Fast Autoregressive Video Diffusion and World Models with Temporal Cache Compression and Sparse Attention
作者: Dvir Samuel, Issar Tzachor, Matan Levy, Micahel Green, Gal Chechik, Rami Ben-Ari
分类: cs.CV, cs.AI
发布日期: 2026-02-02
备注: Project Page: https://dvirsamuel.github.io/fast-auto-regressive-video/
💡 一句话要点
提出TempCache、AnnCA和AnnSA,加速自回归视频扩散模型推理并降低显存占用。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自回归视频扩散 视频生成 注意力机制 模型加速 显存优化
📋 核心要点
- 自回归视频扩散模型推理时,注意力层的KV缓存增长迅速,导致延迟增加和显存占用过高,限制了长视频生成。
- 论文提出TempCache、AnnCA和AnnSA三个模块,分别压缩KV缓存、加速交叉注意力和稀疏化自注意力,降低计算和内存需求。
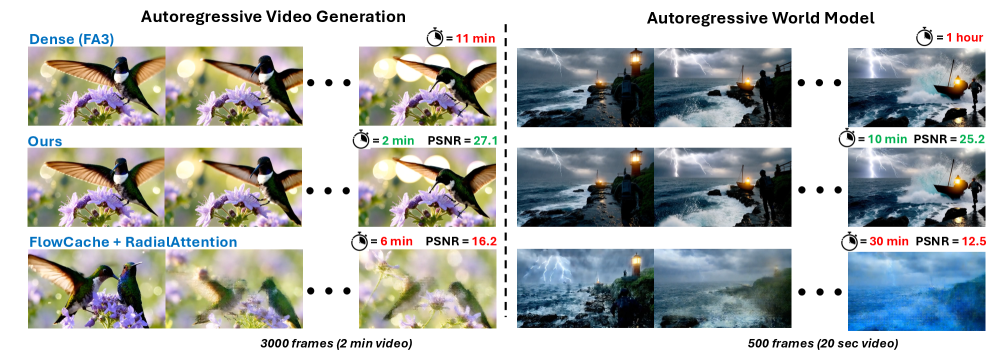
- 实验表明,该方法在保持视觉质量的同时,显著提高了推理速度(5-10倍)并稳定了GPU内存占用,尤其是在长视频生成中。
📝 摘要(中文)
自回归视频扩散模型支持流式生成,为长视频合成、视频世界模型和交互式神经游戏引擎开辟了道路。然而,其核心注意力层在推理时成为主要瓶颈:随着生成过程的进行,KV缓存不断增长,导致延迟增加和GPU内存消耗加剧,进而限制了可用的时间上下文并损害了长程一致性。本文研究了自回归视频扩散中的冗余,并确定了三个持续存在的来源:跨帧的近重复缓存键、缓慢演变的(很大程度上是语义的)查询/键导致许多注意力计算变得冗余,以及长提示上的交叉注意力,其中每帧只有一小部分token重要。基于这些观察,我们提出了一个统一的、免训练的自回归扩散注意力框架:TempCache通过时间对应关系压缩KV缓存以限制缓存增长;AnnCA通过使用快速近似最近邻(ANN)匹配选择帧相关的提示token来加速交叉注意力;AnnSA通过将每个查询限制为语义匹配的键来稀疏化自注意力,也使用轻量级ANN。这些模块共同减少了注意力计算、计算量和内存,并且与现有的自回归扩散骨干网络和世界模型兼容。实验表明,端到端速度提高了5到10倍,同时保持了几乎相同的视觉质量,并且至关重要的是,在长rollout中保持了稳定的吞吐量和几乎恒定的峰值GPU内存使用率,而先前的方法逐渐减慢速度并遭受越来越多的内存使用。
🔬 方法详解
问题定义:自回归视频扩散模型在推理阶段,随着生成帧数的增加,注意力机制中的KV缓存会不断增长,导致计算量和显存占用线性增加。这使得长视频生成变得非常耗时且对硬件要求高,限制了其在实际应用中的可行性。现有方法难以在保证生成质量的同时,有效降低计算和内存开销。
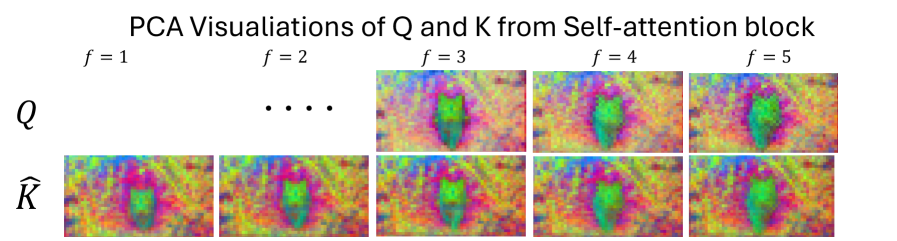
核心思路:论文的核心思路是利用视频帧之间的时间相关性和语义相似性,减少注意力计算中的冗余。具体来说,通过压缩KV缓存、选择关键的prompt token和稀疏化自注意力,降低计算量和内存占用,从而加速推理过程。
技术框架:该方法包含三个主要模块:TempCache、AnnCA和AnnSA。TempCache通过时间对应关系压缩KV缓存,减少缓存大小。AnnCA利用近似最近邻搜索(ANN)选择与当前帧相关的prompt token,加速交叉注意力计算。AnnSA也使用ANN来稀疏化自注意力,只关注语义上相关的键。这三个模块可以集成到现有的自回归扩散模型中。
关键创新:该方法的主要创新在于提出了一个统一的、免训练的注意力框架,能够同时解决自回归视频扩散模型中KV缓存增长、交叉注意力计算冗余和自注意力计算冗余的问题。与现有方法相比,该方法不需要重新训练模型,并且能够显著提高推理速度和降低显存占用。
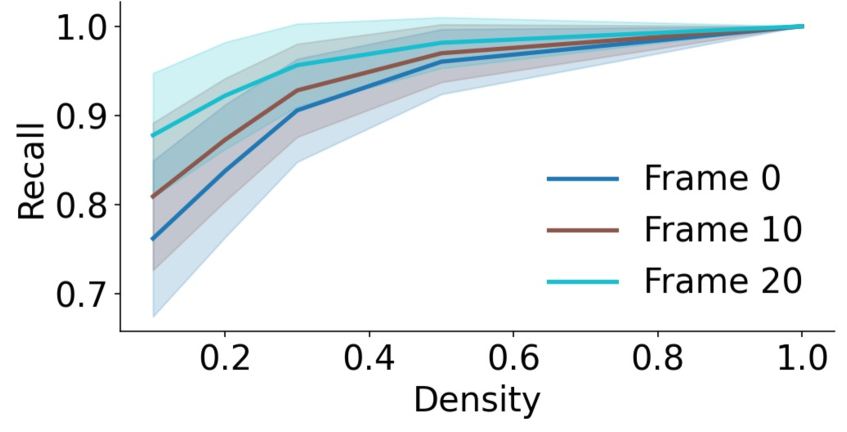
