Making Avatars Interact: Towards Text-Driven Human-Object Interaction for Controllable Talking Avatars
作者: Youliang Zhang, Zhengguang Zhou, Zhentao Yu, Ziyao Huang, Teng Hu, Sen Liang, Guozhen Zhang, Ziqiao Peng, Shunkai Li, Yi Chen, Zixiang Zhou, Yuan Zhou, Qinglin Lu, Xiu Li
分类: cs.CV, cs.AI
发布日期: 2026-02-02
💡 一句话要点
InteractAvatar:提出双流框架,实现文本驱动的具身人与物交互的 talking avatar 生成
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: Talking Avatar 人与物交互 视频生成 双流框架 环境感知 动作生成 具身智能
📋 核心要点
- 现有talking avatar生成方法难以实现与环境物体交互,主要挑战在于环境感知和控制质量之间的平衡。
- InteractAvatar采用双流框架,将环境感知、交互规划与视频生成解耦,提升了控制性和生成质量。
- 论文构建了GroundedInter基准用于GHOI视频生成评估,实验证明了InteractAvatar在生成逼真交互avatar方面的有效性。
📝 摘要(中文)
本文提出了一种新的双流框架InteractAvatar,用于生成具有人与物交互(GHOI)的talking avatar。现有的talking avatar生成方法虽然可以生成具有简单人体动作的全身avatar,但扩展到GHOI仍然是一个开放的挑战,需要avatar执行与周围物体对齐的交互。这一挑战源于环境感知和GHOI生成中的控制质量困境。InteractAvatar将感知和规划与视频合成分离,以实现GHOI。利用检测增强环境感知,引入感知和交互模块(PIM)来生成文本对齐的交互动作。此外,提出了音频-交互感知生成模块(AIM)来合成执行物体交互的生动talking avatar。PIM和AIM共享相似的网络结构,并支持动作和视频的并行协同生成,从而有效地缓解了控制质量困境。最后,建立了一个名为GroundedInter的基准,用于评估GHOI视频生成。大量的实验和比较表明,该方法在为talking avatar生成GHOI方面是有效的。
🔬 方法详解
问题定义:现有talking avatar生成方法主要关注简单的人体动作,难以实现与周围物体的自然交互。主要痛点在于:一是缺乏对环境的有效感知,难以理解文本描述中物体的位置和属性;二是人与物交互的控制质量难以保证,容易出现动作不自然或视频不连贯的问题。
核心思路:InteractAvatar的核心思路是将环境感知、交互规划与视频生成解耦。通过独立的感知和交互模块(PIM)负责生成与文本描述对齐的交互动作,再通过音频-交互感知生成模块(AIM)将动作转化为逼真的talking avatar视频。这种解耦的设计可以有效缓解控制质量困境,提高生成视频的真实感和可控性。
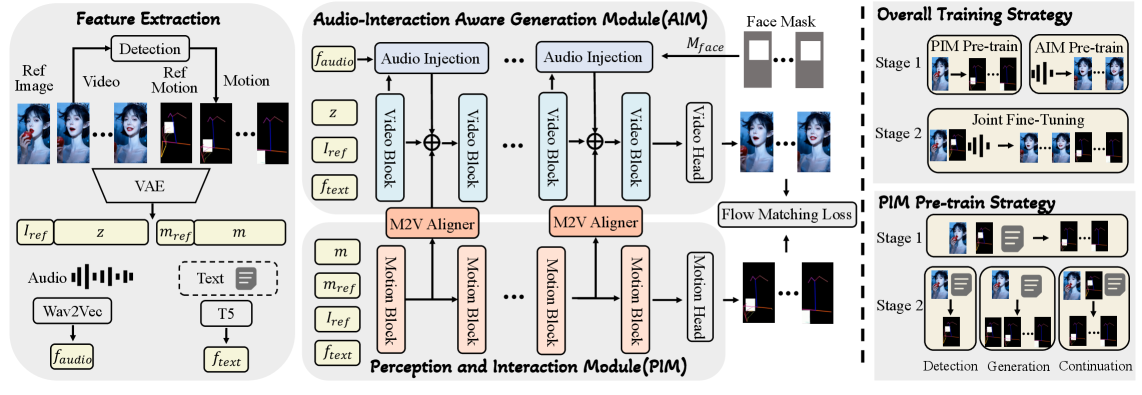
技术框架:InteractAvatar采用双流框架,包含两个主要模块:感知和交互模块(PIM)和音频-交互感知生成模块(AIM)。PIM首先利用目标检测增强环境感知,然后根据文本描述生成与物体交互的动作序列。AIM则根据音频和PIM生成的动作序列,生成talking avatar视频。PIM和AIM共享相似的网络结构,并采用运动到视频对齐器,实现动作和视频的并行协同生成。
关键创新:InteractAvatar的关键创新在于双流解耦框架,将环境感知和交互规划从视频生成中分离出来。这种设计使得模型可以更专注于理解文本描述中的交互信息,并生成更自然、更可控的交互动作。此外,PIM和AIM的并行协同生成机制,有效缓解了控制质量困境。
关键设计:PIM模块利用目标检测器提取环境中的物体信息,并将其与文本描述相结合,生成交互动作序列。AIM模块采用生成对抗网络(GAN)结构,根据音频和动作序列生成talking avatar视频。特别设计的运动到视频对齐器,用于保证PIM生成的动作与AIM生成的视频在时序上的一致性。损失函数包括对抗损失、重构损失和运动损失,用于提高生成视频的真实感和动作的自然性。
