Contribution-aware Token Compression for Efficient Video Understanding via Reinforcement Learning
作者: Yinchao Ma, Qiang Zhou, Zhibin Wang, Xianing Chen, Hanqing Yang, Jun Song, Bo Zheng
分类: cs.CV, cs.AI
发布日期: 2026-02-02
备注: This paper is accepted by AAAI2026
💡 一句话要点
提出CaCoVID,通过强化学习进行贡献感知的Token压缩,提升视频理解效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 Token压缩 强化学习 策略优化 计算效率
📋 核心要点
- 现有视频理解模型token冗余导致计算开销大,且注意力分数与token实际贡献的相关性不明确。
- CaCoVID通过强化学习优化token选择策略,主动发现对正确预测贡献最大的token组合。
- 提出的组合策略优化算法,通过在线采样减少探索空间,加速策略收敛,实验证明其有效性。
📝 摘要(中文)
视频大语言模型在视频理解任务中表现出卓越的能力。然而,视频token的冗余在推理过程中引入了显著的计算开销,限制了它们的实际部署。许多压缩算法被提出,以优先保留具有最高注意力分数的特征,从而最小化注意力计算中的扰动。然而,注意力分数与其对正确答案的实际贡献之间的相关性仍然不明确。为了解决上述限制,我们提出了一种新颖的贡献感知token压缩算法CaCoVID,用于视频理解,该算法基于token对正确预测的贡献显式地优化token选择策略。首先,我们引入了一个基于强化学习的框架,该框架优化一个策略网络,以选择对正确预测具有最大贡献的视频token组合。这种范式将重点从被动的token保留转移到主动发现最佳压缩token组合。其次,我们提出了一种具有在线组合空间采样的组合策略优化算法,该算法显著减少了视频token组合的探索空间,并加速了策略优化的收敛速度。在各种视频理解基准上的大量实验证明了CaCoVID的有效性。
🔬 方法详解
问题定义:视频理解任务中,现有方法依赖注意力分数进行token压缩,但注意力分数与token对最终预测结果的实际贡献度关联性弱,导致压缩后的模型性能下降。此外,直接搜索最佳token组合的计算复杂度过高,难以实现高效的token压缩。
核心思路:CaCoVID的核心在于使用强化学习来显式地学习一个token选择策略,该策略能够选择对最终预测结果贡献最大的token组合。通过奖励机制,鼓励策略选择对正确预测有益的token,避免了仅依赖注意力分数的局限性。
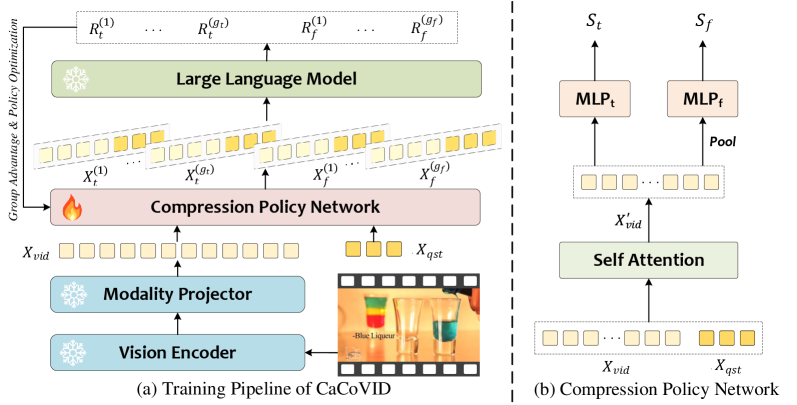
技术框架:CaCoVID包含一个策略网络和一个强化学习训练框架。策略网络接收视频token作为输入,输出每个token被选择的概率。强化学习框架使用策略梯度方法,根据模型在验证集上的表现来更新策略网络。具体来说,模型首先根据策略网络选择一个token子集,然后使用该子集进行视频理解任务的预测。根据预测结果与真实标签的差异,计算奖励信号,并使用该奖励信号来更新策略网络。
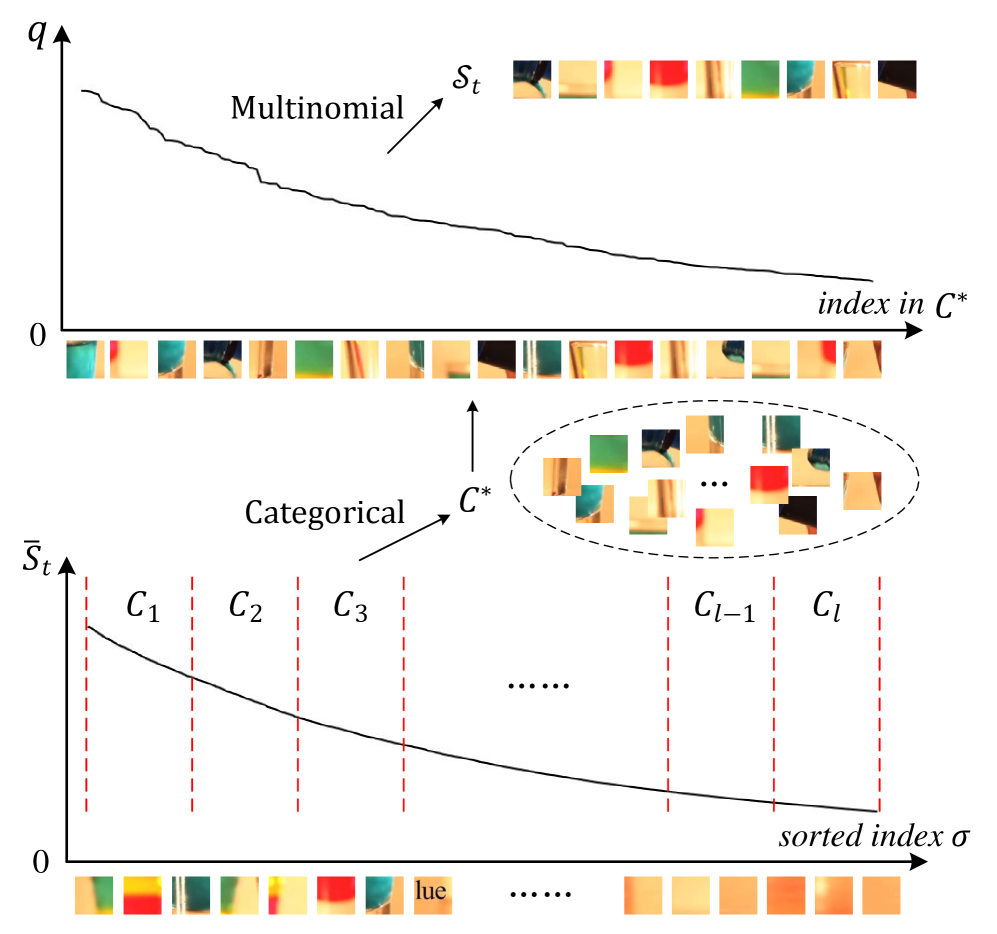
关键创新:CaCoVID的关键创新在于将token压缩问题建模为一个强化学习问题,并设计了相应的奖励函数和策略优化算法。与传统的基于注意力分数的压缩方法相比,CaCoVID能够更准确地评估token对最终预测结果的贡献,从而选择更有效的token组合。此外,提出的在线组合空间采样方法,显著降低了搜索空间,提高了训练效率。
关键设计:CaCoVID使用策略梯度算法进行训练,奖励函数的设计至关重要。奖励函数综合考虑了预测的准确性和token的数量,鼓励策略选择尽可能少的token,同时保持较高的预测准确率。策略网络可以使用各种神经网络结构,例如多层感知机或循环神经网络。在线组合空间采样通过限制每次迭代中探索的token组合数量,降低了计算复杂度。
🖼️ 关键图片

