Q Cache: Visual Attention is Valuable in Less than Half of Decode Layers for Multimodal Large Language Model
作者: Jiedong Zhuang, Lu Lu, Ming Dai, Rui Hu, Jian Chen, Qiang Liu, Haoji Hu
分类: cs.CV
发布日期: 2026-02-02
备注: Accepted by AAAI26
💡 一句话要点
针对多模态大语言模型,提出Q Cache以减少视觉token冗余和KV缓存占用,提升推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 KV缓存优化 注意力机制 推理加速 视觉token 层间注意力共享 Q Cache
📋 核心要点
- 多模态大语言模型中,视觉token数量庞大导致计算成本高昂,KV缓存压力巨大,现有token剪枝方法易破坏KV缓存完整性。
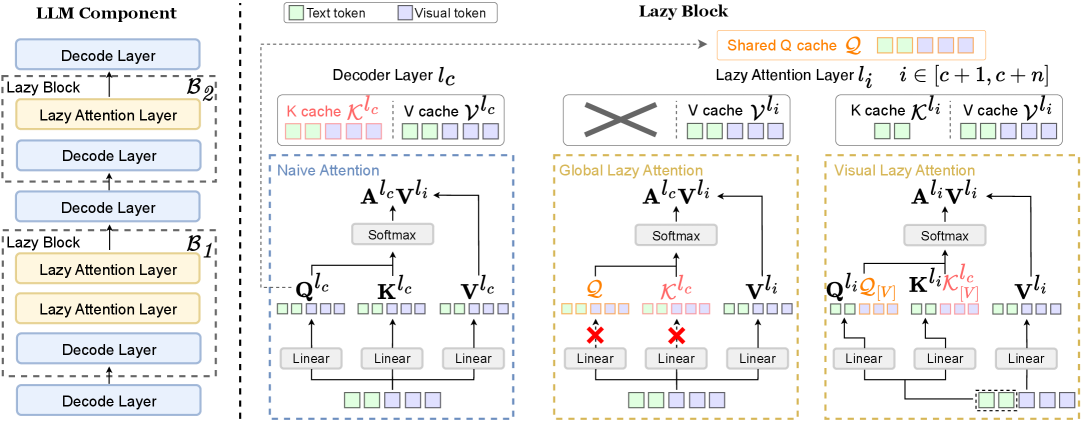
- 论文提出Lazy Attention机制,通过跨层共享相似的注意力模式,减少层间冗余计算,并设计了层共享缓存Q Cache。
- 实验表明,该方法在牺牲少量性能(约1%)的情况下,可减少超过35%的KV缓存使用,并提升1.5倍吞吐量。
📝 摘要(中文)
多模态大语言模型(MLLM)由于视觉编码器中大量的视觉token而面临高昂的推理成本。冗余的视觉token导致巨大的计算负担和键值(KV)缓存瓶颈。现有方法侧重于token级别的优化,采用各种复杂的token剪枝技术来消除非关键视觉token。然而,这些方法通常不可避免地损害KV缓存的完整性,导致长文本生成任务失败。为此,我们从一个新的角度对模型的注意力机制进行了深入研究,发现超过一半的解码层中的注意力在语义上是相似的。基于这一发现,我们认为可以通过继承前一层中的注意力来简化某些层中的注意力。因此,我们提出Lazy Attention,一种高效的注意力机制,可以实现相似注意力模式的跨层共享,巧妙地减少了注意力中的层间冗余计算。在Lazy Attention中,我们为MLLM开发了一种新型的层共享缓存Q Cache,它有助于跨相邻层重用查询。Q Cache是轻量级的,并且与现有的推理框架(包括Flash Attention和KV缓存)完全兼容。此外,我们的方法非常灵活,因为它与现有的token级别技术正交,可以独立部署或与token剪枝方法结合使用。在多个基准上的经验评估表明,我们的方法可以将KV缓存使用量减少35%以上,并实现1.5倍的吞吐量提升,同时仅牺牲约1%的性能。与SOTA token级别方法相比,我们的技术实现了卓越的精度保持。
🔬 方法详解
问题定义:多模态大语言模型(MLLM)在处理视觉信息时,需要将图像编码为大量的视觉token。这些token增加了计算负担,特别是KV缓存的占用,限制了模型的推理速度和可处理的序列长度。现有的token剪枝方法试图减少token数量,但往往会破坏KV缓存的结构,导致长文本生成等任务性能下降。
核心思路:论文的核心思路是观察到MLLM解码器中,许多层的注意力模式是相似的。因此,可以通过共享这些相似的注意力模式来减少计算冗余。具体来说,某些层的注意力计算可以“懒惰地”继承自前一层,从而避免重复计算。
技术框架:该方法主要包含Lazy Attention机制和Q Cache。Lazy Attention决定哪些层可以共享注意力,而Q Cache则负责存储和重用这些共享的注意力信息。整体流程是:输入视觉token和文本token,经过视觉编码器和语言模型解码器。在解码器中,Lazy Attention根据层间注意力相似性决定是否使用Q Cache中的query向量,如果使用,则跳过当前层的注意力计算,直接使用前一层的注意力结果。
关键创新:最重要的创新点是发现了MLLM解码器中层间注意力模式的冗余性,并提出了利用这种冗余性的Lazy Attention机制。与token剪枝方法不同,该方法不直接减少token数量,而是通过共享注意力来减少计算量,从而避免了破坏KV缓存的风险。
关键设计:Q Cache是专门为MLLM设计的层共享缓存,用于存储query向量。Lazy Attention机制的关键在于如何判断层间注意力是否相似,这可能涉及到相似度度量(例如余弦相似度)和阈值设置。具体的损失函数和网络结构没有特别提及,该方法可以与现有的模型结构和训练方法兼容。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Q Cache方法在多个基准测试中,可以在KV缓存使用量减少超过35%的同时,实现1.5倍的吞吐量提升,而性能损失仅为约1%。与现有的token剪枝方法相比,该方法在保持精度的同时,显著提高了推理效率。
