Fact or Fake? Assessing the Role of Deepfake Detectors in Multimodal Misinformation Detection
作者: A S M Sharifuzzaman Sagar, Mohammed Bennamoun, Farid Boussaid, Naeha Sharif, Lian Xu, Shaaban Sahmoud, Ali Kishk
分类: cs.CV
发布日期: 2026-02-02
💡 一句话要点
评估Deepfake检测器在多模态虚假信息检测中的作用:语义理解与外部证据至关重要
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态虚假信息检测 Deepfake检测 事实核查 证据驱动 蒙特卡洛树搜索 多智能体辩论 语义理解
📋 核心要点
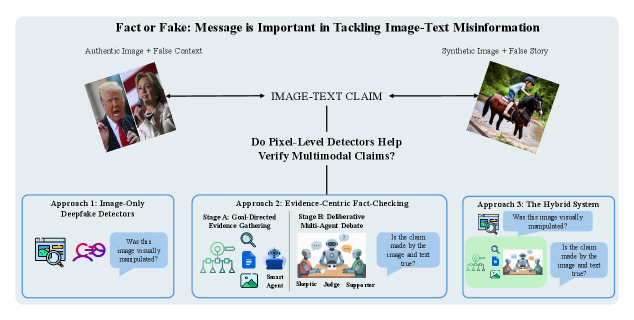
- 现有Deepfake检测器侧重于像素级伪造,忽略了多模态虚假信息中图像-文本的语义关联。
- 提出一种基于证据驱动的事实核查系统,利用蒙特卡洛树搜索和多智能体辩论进行推理。
- 实验表明,Deepfake检测器对多模态虚假信息检测贡献有限,而语义理解和外部证据至关重要。
📝 摘要(中文)
在多模态虚假信息中,欺骗通常不仅源于图像中的像素级篡改,还源于图像-文本对共同表达的语义和上下文声明。然而,大多数旨在检测像素级伪造的deepfake检测器,并没有考虑声明级的含义,尽管它们越来越多地被集成到自动事实核查(AFC)流程中。本文对deepfake检测器在多模态虚假信息检测中的作用进行了首次系统分析。使用MMFakeBench和DGM4两个互补的基准数据集,评估了:(1)最先进的图像deepfake检测器;(2)基于证据驱动的事实核查系统,该系统通过蒙特卡洛树搜索(MCTS)执行工具引导的检索,并通过多智能体辩论(MAD)进行审议推理;(3)将检测器输出作为辅助证据的混合事实核查系统。结果表明,deepfake检测器提供的独立价值有限,并且将其预测纳入事实核查流程会降低性能。相反,以证据为中心的事实核查系统实现了最高的性能。总体而言,研究结果表明,多模态声明验证主要由语义理解和外部证据驱动,像素级伪影信号并不能可靠地增强对真实世界图像-文本虚假信息的推理。
🔬 方法详解
问题定义:论文旨在解决多模态虚假信息检测中,现有Deepfake检测器过度依赖像素级伪造检测,而忽略图像-文本语义关联的问题。现有方法将Deepfake检测器直接应用于多模态信息,未能充分利用文本信息,且可能引入误导性的先验假设,降低事实核查的准确性。
核心思路:论文的核心思路是强调语义理解和外部证据在多模态虚假信息检测中的重要性。通过构建一个以证据为中心的事实核查系统,该系统能够从外部知识库中检索相关证据,并利用多智能体辩论进行推理,从而更准确地判断图像-文本声明的真伪。论文认为,像素级的伪影信号并不能可靠地增强对真实世界图像-文本虚假信息的推理。
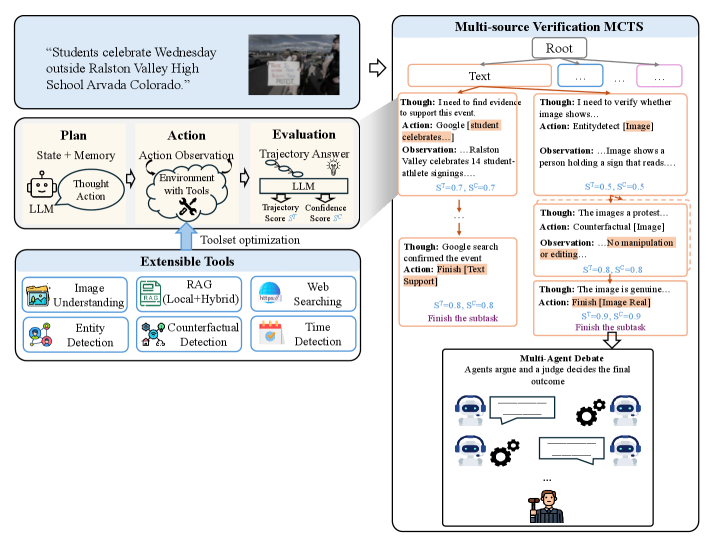
技术框架:该论文提出的证据驱动的事实核查系统主要包含以下几个模块:1) 工具引导的检索:利用蒙特卡洛树搜索(MCTS)从外部知识库中检索与图像-文本声明相关的证据。2) 审议推理:通过多智能体辩论(MAD)对检索到的证据进行推理,判断声明的真伪。3) 混合事实核查系统:将Deepfake检测器的输出作为辅助证据,与检索到的外部证据相结合,进行综合判断。
关键创新:论文最重要的技术创新在于强调了语义理解和外部证据在多模态虚假信息检测中的作用,并构建了一个以证据为中心的事实核查系统。与现有方法相比,该系统能够更有效地利用外部知识库中的信息,并通过多智能体辩论进行推理,从而更准确地判断图像-文本声明的真伪。此外,论文还首次系统地分析了Deepfake检测器在多模态虚假信息检测中的作用,并发现其提供的独立价值有限。
关键设计:论文中关于MCTS和MAD的具体参数设置、损失函数以及网络结构等技术细节未详细描述,属于未知信息。但整体框架强调了证据检索和推理的重要性,而非单纯依赖图像像素级的检测结果。
🖼️ 关键图片
📊 实验亮点
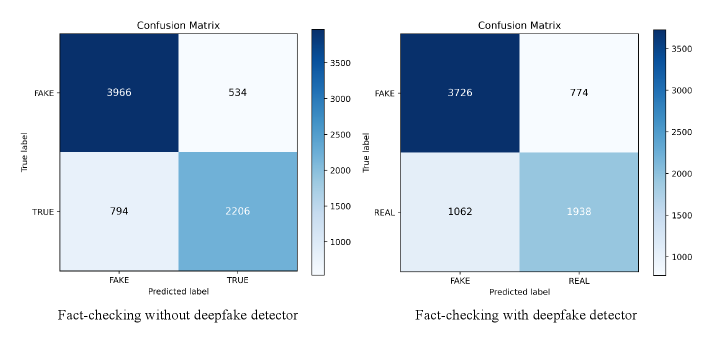
实验结果表明,Deepfake检测器在MMFakeBench和DGM4数据集上的F1分数分别在0.26-0.53和0.33-0.49之间,独立价值有限。将Deepfake检测器的预测纳入事实核查流程,性能下降0.04-0.08 F1。而以证据为中心的事实核查系统在MMFakeBench和DGM4数据集上分别达到约0.81和0.55的F1分数,显著优于其他方法。
🎯 应用场景
