HandMCM: Multi-modal Point Cloud-based Correspondence State Space Model for 3D Hand Pose Estimation
作者: Wencan Cheng, Gim Hee Lee
分类: cs.CV
发布日期: 2026-02-02
备注: AAAI accepted
💡 一句话要点
提出HandMCM,利用多模态点云和Correspondence Mamba解决3D手部姿态估计中的遮挡问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D手部姿态估计 点云 多模态融合 状态空间模型 Mamba 遮挡处理 人机交互
📋 核心要点
- 3D手部姿态估计面临手部自遮挡和与物体交互遮挡的挑战,现有方法难以准确估计关键点位置。
- HandMCM利用Correspondence Mamba学习关键点间的动态拓扑关系,并融合多模态特征增强鲁棒性。
- 实验表明,HandMCM在三个基准数据集上显著优于现有方法,尤其在严重遮挡场景下提升明显。
📝 摘要(中文)
本文提出了一种名为HandMCM的新方法,用于解决3D手部姿态估计中因手部自遮挡和与物体交互造成的遮挡问题。HandMCM基于强大的状态空间模型(Mamba),通过结合局部信息注入/过滤模块和对应关系建模,有效地学习了关键点在各种遮挡场景下的高度动态的运动学拓扑结构。此外,通过整合多模态图像特征,增强了输入的鲁棒性和表征能力,从而实现了更准确的手部姿态估计。在三个基准数据集上的实验评估表明,我们的模型显著优于当前最先进的方法,尤其是在涉及严重遮挡的具有挑战性的场景中。这些结果突出了我们的方法在提高实际应用中3D手部姿态估计的准确性和可靠性方面的潜力。
🔬 方法详解
问题定义:论文旨在解决3D手部姿态估计中,由于手部自遮挡以及与物体交互产生的遮挡问题,导致关键点定位不准确的难题。现有方法在处理复杂遮挡场景时,往往难以有效建模关键点之间的依赖关系,鲁棒性较差。
核心思路:论文的核心思路是利用状态空间模型Mamba强大的序列建模能力,结合局部信息处理和对应关系建模,学习关键点之间动态的运动学拓扑结构。同时,通过融合多模态图像特征,增强模型对遮挡的鲁棒性和表征能力。
技术框架:HandMCM的整体框架包含以下几个主要模块:1) 多模态特征提取模块,用于提取点云和图像等多模态输入特征;2) 局部信息注入/过滤模块,用于增强局部信息的表达和过滤噪声;3) Correspondence Mamba模块,用于建模关键点之间的对应关系和动态拓扑结构;4) 姿态回归模块,用于预测3D手部关键点坐标。
关键创新:论文的关键创新在于提出了Correspondence Mamba模块,该模块能够有效地学习关键点在各种遮挡场景下的动态拓扑结构。与传统的基于图卷积网络的方法相比,Correspondence Mamba能够更好地捕捉关键点之间的长程依赖关系,并且具有更强的序列建模能力。此外,多模态特征融合也增强了模型的鲁棒性。
关键设计:论文中Correspondence Mamba模块的具体实现细节未知,但可以推测其可能采用了Mamba模型的选择机制和状态空间建模能力,来动态地调整关键点之间的连接权重,从而适应不同的遮挡情况。损失函数可能包括关键点坐标的L1或L2损失,以及用于约束姿态合理性的正则化项。多模态特征融合的方式可能采用简单的拼接或更复杂的注意力机制。
🖼️ 关键图片
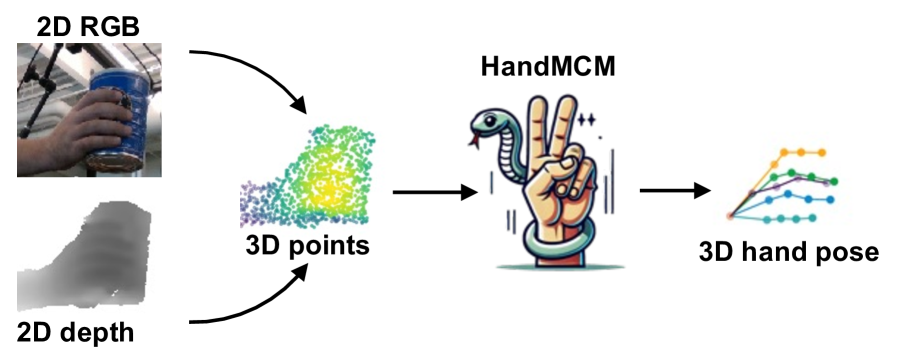
