Samba+: General and Accurate Salient Object Detection via A More Unified Mamba-based Framework
作者: Wenzhuo Zhao, Keren Fu, Jiahao He, Xiaohong Liu, Qijun Zhao, Guangtao Zhai
分类: cs.CV
发布日期: 2026-02-02
💡 一句话要点
提出Samba+,一个基于Mamba的通用显著性目标检测框架,适用于多种SOD任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 显著性目标检测 Mamba架构 多模态融合 持续学习 状态空间模型
📋 核心要点
- 现有SOD模型受限于CNN的感受野和Transformer的计算复杂度,难以兼顾全局信息和效率。
- Samba引入显著性引导的Mamba块(SGMB)和上下文感知的上采样(CAU),优化Mamba在SOD任务中的应用。
- Samba+通过多任务联合训练和跨模态融合,实现了在多种SOD任务上的优越性能,并降低了计算成本。
📝 摘要(中文)
现有的显著性目标检测(SOD)模型通常受限于卷积神经网络(CNN)有限的感受野和Transformer的二次计算复杂度。最近,新兴的状态空间模型Mamba在平衡全局感受野和计算效率方面显示出巨大潜力。作为解决方案,我们提出了Saliency Mamba (Samba),一个纯粹基于Mamba的架构,可以灵活地处理各种不同的SOD任务,包括RGB/RGB-D/RGB-T SOD、视频SOD (VSOD)、RGB-D VSOD和可见光-深度-热SOD。具体来说,我们重新思考了Mamba在SOD中的扫描策略,并引入了显著性引导的Mamba块(SGMB),该块具有空间邻域扫描(SNS)算法,以保持显著区域的空间连续性。还提出了一种上下文感知的上采样(CAU)方法,通过建模上下文依赖关系来促进分层特征对齐和聚合。更进一步,为了避免先前SOD解决方案中的“特定于任务”问题,我们开发了Samba+,它通过以多任务联合方式训练Samba来增强,从而产生更统一和通用的模型。研究了两个关键组件,它们协同解决任意模态输入和持续适应中遇到的挑战。具体来说,hub-and-spoke图注意力(HGA)模块促进了自适应跨模态交互融合,而模态锚定的持续学习(MACL)策略缓解了模态间冲突以及灾难性遗忘。大量的实验表明,Samba在六个SOD任务的22个数据集上优于现有方法,且计算成本更低,而Samba+通过使用单个训练的通用模型在这些任务和数据集上实现了更优越的结果。其他结果进一步证明了我们的Samba框架的潜力。
🔬 方法详解
问题定义:现有显著性目标检测方法通常依赖于CNN或Transformer,前者感受野有限,后者计算复杂度高。此外,许多方法是针对特定任务设计的,缺乏通用性,难以处理多种模态的输入和持续学习的问题。
核心思路:论文的核心思路是利用Mamba架构的优势,即在保持全局感受野的同时具有较低的计算复杂度。通过改进Mamba的扫描策略,并结合显著性引导和上下文感知机制,提升模型在SOD任务中的性能。同时,采用多任务联合训练和跨模态融合策略,增强模型的通用性和适应性。
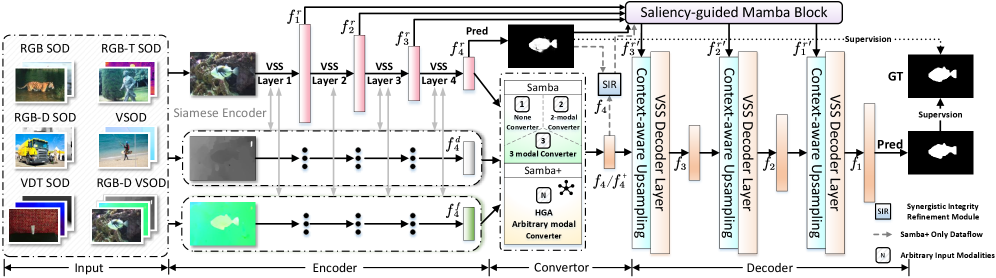
技术框架:Samba框架主要由以下几个部分组成:1) 基于Mamba的编码器,用于提取多模态输入特征;2) 显著性引导的Mamba块(SGMB),用于保持显著区域的空间连续性;3) 上下文感知的上采样(CAU),用于促进分层特征对齐和聚合;4) hub-and-spoke图注意力(HGA)模块,用于自适应跨模态交互融合;5) 模态锚定的持续学习(MACL)策略,用于缓解模态间冲突和灾难性遗忘。Samba+在Samba的基础上,通过多任务联合训练和跨模态融合,实现了更通用的显著性目标检测。
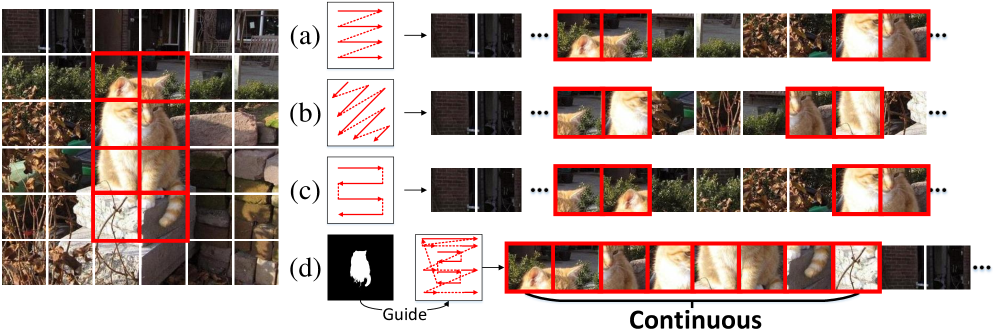
关键创新:论文的关键创新点在于:1) 提出了显著性引导的Mamba块(SGMB),通过空间邻域扫描(SNS)算法,更好地保持了显著区域的空间连续性;2) 提出了上下文感知的上采样(CAU),通过建模上下文依赖关系,促进了分层特征的对齐和聚合;3) 提出了hub-and-spoke图注意力(HGA)模块和模态锚定的持续学习(MACL)策略,解决了多模态输入和持续学习中的挑战。
关键设计:SGMB中的SNS算法具体实现未知。CAU的具体实现细节未知。HGA模块和MACL策略的具体参数设置和损失函数未知。Mamba块的具体配置,如状态空间维度、选择机制等未知。
🖼️ 关键图片
📊 实验亮点
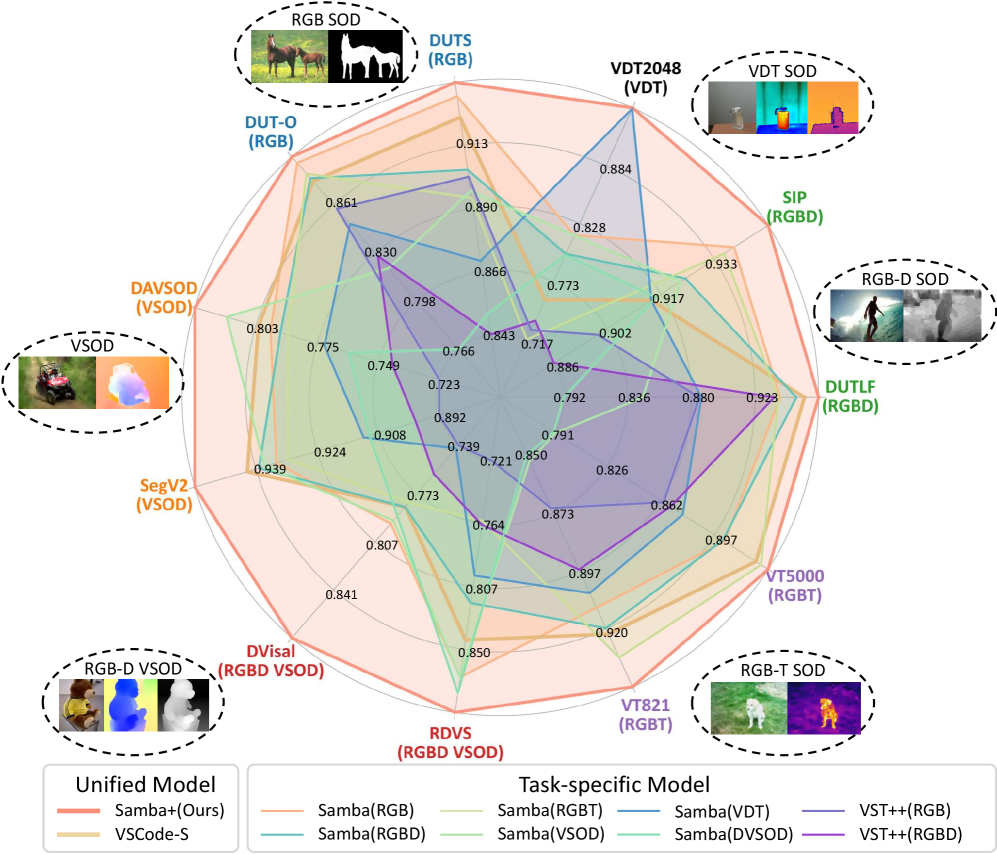
