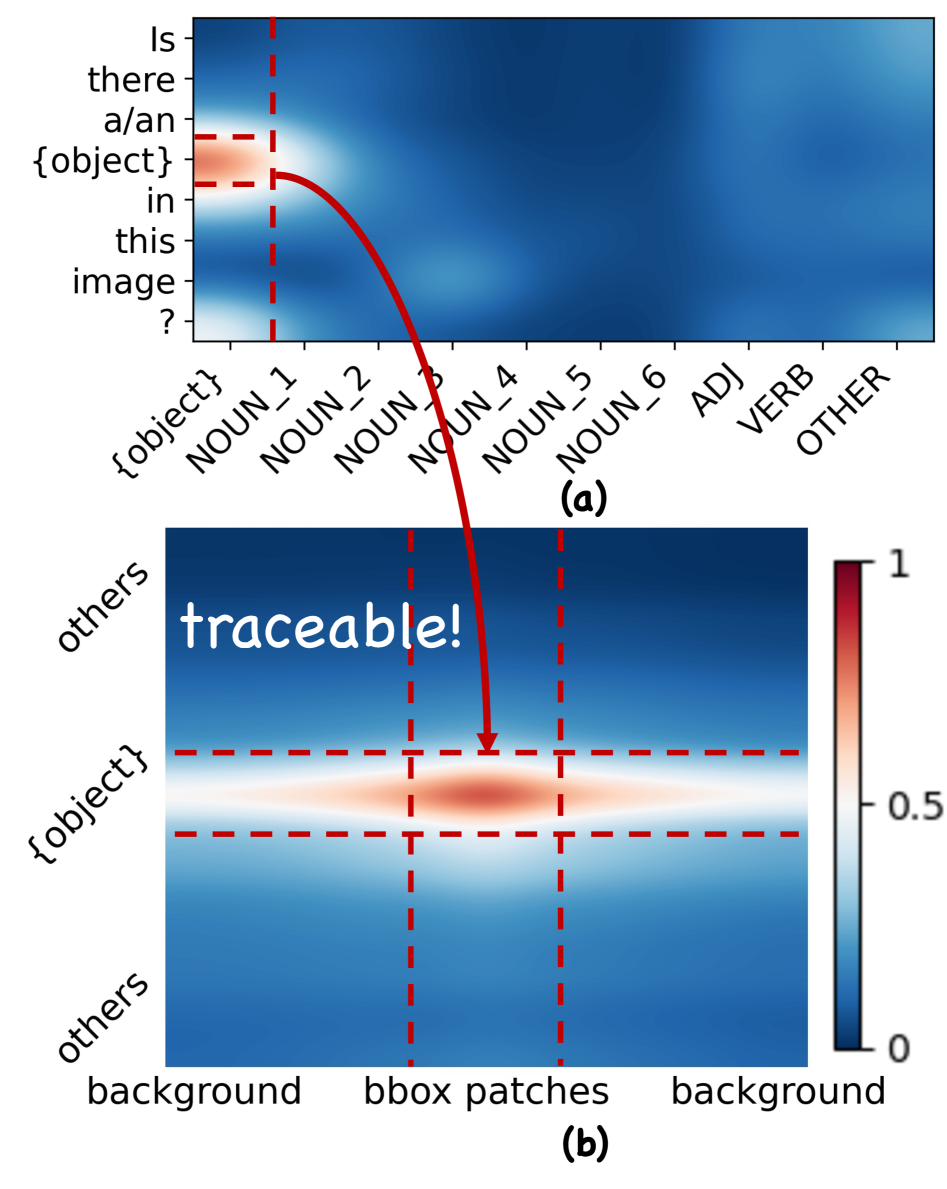
- ClueTracer通过追踪问题到视觉token的线索传播路径,定位任务相关区域,抑制不相关区域的干扰,从而抑制幻觉。
- ClueTracer无需额外训练,即可显著提升多种推理架构在推理和非推理任务上的性能,具有良好的通用性。
📝 摘要(中文)
大型多模态推理模型通过显式的长链推理解决复杂的视觉问题:它们从图像中收集视觉线索,并将这些线索解码为文本token。然而,这种能力也增加了幻觉现象,即模型生成的内容没有得到输入图像或问题的支持。为了理解这种失败模式,我们提出了“推理漂移”的概念:在线索收集过程中,模型过度关注与问题无关的实体,从而削弱了对任务相关线索的关注,并逐渐将推理轨迹与视觉基础脱钩。因此,许多为非推理模型开发的推理时定位或干预方法无法精确定位推理设置中的真实线索。受这些见解的启发,我们引入了ClueRecall,一种用于评估视觉线索检索的指标,并提出了ClueTracer,一种无需训练、无需参数且与架构无关的插件,用于抑制幻觉。ClueTracer从问题出发,追踪关键线索如何沿着模型的推理路径传播(问题→输出→视觉token),从而定位任务相关的图像块,同时抑制对不相关区域的虚假关注。值得注意的是,在没有任何额外训练的情况下,ClueTracer在推理基准测试中将所有推理架构(包括R1-OneVision、Ocean-R1、MM-Eureka等)的性能提高了1.21倍。当转移到非推理设置时,它产生了1.14倍的增益。
🔬 方法详解
问题定义:论文旨在解决多模态推理模型中存在的幻觉问题,即模型生成的内容与输入图像或问题不一致。现有方法在推理过程中容易发生“推理漂移”,导致模型过度关注与任务无关的视觉信息,从而产生幻觉。现有针对非推理模型的干预方法难以有效解决该问题。
核心思路:论文的核心思路是从问题出发,反向追踪模型推理过程中关键线索的传播路径,从而定位与任务相关的视觉区域,并抑制对无关区域的关注。通过这种方式,可以纠正推理过程中的“推理漂移”,减少幻觉的产生。
技术框架:ClueTracer是一个插件式的框架,可以集成到现有的多模态推理模型中。其主要流程包括:1) 从问题出发,分析模型生成的输出,确定关键线索;2) 追踪这些关键线索在模型推理路径上的传播,特别是从输出到视觉token的传播;3) 根据线索传播的路径,定位与任务相关的图像区域;4) 通过抑制对无关区域的关注,减少幻觉的产生。
关键创新:ClueTracer的关键创新在于其训练自由和参数自由的特性,以及其反向追踪线索传播路径的思路。与现有方法相比,ClueTracer不需要额外的训练数据或参数调整,即可有效抑制幻觉。此外,ClueTracer通过反向追踪线索传播路径,能够更准确地定位与任务相关的视觉区域,从而更有效地抑制幻觉。
关键设计:ClueTracer的关键设计在于ClueRecall指标,用于评估视觉线索检索的质量。具体的技术细节包括如何定义和提取关键线索,如何追踪线索在模型中的传播路径,以及如何根据线索传播路径来定位和抑制图像区域。论文中没有明确给出具体的参数设置或损失函数,因为ClueTracer是一个训练自由的方法。
🖼️ 关键图片

📊 实验亮点
ClueTracer在多个推理基准测试中显著提升了现有模型的性能,平均提升幅度达到1.21倍。即使在非推理任务中,也取得了1.14倍的性能提升。值得注意的是,这些提升是在没有任何额外训练的情况下实现的,充分证明了ClueTracer的有效性和通用性。
🎯 应用场景
ClueTracer可广泛应用于需要可靠多模态推理的场景,例如视觉问答、图像描述、机器人导航等。通过抑制幻觉,可以提高模型的准确性和可靠性,从而在医疗诊断、自动驾驶等安全攸关领域发挥重要作用。未来,该方法可以进一步扩展到其他多模态任务和模型架构。