该研究成果可应用于自动事实核查系统、社交媒体平台内容审核、新闻媒体真实性验证等领域。通过提升多模态虚假信息检测的准确性,有助于减少虚假信息的传播,维护网络空间的健康生态。未来,该研究可以进一步扩展到其他模态的数据,例如视频、音频等,构建更加完善的多模态虚假信息检测系统。
📄 摘要(原文)
In multimodal misinformation, deception usually arises not just from pixel-level manipulations in an image, but from the semantic and contextual claim jointly expressed by the image-text pair. Yet most deepfake detectors, engineered to detect pixel-level forgeries, do not account for claim-level meaning, despite their growing integration in automated fact-checking (AFC) pipelines. This raises a central scientific and practical question: Do pixel-level detectors contribute useful signal for verifying image-text claims, or do they instead introduce misleading authenticity priors that undermine evidence-based reasoning? We provide the first systematic analysis of deepfake detectors in the context of multimodal misinformation detection. Using two complementary benchmarks, MMFakeBench and DGM4, we evaluate: (1) state-of-the-art image-only deepfake detectors, (2) an evidence-driven fact-checking system that performs tool-guided retrieval via Monte Carlo Tree Search (MCTS) and engages in deliberative inference through Multi-Agent Debate (MAD), and (3) a hybrid fact-checking system that injects detector outputs as auxiliary evidence. Results across both benchmark datasets show that deepfake detectors offer limited standalone value, achieving F1 scores in the range of 0.26-0.53 on MMFakeBench and 0.33-0.49 on DGM4, and that incorporating their predictions into fact-checking pipelines consistently reduces performance by 0.04-0.08 F1 due to non-causal authenticity assumptions. In contrast, the evidence-centric fact-checking system achieves the highest performance, reaching F1 scores of approximately 0.81 on MMFakeBench and 0.55 on DGM4. Overall, our findings demonstrate that multimodal claim verification is driven primarily by semantic understanding and external evidence, and that pixel-level artifact signals do not reliably enhance reasoning over real-world image-text misinformation.