UniDriveDreamer: A Single-Stage Multimodal World Model for Autonomous Driving
作者: Guosheng Zhao, Yaozeng Wang, Xiaofeng Wang, Zheng Zhu, Tingdong Yu, Guan Huang, Yongchen Zai, Ji Jiao, Changliang Xue, Xiaole Wang, Zhen Yang, Futang Zhu, Xingang Wang
分类: cs.CV
发布日期: 2026-02-02
备注: 16 pages, 7 figures
💡 一句话要点
UniDriveDreamer:用于自动驾驶的单阶段多模态世界模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 世界模型 多模态融合 视频生成 LiDAR生成
📋 核心要点
- 现有世界模型主要集中于单模态生成,如多摄像头视频或LiDAR序列合成,缺乏对多模态数据的统一建模能力。
- UniDriveDreamer提出单阶段统一多模态世界模型,通过统一潜在锚定(ULA)对齐不同模态的潜在分布,实现跨模态融合。
- 实验结果表明,UniDriveDreamer在视频和LiDAR生成方面超越了现有技术,并在下游任务中取得了显著的性能提升。
📝 摘要(中文)
本文提出UniDriveDreamer,一种用于自动驾驶的单阶段统一多模态世界模型,可以直接生成多模态的未来观测,而无需依赖中间表示或级联模块。该框架引入了一个LiDAR特定的变分自编码器(VAE)来编码输入的LiDAR序列,以及一个用于多摄像头图像的视频VAE。为了确保跨模态兼容性和训练稳定性,提出了统一潜在锚定(ULA),显式地对齐两种模态的潜在分布。对齐后的特征被融合,并通过扩散Transformer进行处理,该Transformer联合建模它们的几何对应关系和时间演化。此外,结构化的场景布局信息被投影为每种模态的条件信号,以指导合成。大量实验表明,UniDriveDreamer在视频和LiDAR生成方面都优于以往的最先进方法,同时在下游任务中也产生了可衡量的改进。
🔬 方法详解
问题定义:现有自动驾驶世界模型主要关注单模态数据(如视频或LiDAR)的生成,缺乏对多模态数据的联合建模能力。这限制了模型对复杂场景的理解和预测能力,也阻碍了其在下游任务中的应用。现有方法通常采用级联或中间表示的方式处理多模态数据,增加了模型的复杂性和训练难度。
核心思路:UniDriveDreamer的核心思路是构建一个单阶段的统一多模态世界模型,直接从多模态输入生成多模态的未来观测。通过引入统一潜在锚定(ULA)机制,显式地对齐不同模态的潜在分布,从而实现跨模态信息的有效融合和利用。这种设计避免了中间表示和级联模块,简化了模型结构,提高了训练效率。
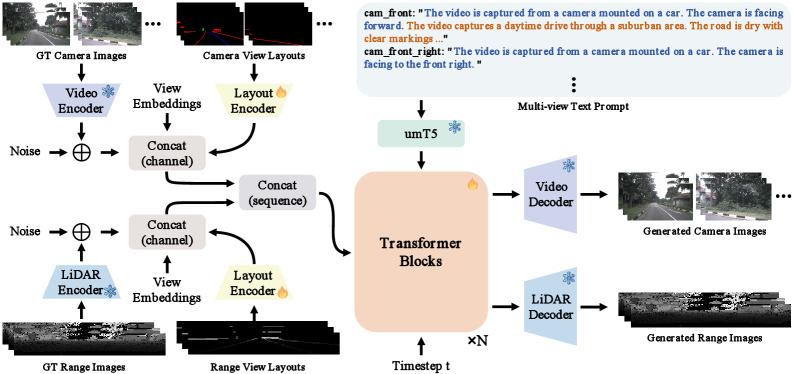
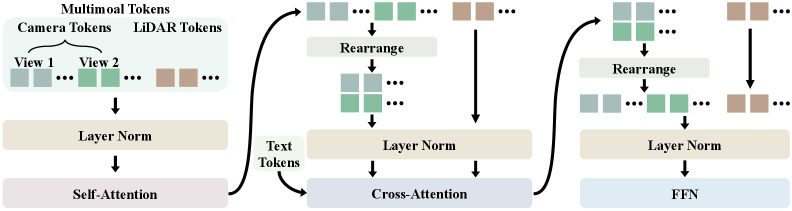
技术框架:UniDriveDreamer的整体架构包括以下几个主要模块:1) LiDAR VAE:用于编码输入的LiDAR序列,提取LiDAR特征。2) 视频VAE:用于编码多摄像头图像,提取视频特征。3) 统一潜在锚定(ULA):用于对齐LiDAR和视频的潜在分布,确保跨模态兼容性。4) 扩散Transformer:用于融合对齐后的特征,并建模它们的几何对应关系和时间演化,生成多模态的未来观测。5) 场景布局投影:将结构化的场景布局信息投影为每种模态的条件信号,以指导合成。
关键创新:UniDriveDreamer的关键创新在于以下几点:1) 单阶段多模态生成:直接生成多模态未来观测,无需中间表示或级联模块。2) 统一潜在锚定(ULA):显式地对齐不同模态的潜在分布,实现跨模态信息的有效融合。3) 扩散Transformer:联合建模几何对应关系和时间演化,提高生成质量。与现有方法相比,UniDriveDreamer能够更有效地利用多模态信息,生成更准确、更逼真的未来场景。