🖼️ 关键图片

📊 实验亮点
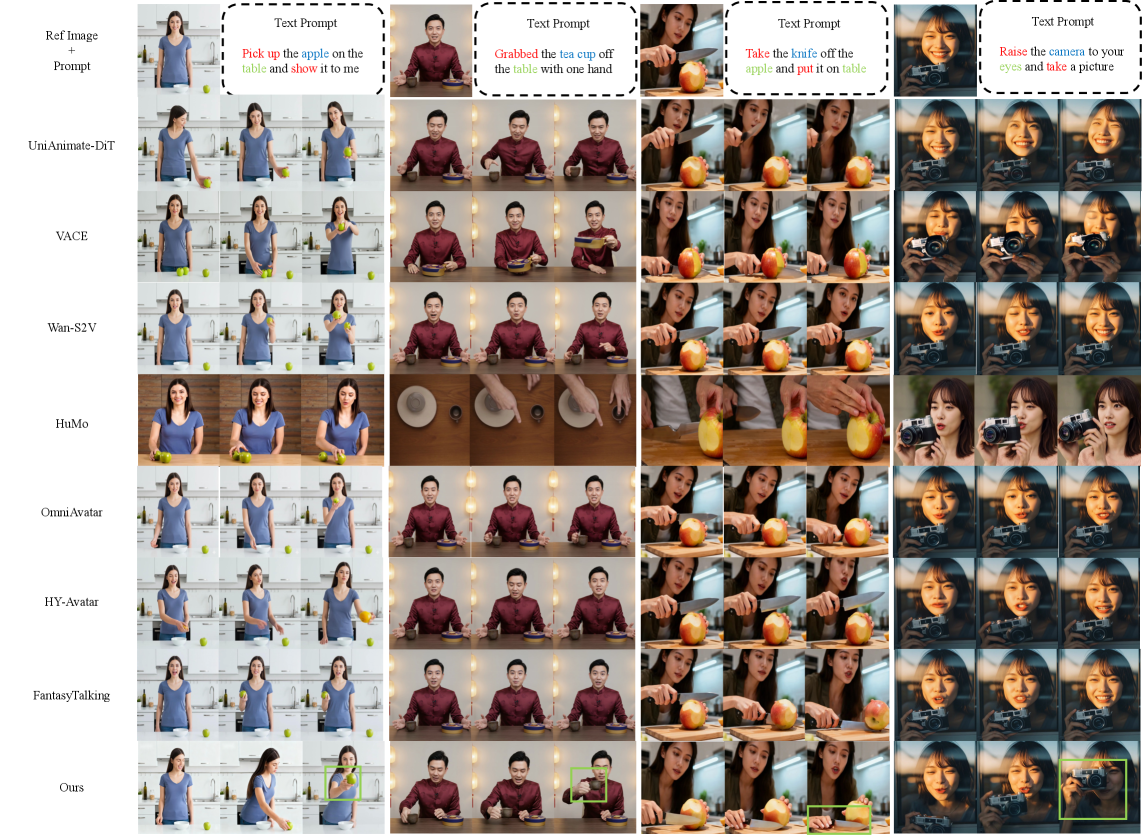
实验结果表明,InteractAvatar在GroundedInter基准上取得了显著的性能提升,在生成逼真的人与物交互talking avatar方面优于现有方法。通过定性和定量分析,验证了InteractAvatar在环境感知、交互动作生成和视频生成方面的有效性。具体性能数据未知,但论文强调了其方法在生成GHOI方面的优越性。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏、社交媒体等领域,例如创建能够与用户进行自然交互的虚拟助手、生成具有逼真交互动作的游戏角色、以及在社交媒体平台上创建更具表现力的虚拟化身。未来,该技术有望进一步扩展到更复杂的交互场景,例如多人交互、复杂环境交互等。
📄 摘要(原文)
Generating talking avatars is a fundamental task in video generation. Although existing methods can generate full-body talking avatars with simple human motion, extending this task to grounded human-object interaction (GHOI) remains an open challenge, requiring the avatar to perform text-aligned interactions with surrounding objects. This challenge stems from the need for environmental perception and the control-quality dilemma in GHOI generation. To address this, we propose a novel dual-stream framework, InteractAvatar, which decouples perception and planning from video synthesis for grounded human-object interaction. Leveraging detection to enhance environmental perception, we introduce a Perception and Interaction Module (PIM) to generate text-aligned interaction motions. Additionally, an Audio-Interaction Aware Generation Module (AIM) is proposed to synthesize vivid talking avatars performing object interactions. With a specially designed motion-to-video aligner, PIM and AIM share a similar network structure and enable parallel co-generation of motions and plausible videos, effectively mitigating the control-quality dilemma. Finally, we establish a benchmark, GroundedInter, for evaluating GHOI video generation. Extensive experiments and comparisons demonstrate the effectiveness of our method in generating grounded human-object interactions for talking avatars. Project page: https://interactavatar.github.io