Multimodal UNcommonsense: From Odd to Ordinary and Ordinary to Odd
作者: Yejin Son, Saejin Kim, Dongjun Min, Younjae Yu
分类: cs.CV, cs.AI
发布日期: 2026-02-02
备注: 24 pages
💡 一句话要点
提出Multimodal UNcommonsense基准,并用R-ICL框架提升模型在异常场景下的常识推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态常识推理 视觉语言模型 上下文学习 检索增强 异常检测
📋 核心要点
- 现有视觉语言模型在处理不符合常识的异常场景时表现不足,缺乏鲁棒性和适应性。
- 提出基于检索的上下文学习框架R-ICL,利用多模态集成检索器MER,从大型模型迁移推理能力。
- 实验表明,R-ICL在Multimodal UNcommonsense基准上,相比基线ICL方法平均提升8.3%。
📝 摘要(中文)
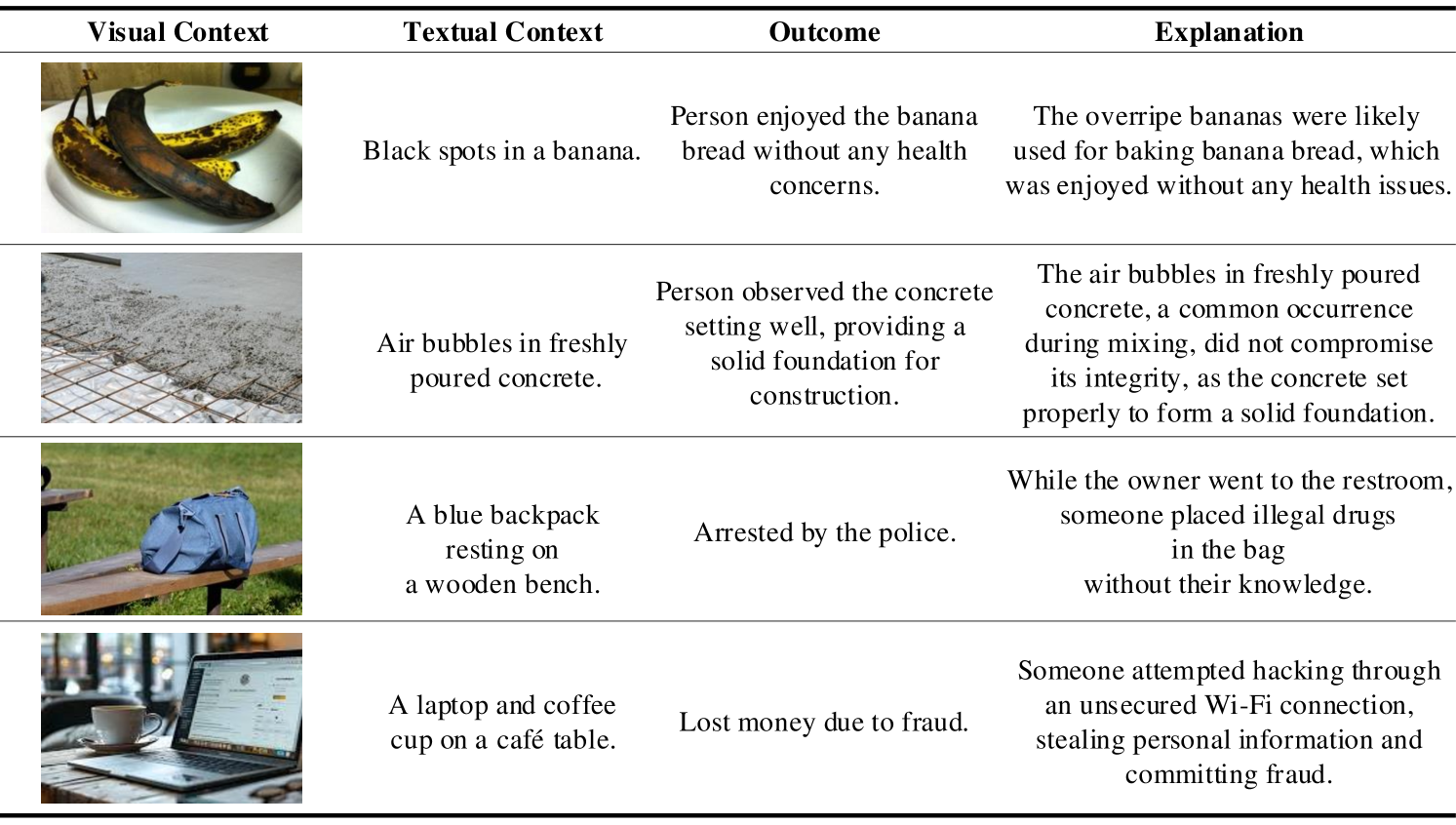
多模态情境下的常识推理仍然是人工智能领域的一个基础性挑战。我们提出了Multimodal UNcommonsense(MUN),这是一个旨在评估模型处理偏离典型视觉或上下文期望场景能力的基准。MUN将视觉场景与自然语言描述的令人惊讶或不太可能的结果配对,促使模型使用日常逻辑来合理化看似奇怪的图像,或者在普通场景中发现意想不到的解释。为了支持这项任务,我们提出了一个基于检索的上下文学习(R-ICL)框架,该框架将大型模型的推理能力转移到较小的模型,而无需额外的训练。利用一种新颖的多模态集成检索器(MER),我们的方法可以识别语义相关的示例,即使图像和文本对是故意不一致的。实验表明,与基线ICL方法相比,平均提高了8.3%,突出了R-ICL在低频、非典型环境中的有效性。MUN为评估和改进视觉语言模型在真实世界、文化多样和非原型场景中的鲁棒性和适应性开辟了新的方向。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型在处理多模态常识推理任务时,对于非典型或违反常识的场景表现不佳的问题。现有方法通常在常见场景下表现良好,但在面对异常情况时,推理能力会显著下降,缺乏鲁棒性和泛化性。
核心思路:论文的核心思路是利用检索增强的上下文学习(R-ICL),通过从大型模型中检索相关的示例,并将这些示例作为上下文提供给小型模型,从而提升小型模型在异常场景下的推理能力。这种方法避免了对小型模型进行额外的训练,而是通过知识迁移的方式来增强其性能。
技术框架:整体框架包含两个主要阶段:1) 多模态集成检索(MER):利用MER从大型模型的数据集中检索与当前输入最相关的示例。MER综合考虑图像和文本的语义信息,即使图像和文本对之间存在不一致,也能找到合适的示例。2) 上下文学习:将检索到的示例作为上下文,与当前输入一起输入到小型模型中,引导小型模型进行推理。小型模型根据上下文信息,判断当前场景是否符合常识,并给出相应的解释。
关键创新:论文的关键创新在于提出了多模态集成检索器(MER)。MER能够有效地处理图像和文本之间存在不一致的情况,从而在异常场景下也能找到语义相关的示例。此外,R-ICL框架通过检索增强的方式,实现了从大型模型到小型模型的知识迁移,避免了对小型模型进行额外的训练。
