VideoGPA: Distilling Geometry Priors for 3D-Consistent Video Generation
作者: Hongyang Du, Junjie Ye, Xiaoyan Cong, Runhao Li, Jingcheng Ni, Aman Agarwal, Zeqi Zhou, Zekun Li, Randall Balestriero, Yue Wang
分类: cs.CV, cs.AI, cs.LG
发布日期: 2026-01-30
💡 一句话要点
VideoGPA:通过几何先验知识蒸馏实现3D一致性视频生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 扩散模型 几何先验 3D一致性 直接偏好优化 自监督学习 几何基础模型
📋 核心要点
- 现有视频扩散模型难以保持3D结构一致性,导致物体变形和空间漂移。
- VideoGPA利用几何基础模型,通过直接偏好优化引导视频扩散模型,提升3D一致性。
- 实验表明,VideoGPA在时间稳定性、物理合理性和运动连贯性方面显著优于现有方法。
📝 摘要(中文)
尽管最近的视频扩散模型(VDMs)产生了视觉上令人印象深刻的结果,但它们在保持3D结构一致性方面存在根本性困难,经常导致物体变形或空间漂移。我们假设这些失败是由于标准去噪目标缺乏对几何连贯性的明确激励。为了解决这个问题,我们引入了VideoGPA(视频几何偏好对齐),这是一个数据高效的自监督框架,它利用几何基础模型自动导出密集偏好信号,通过直接偏好优化(DPO)来指导VDM。这种方法有效地将生成分布导向固有的3D一致性,而不需要人工标注。VideoGPA使用最少的偏好对显著增强了时间稳定性、物理合理性和运动连贯性,在广泛的实验中始终优于最先进的基线。
🔬 方法详解
问题定义:现有视频生成模型,特别是基于扩散模型的方案,在生成视频时难以保证3D结构的一致性。这意味着生成的视频中物体可能会发生不自然的变形,或者在空间中出现漂移,缺乏物理真实感。这种不一致性源于模型训练过程中缺乏对几何约束的显式建模和优化。
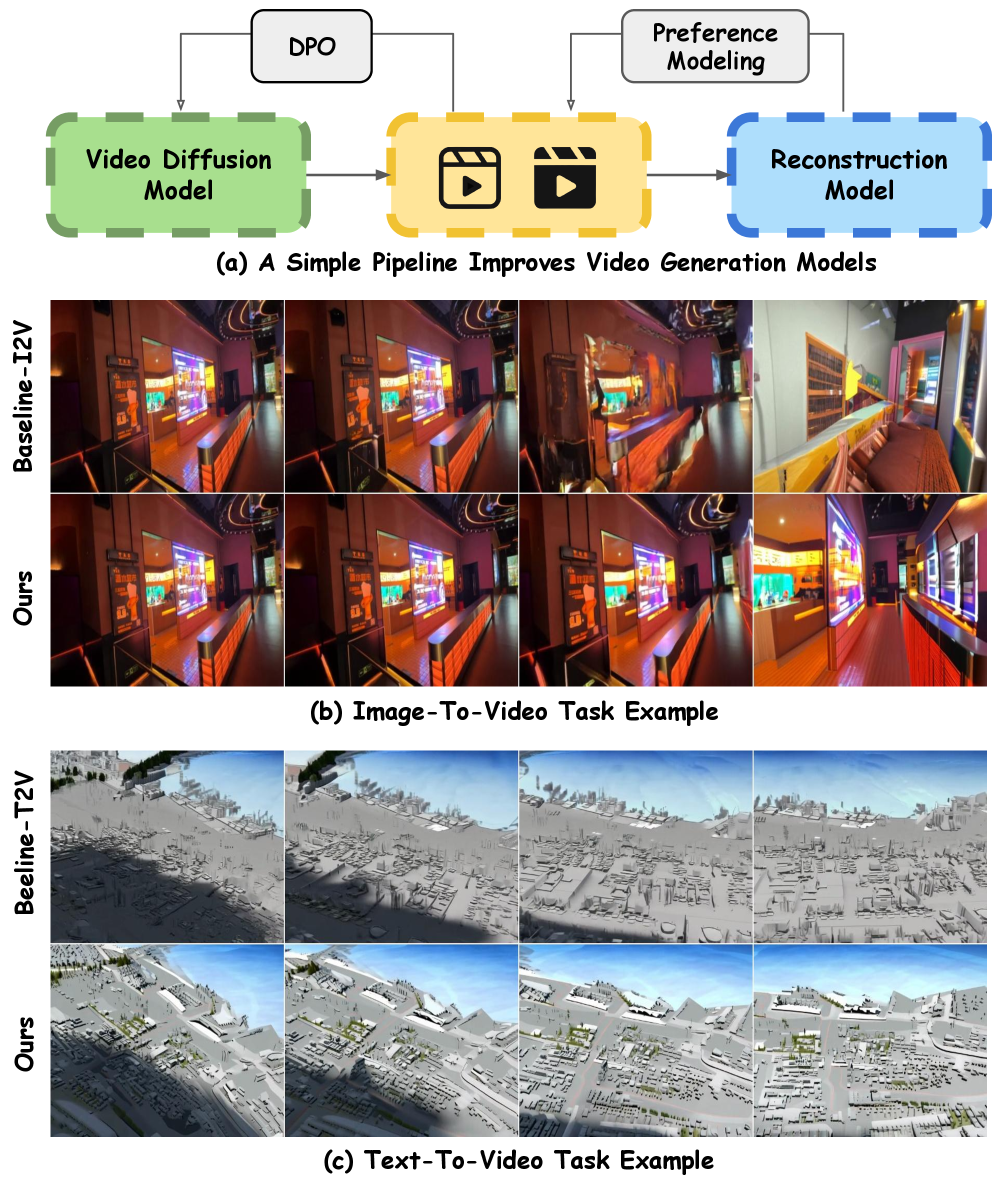
