Beyond Open Vocabulary: Multimodal Prompting for Object Detection in Remote Sensing Images
作者: Shuai Yang, Ziyue Huang, Jiaxin Chen, Qingjie Liu, Yunhong Wang
分类: cs.CV
发布日期: 2026-02-02
💡 一句话要点
提出RS-MPOD,通过多模态Prompting提升遥感图像目标检测的开放词汇泛化能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感图像 目标检测 开放词汇 多模态学习 视觉Prompt 文本Prompt 多模态融合
📋 核心要点
- 遥感开放词汇目标检测依赖文本Prompt,但遥感场景下类别语义的特殊性导致文本-视觉对齐失效,类别指定不稳定。
- RS-MPOD框架结合视觉Prompt、文本Prompt及其融合,利用视觉信息增强类别指定,提高在语义模糊和分布偏移下的鲁棒性。
- 实验表明,视觉Prompt在语义模糊时更可靠,多模态Prompt在文本语义对齐时具有竞争力,提升了开放词汇检测性能。
📝 摘要(中文)
遥感图像中的开放词汇目标检测通常依赖于纯文本Prompt来指定目标类别,隐含地假设推理时的类别查询可以通过预训练诱导的文本-视觉对齐来可靠地进行。然而,在实践中,由于任务和应用特定的类别语义,这种假设在遥感场景中经常失效,导致开放词汇设置下类别指定的不稳定性。为了解决这个限制,我们提出了RS-MPOD,一个多模态开放词汇检测框架,它通过结合实例级别的视觉Prompt、文本Prompt及其多模态融合来重新定义类别指定,超越了纯文本Prompt。RS-MPOD引入了一个视觉Prompt编码器,用于从示例实例中提取基于外观的类别线索,从而实现无文本的类别指定;以及一个多模态融合模块,用于在两种模态都可用时整合视觉和文本信息。在标准、跨数据集和细粒度遥感基准上的大量实验表明,视觉Prompt在语义模糊和分布偏移下产生更可靠的类别指定,而多模态Prompt提供了一种灵活的替代方案,在文本语义良好对齐时仍然具有竞争力。
🔬 方法详解
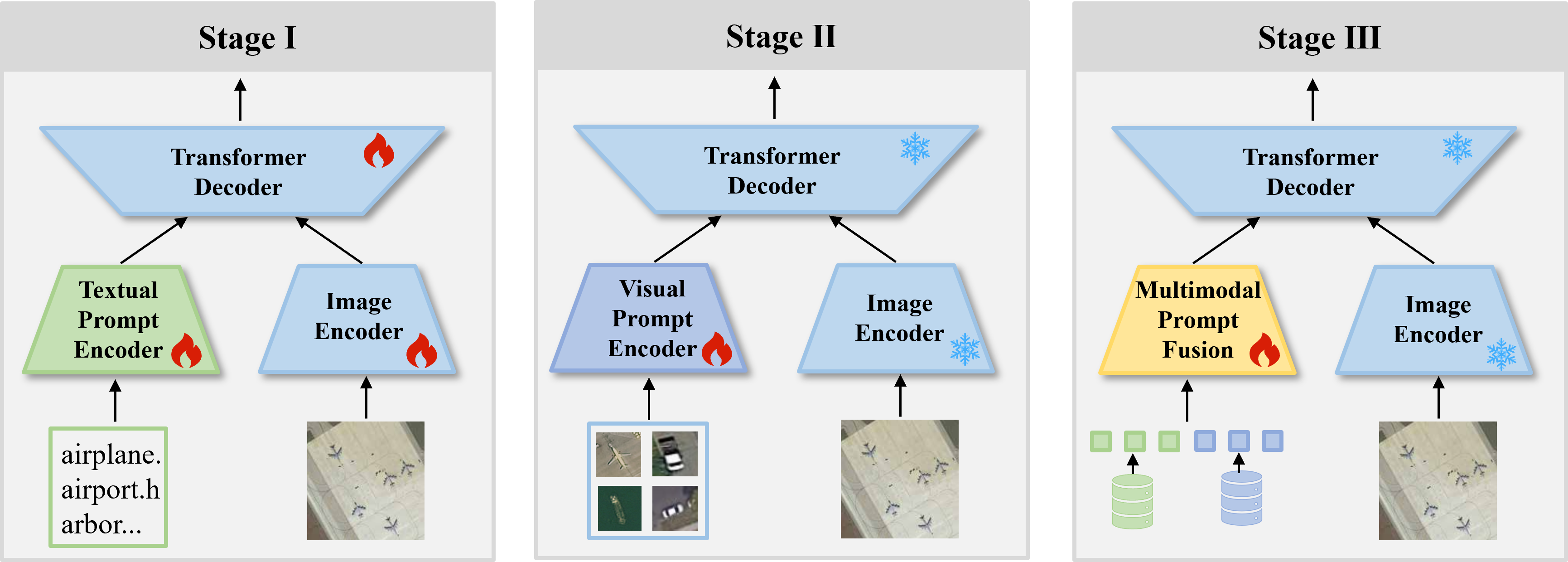
问题定义:遥感图像开放词汇目标检测任务中,现有方法严重依赖文本Prompt来定义目标类别。然而,遥感图像的特殊性在于其类别语义往往具有任务相关性和应用特定性,这使得预训练模型中的文本-视觉对齐难以准确地将文本描述与图像中的目标对应起来,导致类别指定不稳定,尤其是在语义模糊或存在领域偏移的情况下。现有方法缺乏利用图像自身信息进行类别判别的能力。
核心思路:RS-MPOD的核心思路是通过引入视觉Prompt来增强类别指定,从而克服纯文本Prompt的局限性。视觉Prompt直接从目标实例的视觉特征中提取类别信息,避免了对文本-视觉对齐的过度依赖。同时,RS-MPOD还支持多模态Prompting,即同时利用文本和视觉信息,以实现更灵活和鲁棒的类别指定。这种设计旨在利用视觉Prompt在语义模糊和分布偏移下的优势,并在文本语义对齐良好时保持竞争力。
技术框架:RS-MPOD框架主要包含以下几个模块:1) 视觉Prompt编码器:用于从示例实例中提取视觉特征,生成视觉Prompt。2) 文本Prompt编码器:用于编码文本描述,生成文本Prompt。3) 多模态融合模块:用于融合视觉Prompt和文本Prompt,生成最终的类别表示。4) 检测头:基于融合后的类别表示进行目标检测。整体流程是,给定一张遥感图像和一组类别Prompt(可以是文本、视觉或两者),首先分别编码Prompt,然后进行多模态融合,最后通过检测头预测目标的位置和类别。
关键创新:RS-MPOD的关键创新在于引入了视觉Prompt来增强遥感图像开放词汇目标检测的类别指定。与现有方法仅依赖文本Prompt不同,RS-MPOD能够利用目标实例的视觉特征来直接进行类别判别,从而提高了在语义模糊和分布偏移下的鲁棒性。此外,多模态融合模块的设计使得RS-MPOD能够灵活地利用文本和视觉信息,进一步提升了性能。