📄 摘要(原文)
Large multimodal reasoning models solve challenging visual problems via explicit long-chain inference: they gather visual clues from images and decode clues into textual tokens. Yet this capability also increases hallucinations, where the model generates content that is not supported by the input image or the question. To understand this failure mode, we identify \emph{reasoning drift}: during clue gathering, the model over-focuses on question-irrelevant entities, diluting focus on task-relevant cues and gradually decoupling the reasoning trace from visual grounding. As a consequence, many inference-time localization or intervention methods developed for non-reasoning models fail to pinpoint the true clues in reasoning settings. Motivated by these insights, we introduce ClueRecall, a metric for assessing visual clue retrieval, and present ClueTracer, a training-free, parameter-free, and architecture-agnostic plugin for hallucination suppression. ClueTracer starts from the question and traces how key clues propagate along the model's reasoning pathway (question $\rightarrow$ outputs $\rightarrow$ visual tokens), thereby localizing task-relevant patches while suppressing spurious attention to irrelevant regions. Remarkably, \textbf{without any additional training}, ClueTracer improves all \textbf{reasoning} architectures (including \texttt{R1-OneVision}, \texttt{Ocean-R1}, \texttt{MM-Eureka}, \emph{etc}.) by $\mathbf{1.21\times}$ on reasoning benchmarks. When transferred to \textbf{non-reasoning} settings, it yields a $\mathbf{1.14\times}$ gain.