关键设计:LiDAR VAE和视频VAE采用标准的VAE结构,损失函数包括重构损失和KL散度损失。ULA通过最小化不同模态潜在分布之间的距离来实现对齐。扩散Transformer采用标准的Transformer结构,并引入了注意力机制来建模几何对应关系。场景布局投影将场景布局信息编码为向量,并将其作为条件输入到扩散Transformer中。具体的参数设置和网络结构细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片
📊 实验亮点
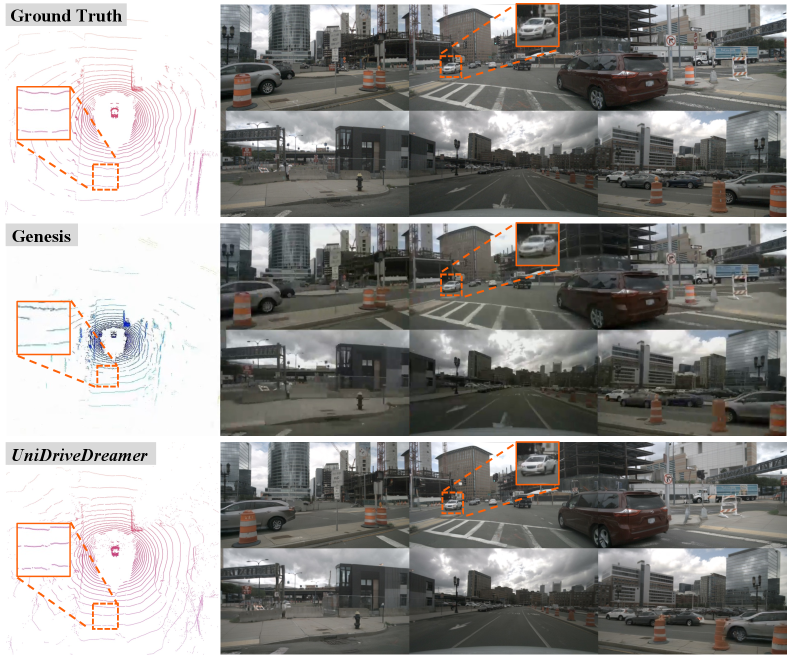
UniDriveDreamer在视频和LiDAR生成方面均优于以往的最先进方法。具体性能数据和提升幅度未在摘要中给出,需要在论文中查找。摘要中提到,该模型在下游任务中也取得了可衡量的改进,但具体任务和性能提升情况未详细说明。
🎯 应用场景
UniDriveDreamer在自动驾驶领域具有广泛的应用前景,可用于数据增强、仿真测试和行为预测。通过生成逼真的多模态未来场景,可以扩充训练数据集,提高自动驾驶系统的鲁棒性和泛化能力。此外,该模型还可以用于仿真测试,评估自动驾驶系统在各种复杂场景下的性能。UniDriveDreamer还可以用于预测其他车辆和行人的未来行为,提高自动驾驶系统的安全性。
📄 摘要(原文)
World models have demonstrated significant promise for data synthesis in autonomous driving. However, existing methods predominantly concentrate on single-modality generation, typically focusing on either multi-camera video or LiDAR sequence synthesis. In this paper, we propose UniDriveDreamer, a single-stage unified multimodal world model for autonomous driving, which directly generates multimodal future observations without relying on intermediate representations or cascaded modules. Our framework introduces a LiDAR-specific variational autoencoder (VAE) designed to encode input LiDAR sequences, alongside a video VAE for multi-camera images. To ensure cross-modal compatibility and training stability, we propose Unified Latent Anchoring (ULA), which explicitly aligns the latent distributions of the two modalities. The aligned features are fused and processed by a diffusion transformer that jointly models their geometric correspondence and temporal evolution. Additionally, structured scene layout information is projected per modality as a conditioning signal to guide the synthesis. Extensive experiments demonstrate that UniDriveDreamer outperforms previous state-of-the-art methods in both video and LiDAR generation, while also yielding measurable improvements in downstream