关键设计:MER的设计包括图像编码器和文本编码器,分别提取图像和文本的特征。然后,通过某种相似度度量(例如余弦相似度)来计算图像和文本之间的相似度。为了处理图像和文本不一致的情况,MER可能采用一些特殊的策略,例如使用注意力机制来关注图像和文本中最重要的部分,或者使用对比学习来学习图像和文本之间的关联关系。R-ICL框架的关键参数包括检索到的示例数量、上下文窗口的大小等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,R-ICL框架在Multimodal UNcommonsense基准上取得了显著的性能提升。与基线ICL方法相比,R-ICL平均提高了8.3%。这表明R-ICL能够有效地利用检索到的示例来增强模型在异常场景下的推理能力。此外,实验还验证了MER在处理图像和文本不一致情况下的有效性。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、医疗诊断等领域。例如,在智能监控中,可以帮助系统识别异常行为或事件;在自动驾驶中,可以提高车辆在复杂环境下的感知和决策能力;在医疗诊断中,可以辅助医生进行疾病诊断,尤其是在罕见病例或特殊情况下。该研究有助于提升人工智能系统在真实世界中的鲁棒性和可靠性。
📄 摘要(原文)
Commonsense reasoning in multimodal contexts remains a foundational challenge in artificial intelligence. We introduce Multimodal UNcommonsense(MUN), a benchmark designed to evaluate models' ability to handle scenarios that deviate from typical visual or contextual expectations. MUN pairs visual scenes with surprising or unlikely outcomes described in natural language, prompting models to either rationalize seemingly odd images using everyday logic or uncover unexpected interpretations in ordinary scenes. To support this task, we propose a retrieval-based in-context learning (R-ICL) framework that transfers reasoning capabilities from larger models to smaller ones without additional training. Leveraging a novel Multimodal Ensemble Retriever (MER), our method identifies semantically relevant exemplars even when image and text pairs are deliberately discordant. Experiments show an average improvement of 8.3% over baseline ICL methods, highlighting the effectiveness of R-ICL in low-frequency, atypical settings. MUN opens new directions for evaluating and improving visual-language models' robustness and adaptability in real-world, culturally diverse, and non-prototypical scenarios.