关键设计:TempCache的关键设计在于利用光流等方法估计帧间运动,从而找到时间对应的特征,并只保留具有代表性的特征。AnnCA和AnnSA的关键设计在于使用近似最近邻搜索(ANN)来快速找到语义上相关的token,从而减少注意力计算的范围。这些模块的设计都非常轻量级,不会引入额外的计算负担。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在保持视觉质量几乎不变的情况下,端到端速度提高了5到10倍。更重要的是,该方法在长rollout中保持了稳定的吞吐量和几乎恒定的峰值GPU内存使用率,而先前的方法逐渐减慢速度并遭受越来越多的内存使用。这些结果表明,该方法能够有效解决自回归视频扩散模型在长视频生成中的计算和内存瓶颈。
🎯 应用场景
该研究成果可应用于长视频生成、视频世界模型、交互式神经游戏引擎等领域。通过降低计算和内存需求,使得自回归视频扩散模型能够在资源受限的设备上运行,并支持更长的视频生成,从而拓展了其应用范围和实际价值。未来可能应用于视频编辑、虚拟现实、游戏开发等领域。
📄 摘要(原文)
Autoregressive video diffusion models enable streaming generation, opening the door to long-form synthesis, video world models, and interactive neural game engines. However, their core attention layers become a major bottleneck at inference time: as generation progresses, the KV cache grows, causing both increasing latency and escalating GPU memory, which in turn restricts usable temporal context and harms long-range consistency. In this work, we study redundancy in autoregressive video diffusion and identify three persistent sources: near-duplicate cached keys across frames, slowly evolving (largely semantic) queries/keys that make many attention computations redundant, and cross-attention over long prompts where only a small subset of tokens matters per frame. Building on these observations, we propose a unified, training-free attention framework for autoregressive diffusion: TempCache compresses the KV cache via temporal correspondence to bound cache growth; AnnCA accelerates cross-attention by selecting frame-relevant prompt tokens using fast approximate nearest neighbor (ANN) matching; and AnnSA sparsifies self-attention by restricting each query to semantically matched keys, also using a lightweight ANN. Together, these modules reduce attention, compute, and memory and are compatible with existing autoregressive diffusion backbones and world models. Experiments demonstrate up to x5--x10 end-to-end speedups while preserving near-identical visual quality and, crucially, maintaining stable throughput and nearly constant peak GPU memory usage over long rollouts, where prior methods progressively slow down and suffer from increasing memory usage.