Omni-Judge: Can Omni-LLMs Serve as Human-Aligned Judges for Text-Conditioned Audio-Video Generation?
作者: Susan Liang, Chao Huang, Filippos Bellos, Yolo Yunlong Tang, Qianxiang Shen, Jing Bi, Luchuan Song, Zeliang Zhang, Jason Corso, Chenliang Xu
分类: cs.CV
发布日期: 2026-02-02
💡 一句话要点
Omni-Judge:探索全模态LLM作为文本条件音视频生成的人类对齐评估器的潜力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全模态LLM 文本到音视频生成 自动评估 多模态对齐 可解释性 提示工程 多模态评估
📋 核心要点
- 现有文本到音视频生成模型的评估依赖人工或传统指标,前者成本高,后者缺乏对复杂语义的理解和可解释性。
- Omni-Judge利用全模态LLM同时处理音频、视频和文本,进行多模态推理,并提供可解释的评估反馈。
- 实验表明,Omni-Judge在语义对齐任务上表现出色,但在高时间分辨率的感知指标上存在局限性,未来有提升空间。
📝 摘要(中文)
随着Sora 2和Veo 3等先进的文本到视频生成模型能够直接从文本提示生成具有同步音频的高保真视频,多模态生成迎来了一个新的里程碑。然而,评估这种三模态输出仍然是一个未解决的挑战。人工评估是可靠的,但成本高昂且难以扩展,而传统的自动指标,如FVD、CLAP和ViCLIP,侧重于孤立的模态对,难以处理复杂的提示,并且提供的可解释性有限。全模态大型语言模型(omni-LLM)提供了一个有希望的替代方案:它们自然地处理音频、视频和文本,支持丰富的推理,并提供可解释的链式思考反馈。受此驱动,我们推出了Omni-Judge,一项评估omni-LLM是否可以作为文本条件音视频生成的人类对齐评估器的研究。在九个感知和对齐指标中,Omni-Judge实现了与传统指标相当的相关性,并在语义要求高的任务(如音频-文本对齐、视频-文本对齐和音频-视频-文本一致性)方面表现出色。由于时间分辨率有限,它在高FPS感知指标(包括视频质量和音频-视频同步)方面表现不佳。Omni-Judge提供了可解释的解释,揭示了语义或物理不一致性,从而实现了基于反馈的细化等实际下游应用。我们的研究结果突出了omni-LLM作为多模态生成的统一评估器的潜力和当前局限性。
🔬 方法详解
问题定义:当前文本条件音视频生成模型的评估方法存在局限性。人工评估成本高昂且难以扩展,而传统的自动评估指标(如FVD、CLAP、ViCLIP等)通常只关注模态对之间的关系,无法有效处理复杂语义的提示,并且缺乏可解释性,难以指导模型的改进。因此,如何设计一种能够有效、经济且可解释的评估方法是亟待解决的问题。
核心思路:论文的核心思路是利用全模态大型语言模型(Omni-LLM)作为评估器。Omni-LLM能够同时处理音频、视频和文本信息,具备强大的多模态推理能力和生成可解释反馈的能力。通过将生成的多模态内容输入Omni-LLM,并设计合适的提示工程,使其能够像人类评估者一样,对生成内容的质量和一致性进行判断。
技术框架:Omni-Judge的整体框架包括以下几个主要步骤:1) 数据准备:收集文本提示以及对应的生成音频-视频数据。2) 提示工程:设计针对不同评估指标(如音频-文本对齐、视频质量等)的提示语,引导Omni-LLM进行评估。3) 模型推理:将文本提示和生成的音视频数据输入Omni-LLM,并根据设计的提示语进行推理,得到评估结果和解释。4) 结果分析:将Omni-LLM的评估结果与人工评估结果以及传统评估指标进行对比,分析Omni-Judge的性能和局限性。
关键创新:该论文的关键创新在于将全模态LLM应用于文本条件音视频生成模型的评估任务。与传统的评估方法相比,Omni-Judge能够同时考虑音频、视频和文本信息,进行更全面的评估,并且能够提供可解释的评估反馈,有助于发现生成模型存在的问题。此外,Omni-Judge还探索了如何通过提示工程来引导Omni-LLM进行评估,为未来的研究提供了借鉴。
关键设计:论文中关键的设计包括:1) 提示语的设计:针对不同的评估指标,设计了不同的提示语,例如,对于音频-文本对齐,提示语会询问Omni-LLM音频内容是否与文本描述一致。2) 评估指标的选择:选择了九个具有代表性的感知和对齐指标,包括视频质量、音频质量、音频-视频同步、音频-文本对齐、视频-文本对齐、音频-视频-文本一致性等。3) 对比实验的设计:将Omni-Judge的评估结果与人工评估结果以及传统评估指标进行对比,以验证Omni-Judge的有效性。