关键设计:视觉Prompt编码器可以使用各种卷积神经网络(CNN)或Transformer模型,例如ResNet或ViT。多模态融合模块可以使用注意力机制或简单的拼接操作。损失函数通常包括目标检测的损失(例如,分类损失和回归损失)以及可选的Prompt一致性损失,以鼓励视觉Prompt和文本Prompt之间的一致性。具体的参数设置和网络结构需要根据具体的任务和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在标准遥感数据集上,RS-MPOD的视觉Prompting在语义模糊和分布偏移下表现出更强的鲁棒性,显著优于仅使用文本Prompt的方法。多模态Prompting在文本语义对齐良好时也取得了具有竞争力的结果。在跨数据集实验中,RS-MPOD也展现出良好的泛化能力。
🎯 应用场景
RS-MPOD框架可应用于多种遥感图像目标检测任务,例如自然灾害评估、城市规划、农业监测等。通过提供实例级别的视觉Prompt,用户可以更灵活地指定目标类别,无需精确的文本描述,从而降低了使用门槛。该研究有助于提升遥感图像智能解译的自动化水平,为相关领域的决策提供更可靠的支持。
📄 摘要(原文)
Open-vocabulary object detection in remote sensing commonly relies on text-only prompting to specify target categories, implicitly assuming that inference-time category queries can be reliably grounded through pretraining-induced text-visual alignment. In practice, this assumption often breaks down in remote sensing scenarios due to task- and application-specific category semantics, resulting in unstable category specification under open-vocabulary settings. To address this limitation, we propose RS-MPOD, a multimodal open-vocabulary detection framework that reformulates category specification beyond text-only prompting by incorporating instance-grounded visual prompts, textual prompts, and their multimodal integration. RS-MPOD introduces a visual prompt encoder to extract appearance-based category cues from exemplar instances, enabling text-free category specification, and a multimodal fusion module to integrate visual and textual information when both modalities are available. Extensive experiments on standard, cross-dataset, and fine-grained remote sensing benchmarks show that visual prompting yields more reliable category specification under semantic ambiguity and distribution shifts, while multimodal prompting provides a flexible alternative that remains competitive when textual semantics are well aligned.