核心思路:VideoGPA的核心思想是利用一个预训练的几何基础模型来提供几何先验知识,并将其转化为偏好信号,从而引导视频扩散模型生成更符合3D结构的视频。通过直接偏好优化(DPO),模型学习倾向于那些具有更好几何一致性的视频片段。
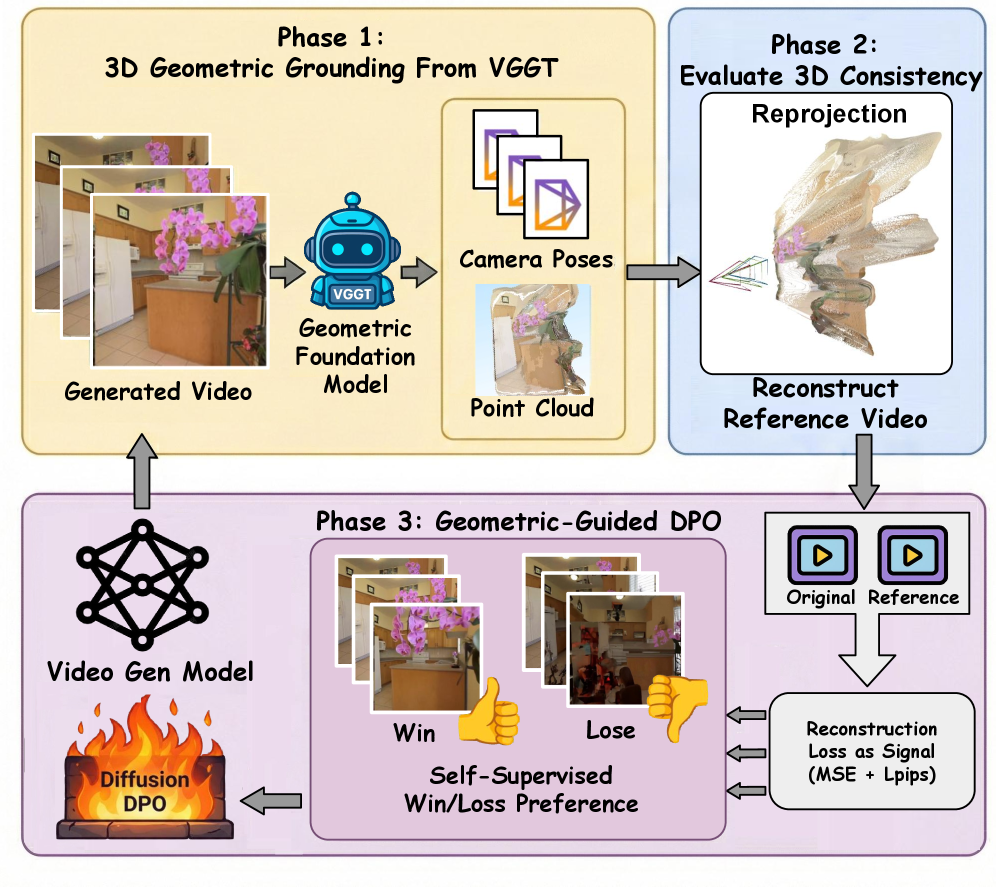
技术框架:VideoGPA框架主要包含以下几个阶段:1) 使用几何基础模型(例如,一个深度估计网络)从生成的视频片段中提取几何信息,如深度图。2) 基于提取的几何信息,计算一个偏好分数,用于衡量视频片段的3D一致性。3) 使用直接偏好优化(DPO)算法,根据偏好分数调整视频扩散模型的参数,使其倾向于生成具有更高几何一致性的视频。
关键创新:VideoGPA的关键创新在于:1) 提出了一种自监督的方式,利用几何基础模型自动生成偏好信号,无需人工标注。2) 将几何先验知识融入到视频扩散模型的训练过程中,从而显式地提升了生成视频的3D一致性。3) 使用直接偏好优化(DPO)算法,能够更有效地利用偏好信号来指导模型的训练。
关键设计:VideoGPA的关键设计包括:1) 选择合适的几何基础模型,确保能够准确地提取视频片段的几何信息。2) 设计合理的偏好分数计算方法,能够有效地衡量视频片段的3D一致性。3) 调整DPO算法的参数,使其能够稳定地提升模型的性能。具体而言,损失函数的设计需要平衡生成质量和几何一致性,避免过度优化几何一致性而牺牲视觉质量。
🖼️ 关键图片
📊 实验亮点
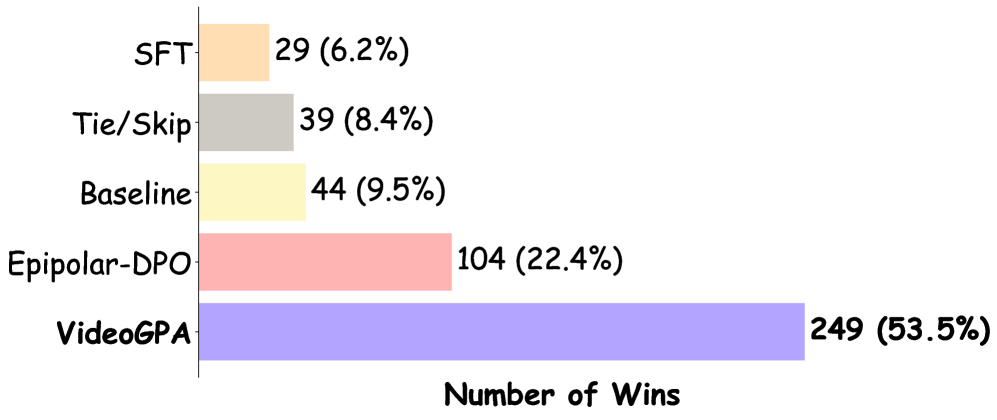
VideoGPA在多个视频生成任务上取得了显著的性能提升。实验结果表明,VideoGPA能够显著提高生成视频的时间稳定性、物理合理性和运动连贯性。相较于现有最先进的基线方法,VideoGPA在3D一致性指标上取得了明显的优势,并且只需要少量的偏好对数据即可达到良好的效果。具体性能提升数据在论文中有详细展示。
🎯 应用场景
VideoGPA在视频生成、虚拟现实、游戏开发等领域具有广泛的应用前景。它可以用于生成更逼真、更符合物理规律的虚拟场景和角色动画,提升用户体验。此外,该方法还可以应用于视频编辑和修复,例如,可以用于修复视频中的几何失真,提高视频质量。未来,该技术有望应用于自动驾驶、机器人导航等需要精确3D感知的领域。
📄 摘要(原文)
While recent video diffusion models (VDMs) produce visually impressive results, they fundamentally struggle to maintain 3D structural consistency, often resulting in object deformation or spatial drift. We hypothesize that these failures arise because standard denoising objectives lack explicit incentives for geometric coherence. To address this, we introduce VideoGPA (Video Geometric Preference Alignment), a data-efficient self-supervised framework that leverages a geometry foundation model to automatically derive dense preference signals that guide VDMs via Direct Preference Optimization (DPO). This approach effectively steers the generative distribution toward inherent 3D consistency without requiring human annotations. VideoGPA significantly enhances temporal stability, physical plausibility, and motion coherence using minimal preference pairs, consistently outperforming state-of-the-art baselines in extensive experiments.