Seeing Is Believing? A Benchmark for Multimodal Large Language Models on Visual Illusions and Anomalies
作者: Wenjin Hou, Wei Liu, Han Hu, Xiaoxiao Sun, Serena Yeung-Levy, Hehe Fan
分类: cs.CV
发布日期: 2026-02-02
💡 一句话要点
VIA-Bench:提出视觉错觉与异常基准测试,揭示多模态大语言模型的感知脆弱性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉错觉 视觉异常 基准测试 鲁棒性 视觉推理 感知能力
📋 核心要点
- 现有MLLM在标准数据集上表现出色,但在面对违反常识的视觉错觉和异常时,其鲁棒性有待考察。
- VIA-Bench基准测试通过构建包含多种视觉错觉和异常的问答对,来评估MLLM的感知能力。
- 实验表明,即使是CoT推理也无法显著提升MLLM在视觉错觉上的表现,揭示了机器感知的局限性。
📝 摘要(中文)
多模态大语言模型(MLLMs)在通用视觉-语言基准测试中表现出卓越的性能,甚至达到或超过人类水平。然而,这些评估通常依赖于标准的同分布数据,当面对违反常识先验的场景时,MLLMs的鲁棒性在很大程度上未被检验。为了弥补这一差距,我们引入了VIA-Bench,这是一个具有挑战性的基准,旨在探测模型在视觉错觉和异常上的性能。它包括六个核心类别:颜色错觉、运动错觉、格式塔错觉、几何和空间错觉、一般视觉错觉和视觉异常。通过细致的人工循环审查,我们构建了超过1K个高质量的问答对,这些问答对需要细致的视觉推理。对包括专有模型、开源模型和推理增强模型在内的20多个最先进的MLLM进行了广泛的评估,揭示了显著的脆弱性。值得注意的是,我们发现思维链(CoT)推理提供的鲁棒性可以忽略不计,通常会产生“脆弱的海市蜃楼”,即模型的逻辑在错觉刺激下崩溃。我们的发现揭示了机器和人类感知之间存在根本差异,表明解决这些感知瓶颈对于通用人工智能的进步至关重要。基准数据和代码将会发布。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)在处理视觉错觉和异常时的鲁棒性问题。现有MLLMs在标准视觉-语言基准测试中表现良好,但这些测试主要集中在同分布数据上,忽略了模型在面对违反常识的视觉刺激时的表现。因此,现有方法无法有效评估和提升MLLMs在复杂视觉场景下的感知能力。
核心思路:论文的核心思路是构建一个专门用于评估MLLMs在视觉错觉和异常上表现的基准测试集VIA-Bench。通过设计包含多种类型视觉错觉和异常的问答对,来考察模型是否能够正确理解和推理这些具有挑战性的视觉信息。这种方法能够更全面地评估MLLMs的视觉感知能力,并揭示其在处理复杂视觉场景时的局限性。
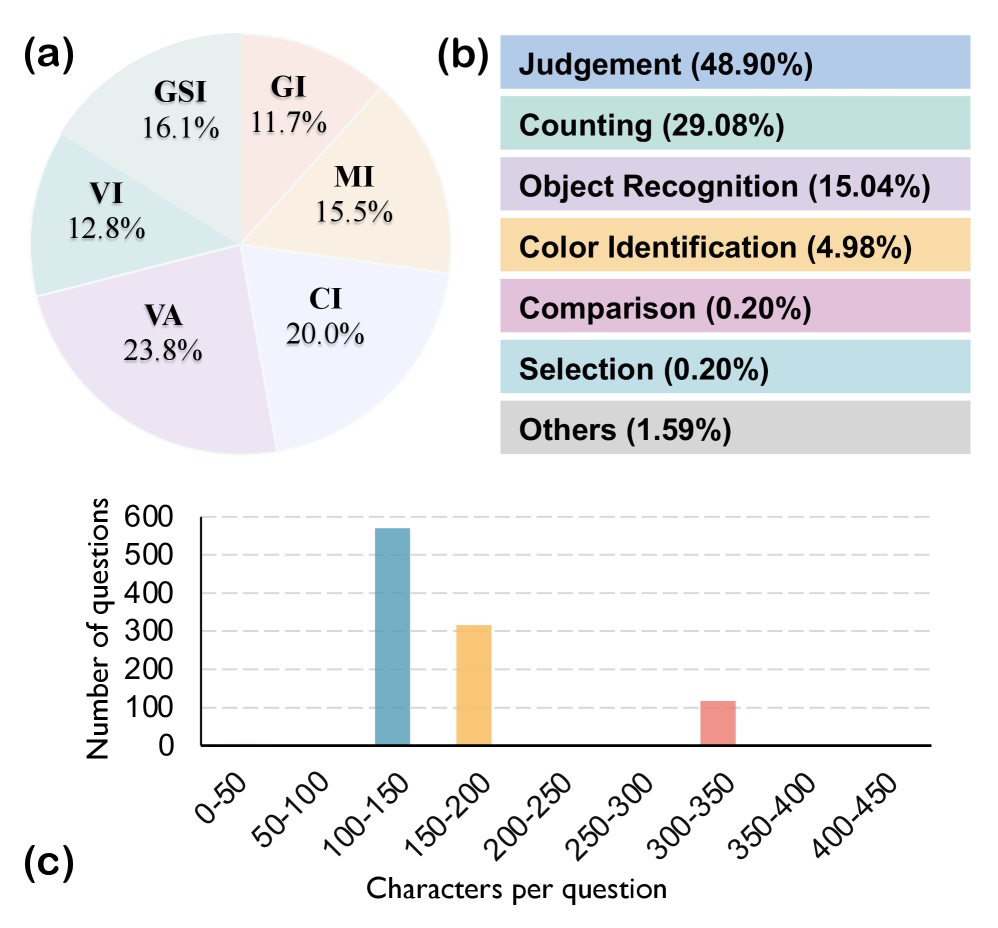
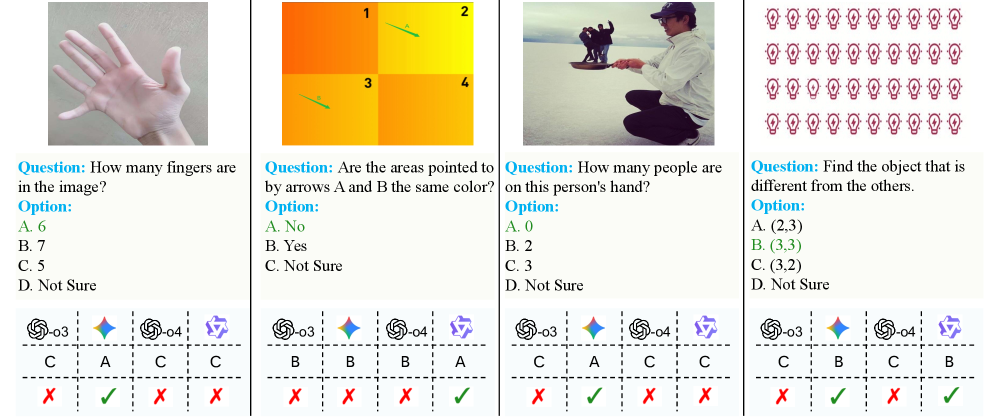
技术框架:VIA-Bench基准测试包含以下几个主要组成部分:1) 六个核心类别:颜色错觉、运动错觉、格式塔错觉、几何和空间错觉、一般视觉错觉和视觉异常。2) 超过1K个高质量的问答对,这些问答对需要细致的视觉推理。3) 评估流程:对MLLMs在VIA-Bench上的表现进行评估,并分析其在不同类型的视觉错觉和异常上的表现。4) 分析工具:提供用于分析模型表现的工具,例如错误分析和可视化。
关键创新:该论文的关键创新在于构建了一个专门用于评估MLLMs在视觉错觉和异常上表现的基准测试集VIA-Bench。与现有的视觉-语言基准测试相比,VIA-Bench更加关注模型的感知能力,能够更全面地评估MLLMs在处理复杂视觉场景时的表现。此外,论文还发现,即使是CoT推理也无法显著提升MLLMs在视觉错觉上的表现,这揭示了机器感知的局限性。