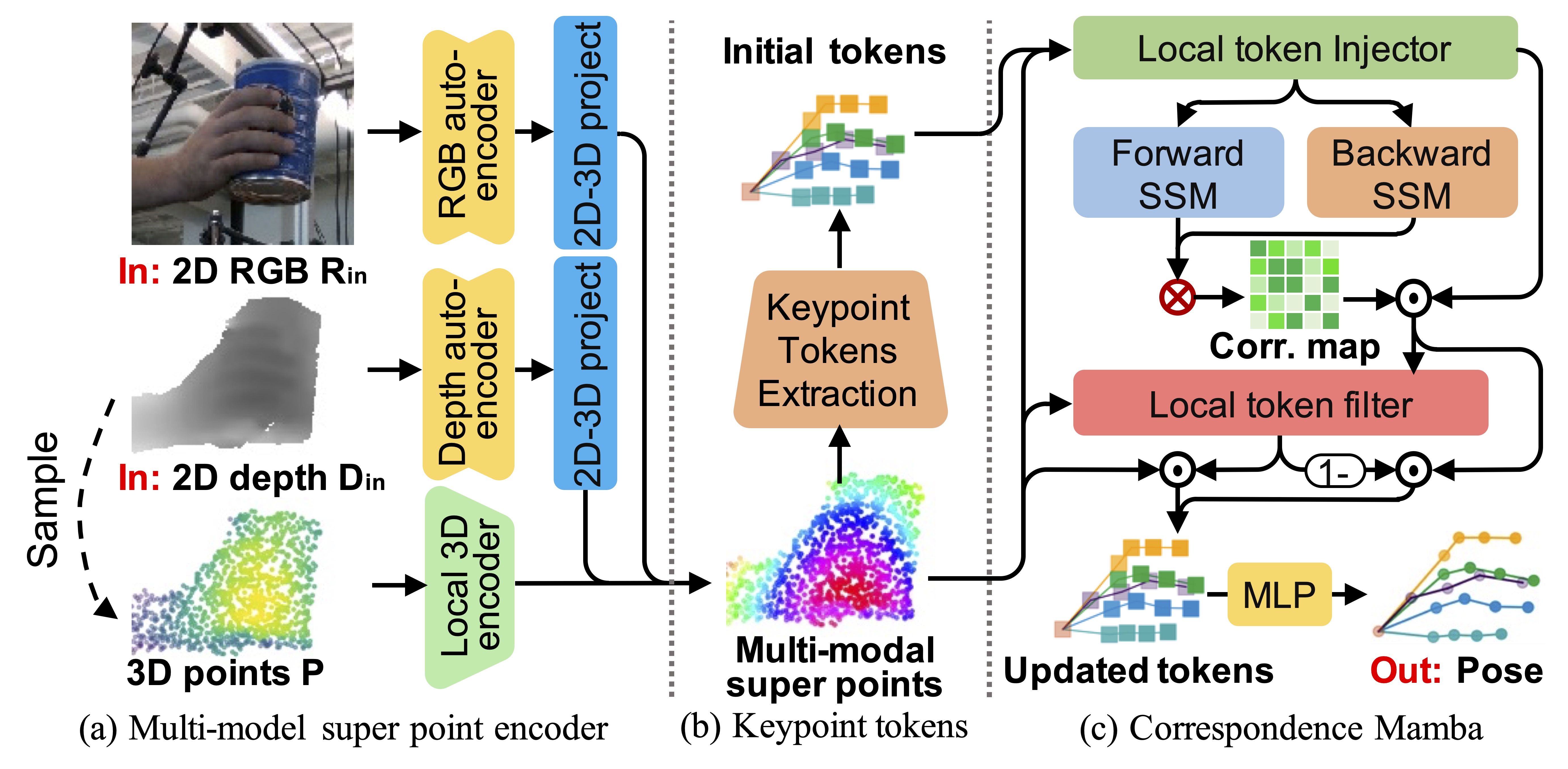

📊 实验亮点
HandMCM在三个基准数据集上取得了显著的性能提升,尤其是在具有挑战性的遮挡场景下。具体性能数据未知,但摘要中明确指出该模型“显著优于当前最先进的方法”,表明其在3D手部姿态估计的准确性和鲁棒性方面具有明显优势。
🎯 应用场景
该研究成果可广泛应用于人机交互、增强现实、虚拟现实、机器人控制等领域。通过准确估计手部姿态,可以实现更自然、更精确的手势识别和控制,提升用户体验。例如,在AR/VR游戏中,用户可以通过手势与虚拟环境进行交互;在机器人控制中,可以利用手部姿态信息引导机器人完成精细操作。
📄 摘要(原文)
3D hand pose estimation that involves accurate estimation of 3D human hand keypoint locations is crucial for many human-computer interaction applications such as augmented reality. However, this task poses significant challenges due to self-occlusion of the hands and occlusions caused by interactions with objects. In this paper, we propose HandMCM to address these challenges. Our HandMCM is a novel method based on the powerful state space model (Mamba). By incorporating modules for local information injection/filtering and correspondence modeling, the proposed correspondence Mamba effectively learns the highly dynamic kinematic topology of keypoints across various occlusion scenarios. Moreover, by integrating multi-modal image features, we enhance the robustness and representational capacity of the input, leading to more accurate hand pose estimation. Empirical evaluations on three benchmark datasets demonstrate that our model significantly outperforms current state-of-the-art methods, particularly in challenging scenarios involving severe occlusions. These results highlight the potential of our approach to advance the accuracy and reliability of 3D hand pose estimation in practical applications.