📊 实验亮点
CaCoVID在多个视频理解基准测试中取得了显著的性能提升。例如,在Something-Something V2数据集上,CaCoVID在保持相似准确率的情况下,可以将token数量减少到原来的50%。与其他token压缩方法相比,CaCoVID在压缩率和准确率之间取得了更好的平衡。
🎯 应用场景
CaCoVID可应用于各种视频理解任务,如视频分类、动作识别、视频问答等。通过减少视频token的数量,可以显著降低计算开销,使得视频理解模型能够在资源受限的设备上部署,例如移动设备和嵌入式系统。此外,该方法还可以用于加速视频检索和视频摘要等应用。
📄 摘要(原文)
Video large language models have demonstrated remarkable capabilities in video understanding tasks. However, the redundancy of video tokens introduces significant computational overhead during inference, limiting their practical deployment. Many compression algorithms are proposed to prioritize retaining features with the highest attention scores to minimize perturbations in attention computations. However, the correlation between attention scores and their actual contribution to correct answers remains ambiguous. To address the above limitation, we propose a novel \textbf{C}ontribution-\textbf{a}ware token \textbf{Co}mpression algorithm for \textbf{VID}eo understanding (\textbf{CaCoVID}) that explicitly optimizes the token selection policy based on the contribution of tokens to correct predictions. First, we introduce a reinforcement learning-based framework that optimizes a policy network to select video token combinations with the greatest contribution to correct predictions. This paradigm shifts the focus from passive token preservation to active discovery of optimal compressed token combinations. Secondly, we propose a combinatorial policy optimization algorithm with online combination space sampling, which dramatically reduces the exploration space for video token combinations and accelerates the convergence speed of policy optimization. Extensive experiments on diverse video understanding benchmarks demonstrate the effectiveness of CaCoVID. Codes will be released.