🎯 应用场景
该研究成果可广泛应用于各种多模态大语言模型,尤其是在资源受限的场景下,例如移动设备或边缘计算环境。通过降低KV缓存占用和提高推理速度,可以使MLLM在这些场景下更高效地运行,从而促进其在智能助手、图像描述、视觉问答等领域的应用。
📄 摘要(原文)
Multimodal large language models (MLLMs) are plagued by exorbitant inference costs attributable to the profusion of visual tokens within the vision encoder. The redundant visual tokens engenders a substantial computational load and key-value (KV) cache footprint bottleneck. Existing approaches focus on token-wise optimization, leveraging diverse intricate token pruning techniques to eliminate non-crucial visual tokens. Nevertheless, these methods often unavoidably undermine the integrity of the KV cache, resulting in failures in long-text generation tasks. To this end, we conduct an in-depth investigation towards the attention mechanism of the model from a new perspective, and discern that attention within more than half of all decode layers are semantic similar. Upon this finding, we contend that the attention in certain layers can be streamlined by inheriting the attention from their preceding layers. Consequently, we propose Lazy Attention, an efficient attention mechanism that enables cross-layer sharing of similar attention patterns. It ingeniously reduces layer-wise redundant computation in attention. In Lazy Attention, we develop a novel layer-shared cache, Q Cache, tailored for MLLMs, which facilitates the reuse of queries across adjacent layers. In particular, Q Cache is lightweight and fully compatible with existing inference frameworks, including Flash Attention and KV cache. Additionally, our method is highly flexible as it is orthogonal to existing token-wise techniques and can be deployed independently or combined with token pruning approaches. Empirical evaluations on multiple benchmarks demonstrate that our method can reduce KV cache usage by over 35% and achieve 1.5x throughput improvement, while sacrificing only approximately 1% of performance on various MLLMs. Compared with SOTA token-wise methods, our technique achieves superior accuracy preservation.