Med-Scout: Curing MLLMs' Geometric Blindness in Medical Perception via Geometry-Aware RL Post-Training
作者: Anglin Liu, Ruichao Chen, Yi Lu, Hongxia Xu, Jintai Chen
分类: cs.CV, cs.AI
发布日期: 2026-01-30
💡 一句话要点
Med-Scout:通过几何感知强化学习后训练,解决MLLM在医学感知中的几何盲区问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大型语言模型 医学图像理解 几何感知 强化学习 后训练 代理任务 几何盲区
📋 核心要点
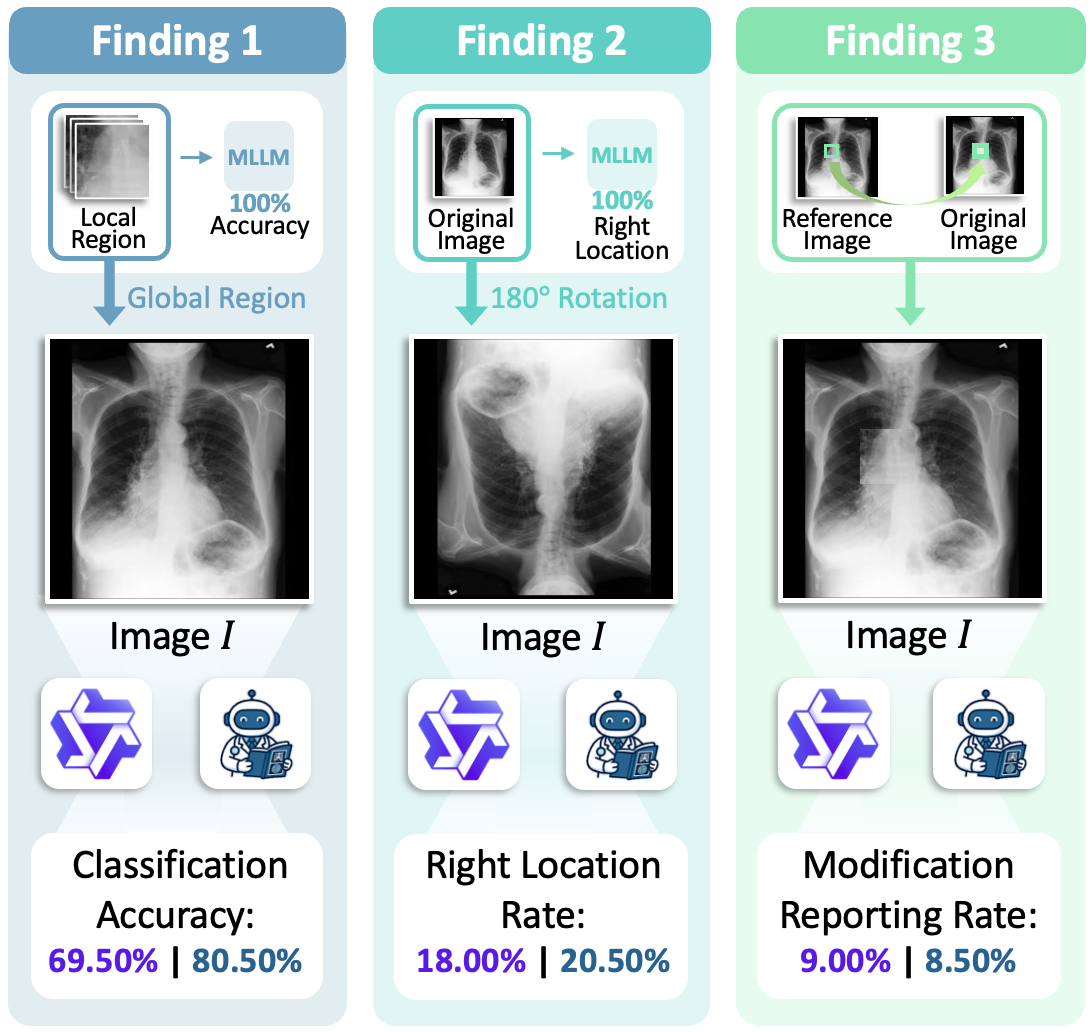
- 现有MLLM在医学诊断中存在“几何盲区”,无法有效理解和利用医学图像中的几何信息,导致产生不准确的推断。
- Med-Scout通过强化学习,利用未标注医学图像的内在几何逻辑,训练模型学习几何约束,无需昂贵的专家标注。
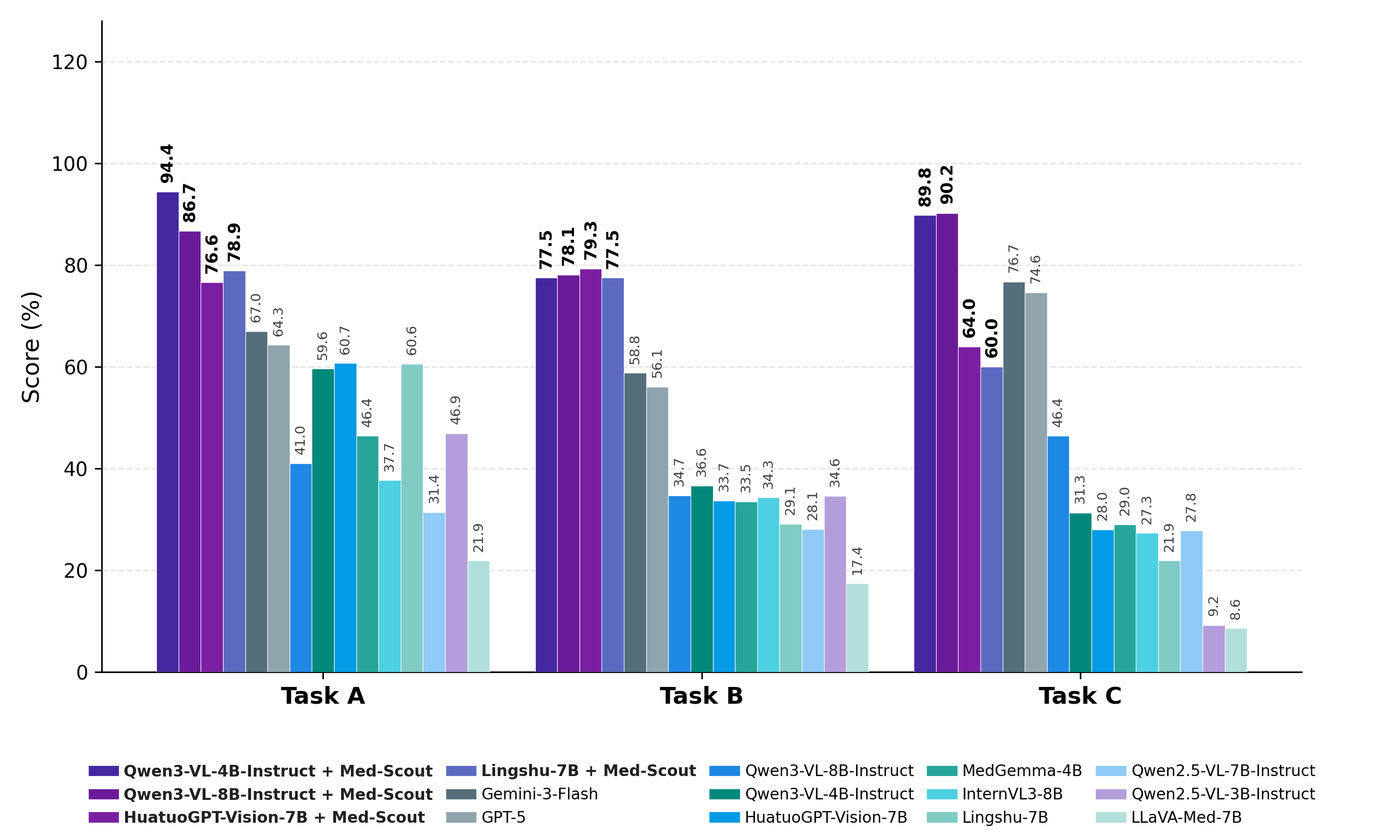
- Med-Scout在Med-Scout-Bench上超越现有MLLM 40%以上,并在放射学和综合医学VQA任务上取得了更好的效果。
📝 摘要(中文)
尽管最近的多模态大型语言模型(MLLM)在医学诊断方面展现出卓越的语言能力,但我们发现,即使是最先进的MLLM也存在一个关键的感知缺陷:几何盲区。这种无法将输出与客观几何约束对齐的缺陷,导致了看似合理但实际上不正确的幻觉,其根源在于训练范式优先考虑语言流畅性而非几何保真度。本文介绍了一种名为Med-Scout的新框架,它通过强化学习(RL)“治愈”这种盲区,利用未标记医学图像中内在的几何逻辑。