Samba在六个SOD任务的22个数据集上优于现有方法,且计算成本更低。Samba+通过使用单个训练的通用模型在这些任务和数据集上实现了更优越的结果。具体性能提升数据未知,但强调了Samba和Samba+在效率和精度上的优势。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、医学图像分析、机器人视觉等领域。通过快速准确地检测图像中的显著性目标,可以提升系统的感知能力和决策效率,例如在自动驾驶中快速识别行人、车辆等关键目标,或在医学图像中辅助医生诊断病灶。
📄 摘要(原文)
Existing salient object detection (SOD) models are generally constrained by the limited receptive fields of convolutional neural networks (CNNs) and quadratic computational complexity of Transformers. Recently, the emerging state-space model, namely Mamba, has shown great potential in balancing global receptive fields and computational efficiency. As a solution, we propose Saliency Mamba (Samba), a pure Mamba-based architecture that flexibly handles various distinct SOD tasks, including RGB/RGB-D/RGB-T SOD, video SOD (VSOD), RGB-D VSOD, and visible-depth-thermal SOD. Specifically, we rethink the scanning strategy of Mamba for SOD, and introduce a saliency-guided Mamba block (SGMB) that features a spatial neighborhood scanning (SNS) algorithm to preserve the spatial continuity of salient regions. A context-aware upsampling (CAU) method is also proposed to promote hierarchical feature alignment and aggregation by modeling contextual dependencies. As one step further, to avoid the "task-specific" problem as in previous SOD solutions, we develop Samba+, which is empowered by training Samba in a multi-task joint manner, leading to a more unified and versatile model. Two crucial components that collaboratively tackle challenges encountered in input of arbitrary modalities and continual adaptation are investigated. Specifically, a hub-and-spoke graph attention (HGA) module facilitates adaptive cross-modal interactive fusion, and a modality-anchored continual learning (MACL) strategy alleviates inter-modal conflicts together with catastrophic forgetting. Extensive experiments demonstrate that Samba individually outperforms existing methods across six SOD tasks on 22 datasets with lower computational cost, whereas Samba+ achieves even superior results on these tasks and datasets by using a single trained versatile model. Additional results further demonstrate the potential of our Samba framework.