🖼️ 关键图片


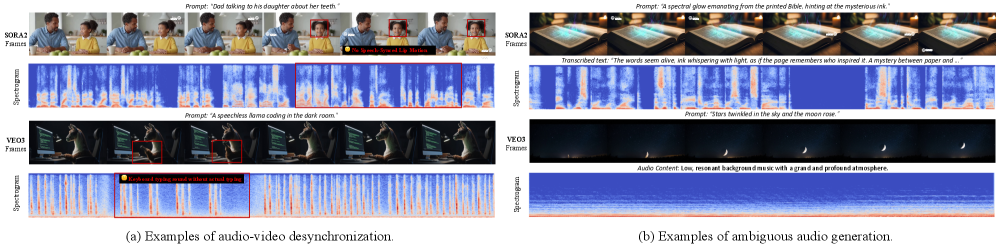
📊 实验亮点
Omni-Judge在音频-文本对齐、视频-文本对齐和音频-视频-文本一致性等语义任务上表现出色,与传统指标的相关性相当。尽管在高帧率感知指标上表现稍逊,但其提供的可解释性反馈为模型改进提供了方向。例如,Omni-Judge能够指出生成视频中存在的语义不一致性,为后续的优化提供指导。
🎯 应用场景
Omni-Judge可应用于文本到音视频生成模型的自动评估和优化,降低人工评估成本,加速模型迭代。其可解释的反馈能帮助开发者定位模型缺陷,提升生成质量。未来可扩展到其他多模态生成任务的评估,例如图像到视频、文本到3D内容生成等,推动多模态内容创作的发展。
📄 摘要(原文)
State-of-the-art text-to-video generation models such as Sora 2 and Veo 3 can now produce high-fidelity videos with synchronized audio directly from a textual prompt, marking a new milestone in multi-modal generation. However, evaluating such tri-modal outputs remains an unsolved challenge. Human evaluation is reliable but costly and difficult to scale, while traditional automatic metrics, such as FVD, CLAP, and ViCLIP, focus on isolated modality pairs, struggle with complex prompts, and provide limited interpretability. Omni-modal large language models (omni-LLMs) present a promising alternative: they naturally process audio, video, and text, support rich reasoning, and offer interpretable chain-of-thought feedback. Driven by this, we introduce Omni-Judge, a study assessing whether omni-LLMs can serve as human-aligned judges for text-conditioned audio-video generation. Across nine perceptual and alignment metrics, Omni-Judge achieves correlation comparable to traditional metrics and excels on semantically demanding tasks such as audio-text alignment, video-text alignment, and audio-video-text coherence. It underperforms on high-FPS perceptual metrics, including video quality and audio-video synchronization, due to limited temporal resolution. Omni-Judge provides interpretable explanations that expose semantic or physical inconsistencies, enabling practical downstream uses such as feedback-based refinement. Our findings highlight both the potential and current limitations of omni-LLMs as unified evaluators for multi-modal generation.