Med-Scout没有依赖昂贵的专家标注,而是通过三个战略性的代理任务来获得可验证的监督信号:分层尺度定位、拓扑拼图重建和异常一致性检测。为了严格量化这种缺陷,我们提出了Med-Scout-Bench,这是一个专门用于评估几何感知的新基准。广泛的评估表明,Med-Scout显著缓解了几何盲区,在我们的基准测试中,性能超过了领先的专有和开源MLLM 40%以上。此外,这种增强的几何感知能力可以推广到更广泛的医学理解,在放射学和综合医学VQA任务上取得了优异的成绩。
🔬 方法详解
问题定义:现有MLLM在医学图像理解中,虽然具备强大的语言能力,但缺乏对图像几何信息的有效感知,导致在医学诊断中产生不符合实际几何约束的错误结论,即“几何盲区”。现有方法过度依赖语言流畅性,忽略了几何保真度,且依赖昂贵的专家标注。
核心思路:Med-Scout的核心思路是通过强化学习,让模型学习医学图像中内在的几何逻辑,从而克服几何盲区。通过设计一系列代理任务,将几何约束转化为可学习的奖励信号,引导模型学习正确的几何关系。
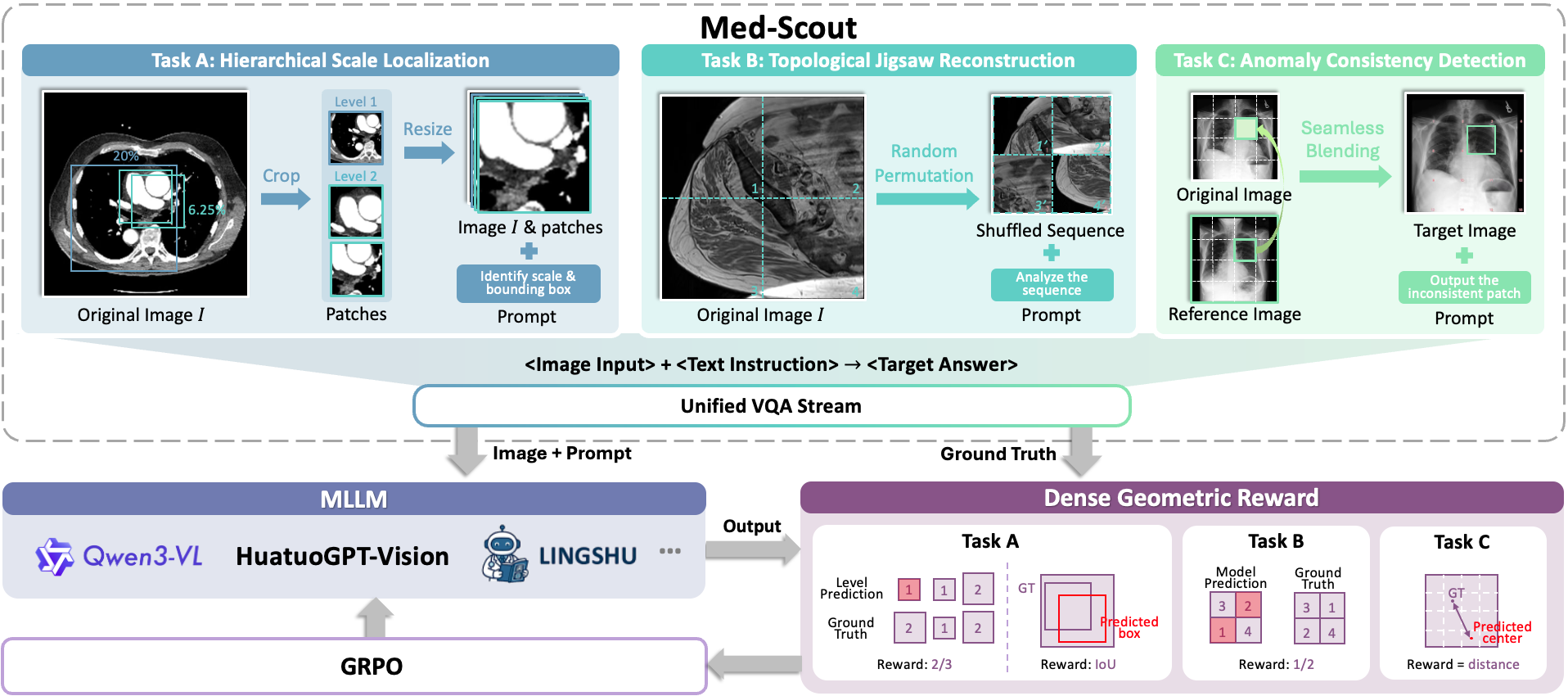
技术框架:Med-Scout框架主要包含三个阶段:1)预训练的MLLM作为基础模型;2)通过强化学习进行后训练,利用三个代理任务(分层尺度定位、拓扑拼图重建和异常一致性检测)来学习几何信息;3)在Med-Scout-Bench以及其他医学VQA数据集上进行评估。
关键创新:Med-Scout的关键创新在于:1)提出了一种基于强化学习的后训练方法,无需人工标注即可提升MLLM的几何感知能力;2)设计了三个新颖的代理任务,有效地将几何约束转化为可学习的奖励信号;3)构建了Med-Scout-Bench,用于评估MLLM的几何感知能力。
关键设计:三个代理任务的设计是关键:分层尺度定位旨在让模型理解不同尺度下的图像特征;拓扑拼图重建旨在让模型理解图像的拓扑结构;异常一致性检测旨在让模型识别不符合几何一致性的异常情况。强化学习的奖励函数设计与这三个任务紧密相关,鼓励模型做出符合几何约束的决策。具体的网络结构细节和参数设置在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
