FreshMem: Brain-Inspired Frequency-Space Hybrid Memory for Streaming Video Understanding
作者: Kangcong Li, Peng Ye, Lin Zhang, Chao Wang, Huafeng Qin, Tao Chen
分类: cs.CV, cs.AI
发布日期: 2026-02-02
💡 一句话要点
FreshMem:面向流式视频理解的脑启发频率-空间混合记忆网络
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 流式视频理解 多模态大语言模型 频率域分析 空间记忆 脑启发计算 长时程记忆 自适应压缩
📋 核心要点
- 现有流式视频理解方法缺乏灵活的适应性,导致不可逆的细节丢失和上下文碎片化。
- FreshMem受大脑记忆机制启发,利用频率域和空间域的混合记忆,兼顾短期细节保真和长期上下文连贯。
- 实验表明,FreshMem在多个流式视频理解基准测试中显著提升了性能,且无需训练,优于部分微调方法。
📝 摘要(中文)
为了使多模态大语言模型(MLLMs)从离线过渡到在线流式视频理解,实现连续感知,本文提出了FreshMem,一种受大脑对数感知和记忆巩固启发的频率-空间混合记忆网络。FreshMem通过两个协同模块协调短期保真度和长期连贯性:多尺度频率记忆(MFM),将溢出的帧投影到代表性的频率系数中,并辅以残差细节以重建全局历史“概要”;以及空间缩略图记忆(STM),通过采用自适应压缩策略将连续流离散化为情景簇,并将它们提炼成高密度空间缩略图。大量实验表明,FreshMem显著提升了Qwen2-VL基线,在StreamingBench、OV-Bench和OVO-Bench上分别获得了5.20%、4.52%和2.34%的增益。作为一个免训练的解决方案,FreshMem优于几种完全微调的方法,为长时程流式视频理解提供了一种高效的范例。
🔬 方法详解
问题定义:论文旨在解决流式视频理解中,多模态大语言模型(MLLMs)从离线到在线过渡时面临的细节丢失和上下文碎片化问题。现有方法缺乏灵活的适应性,无法有效处理长时程的视频流,导致重要信息丢失,影响理解效果。
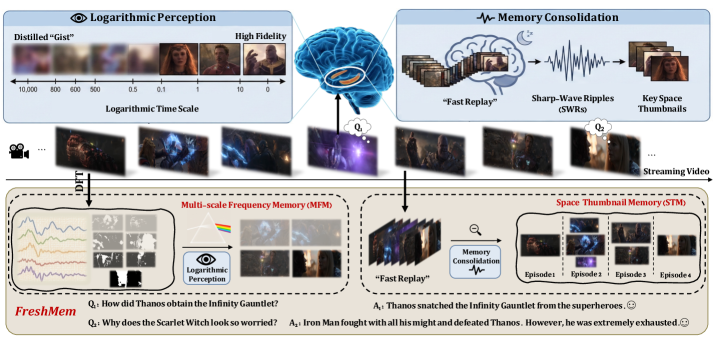
核心思路:论文的核心思路是模仿大脑的记忆机制,构建一个混合记忆网络,利用频率域和空间域的互补特性,实现对视频流的有效压缩和长期记忆。频率域擅长捕捉全局信息,空间域则保留细节信息。通过结合两者,可以兼顾短期保真度和长期连贯性。
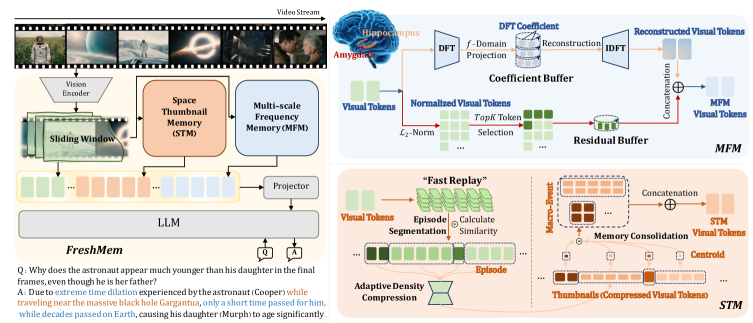
技术框架:FreshMem包含两个主要模块:多尺度频率记忆(MFM)和空间缩略图记忆(STM)。MFM将溢出的帧转换为频率系数,保留全局信息,并通过残差细节补充局部信息。STM将连续视频流离散化为情景簇,并压缩成高密度空间缩略图,用于长期记忆。这两个模块协同工作,共同完成流式视频的理解任务。整体流程是:视频帧输入 -> MFM (频率域压缩) -> STM (空间域压缩) -> MLLM (视频理解)。
关键创新:论文的关键创新在于提出了频率-空间混合记忆的架构,并将其应用于流式视频理解。与现有方法相比,FreshMem能够更有效地压缩视频信息,同时保留重要的细节和上下文信息。此外,FreshMem是一个免训练的解决方案,可以直接应用于现有的MLLM,无需额外的训练成本。
关键设计:MFM使用多尺度分析来提取不同频率的特征,并使用残差连接来保留细节信息。STM采用自适应压缩策略,根据视频内容的复杂程度动态调整压缩比例。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FreshMem显著提升了Qwen2-VL基线在StreamingBench、OV-Bench和OVO-Bench三个流式视频理解基准测试上的性能,分别获得了5.20%、4.52%和2.34%的增益。更重要的是,作为一个免训练的解决方案,FreshMem优于几种完全微调的方法,证明了其高效性和有效性。
🎯 应用场景
FreshMem具有广泛的应用前景,例如智能监控、自动驾驶、视频会议、在线教育等需要实时视频理解的领域。它可以帮助系统更好地理解视频内容,从而做出更准确的决策和响应。该研究的成果有助于推动多模态大语言模型在实际场景中的应用,并为未来的流式视频理解研究提供新的思路。
📄 摘要(原文)
Transitioning Multimodal Large Language Models (MLLMs) from offline to online streaming video understanding is essential for continuous perception. However, existing methods lack flexible adaptivity, leading to irreversible detail loss and context fragmentation. To resolve this, we propose FreshMem, a Frequency-Space Hybrid Memory network inspired by the brain's logarithmic perception and memory consolidation. FreshMem reconciles short-term fidelity with long-term coherence through two synergistic modules: Multi-scale Frequency Memory (MFM), which projects overflowing frames into representative frequency coefficients, complemented by residual details to reconstruct a global historical "gist"; and Space Thumbnail Memory (STM), which discretizes the continuous stream into episodic clusters by employing an adaptive compression strategy to distill them into high-density space thumbnails. Extensive experiments show that FreshMem significantly boosts the Qwen2-VL baseline, yielding gains of 5.20%, 4.52%, and 2.34% on StreamingBench, OV-Bench, and OVO-Bench, respectively. As a training-free solution, FreshMem outperforms several fully fine-tuned methods, offering a highly efficient paradigm for long-horizon streaming video understanding.