关键设计:VIA-Bench的关键设计包括:1) 多样化的视觉错觉和异常类型,涵盖了颜色、运动、格式塔、几何、空间等多个方面。2) 高质量的问答对,这些问答对需要细致的视觉推理,能够有效区分模型的感知能力。3) 人工循环审查,确保问答对的质量和准确性。4) 针对MLLMs的评估流程,能够全面评估模型在不同类型的视觉错觉和异常上的表现。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是最先进的MLLMs在VIA-Bench上的表现也远低于人类水平,揭示了机器感知的局限性。此外,研究发现,CoT推理对提升模型在视觉错觉上的表现几乎没有帮助,这表明现有的推理方法无法有效解决感知问题。该研究对20多个MLLM进行了评估,提供了全面的性能对比。
🎯 应用场景
该研究成果可应用于提升机器人、自动驾驶等领域中AI系统的感知能力。通过在VIA-Bench上训练和评估模型,可以提高AI系统对复杂和异常视觉信息的理解能力,从而增强其在真实世界场景中的鲁棒性和可靠性。未来,该研究还可以促进对人类视觉感知的更深入理解。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have shown remarkable proficiency on general-purpose vision-language benchmarks, reaching or even exceeding human-level performance. However, these evaluations typically rely on standard in-distribution data, leaving the robustness of MLLMs largely unexamined when faced with scenarios that defy common-sense priors. To address this gap, we introduce VIA-Bench, a challenging benchmark designed to probe model performance on visual illusions and anomalies. It includes six core categories: color illusions, motion illusions, gestalt illusions, geometric and spatial illusions, general visual illusions, and visual anomalies. Through careful human-in-the-loop review, we construct over 1K high-quality question-answer pairs that require nuanced visual reasoning. Extensive evaluation of over 20 state-of-the-art MLLMs, including proprietary, open-source, and reasoning-enhanced models, uncovers significant vulnerabilities. Notably, we find that Chain-of-Thought (CoT) reasoning offers negligible robustness, often yielding ``brittle mirages'' where the model's logic collapses under illusory stimuli. Our findings reveal a fundamental divergence between machine and human perception, suggesting that resolving such perceptual bottlenecks is critical for the advancement of artificial general intelligence. The benchmark data and code will be released.