Med-Scout在Med-Scout-Bench上显著优于现有的MLLM,性能提升超过40%。此外,在放射学VQA和综合医学VQA任务上也取得了更好的结果,表明Med-Scout不仅能有效缓解几何盲区,还能提升模型在更广泛医学理解任务上的性能。实验结果证明了该方法的有效性和泛化能力。
🎯 应用场景
Med-Scout可应用于多种医学图像分析任务,例如辅助诊断、病灶定位、手术规划等。通过提升MLLM对医学图像几何信息的理解,可以减少诊断错误,提高医疗效率,并为远程医疗和智能化医疗提供更可靠的技术支持。该研究的思路也可推广到其他需要几何推理的多模态任务中。
📄 摘要(原文)
Despite recent Multimodal Large Language Models (MLLMs)' linguistic prowess in medical diagnosis, we find even state-of-the-art MLLMs suffer from a critical perceptual deficit: geometric blindness. This failure to ground outputs in objective geometric constraints leads to plausible yet factually incorrect hallucinations, rooted in training paradigms that prioritize linguistic fluency over geometric fidelity. This paper introduces Med-Scout, a novel framework that "cures" this blindness via Reinforcement Learning (RL) that leverages the intrinsic geometric logic latent within unlabeled medical images. Instead of relying on costly expert annotations, Med-Scout derives verifiable supervision signals through three strategic proxy tasks: Hierarchical Scale Localization, Topological Jigsaw Reconstruction, and Anomaly Consistency Detection. To rigorously quantify this deficit, we present Med-Scout-Bench, a new benchmark specifically designed to evaluate geometric perception. Extensive evaluations show that Med-Scout significantly mitigates geometric blindness, outperforming leading proprietary and open-source MLLMs by over 40% on our benchmark. Furthermore, this enhanced geometric perception generalizes to broader medical understanding, achieving superior results on radiological and comprehensive medical VQA tasks.