DINO-SAE: DINO Spherical Autoencoder for High-Fidelity Image Reconstruction and Generation
作者: Hun Chang, Byunghee Cha, Jong Chul Ye
分类: cs.CV, cs.AI, cs.LG
发布日期: 2026-01-30
备注: 17 pages, and 11 figures
💡 一句话要点
DINO-SAE:用于高保真图像重建与生成的DINO球面自编码器
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像重建 生成模型 自编码器 DINO 球面流形 扩散模型 黎曼流匹配
📋 核心要点
- 现有基于DINO的生成自编码器在重建时丢失高频细节,导致重建保真度受限。
- DINO-SAE通过解耦特征向量的方向和幅度,并结合球面潜在空间扩散模型,提升重建质量。
- 实验表明,DINO-SAE在ImageNet-1K上实现了SOTA的重建质量,并具有高效的生成能力。
📝 摘要(中文)
本文提出DINO球面自编码器(DINO-SAE),旨在弥合语义表示和像素级重建之间的差距。现有方法通常由于高频细节的丢失而导致重建保真度受限。DINO-SAE的关键在于,对比表示中的语义信息主要编码在特征向量的方向上,而强制严格的幅度匹配会阻碍编码器保留精细的细节。为此,引入了分层卷积块嵌入模块,以增强局部结构和纹理的保留;并提出了余弦相似度对齐目标,以保证语义一致性,同时允许灵活的特征幅度以保留细节。此外,利用基于SSL的基础模型表示本质上位于超球面上的观察结果,采用黎曼流匹配在该球面潜在流形上直接训练扩散Transformer (DiT)。在ImageNet-1K上的实验表明,该方法达到了最先进的重建质量,rFID为0.37,PSNR为26.2 dB,同时保持了与预训练VFM的强语义对齐。基于黎曼流匹配的DiT表现出高效的收敛性,在80个epoch时达到3.47的gFID。
🔬 方法详解
问题定义:现有基于DINO的生成自编码器在图像重建任务中,由于对特征向量的幅值进行严格约束,导致高频细节丢失,重建图像的保真度不高。因此,如何有效利用DINO的语义信息,同时保留图像的细节信息,是本文要解决的核心问题。
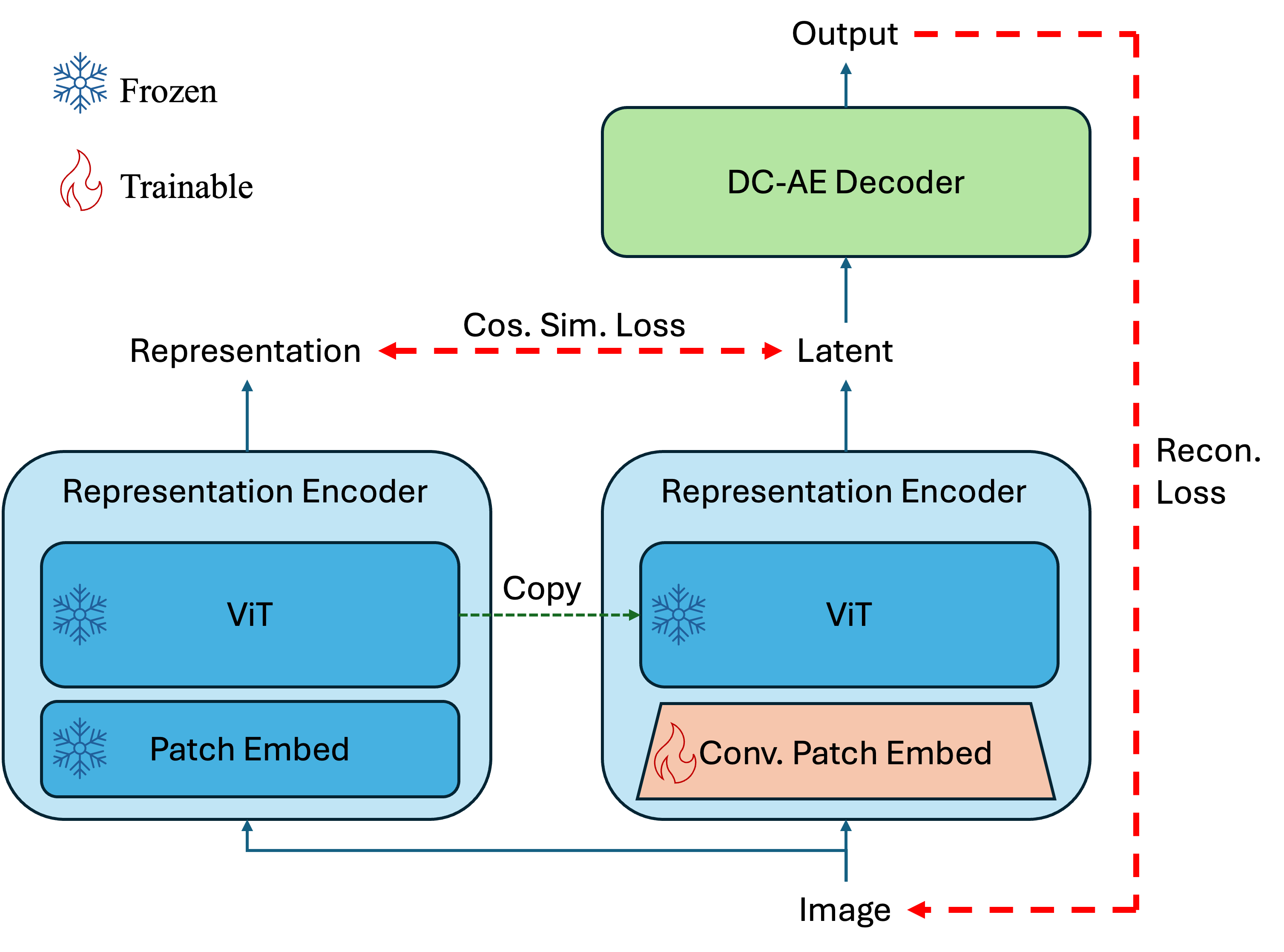
核心思路:论文的核心思路是将语义信息与细节信息解耦。具体来说,认为DINO特征向量的方向主要编码了语义信息,而幅值则可以用来表示细节信息。因此,在训练过程中,允许特征向量的幅值具有一定的灵活性,从而保留更多的细节信息。此外,考虑到DINO的特征表示天然位于超球面上,因此在超球面上进行生成建模。
技术框架:DINO-SAE的整体框架是一个自编码器结构,包含编码器和解码器。编码器将输入图像编码为DINO特征向量,解码器将DINO特征向量解码为重建图像。为了提升重建质量,编码器中引入了分层卷积块嵌入模块,用于增强局部结构和纹理的保留。为了保证语义一致性,使用了余弦相似度对齐目标。在潜在空间中,使用黎曼流匹配训练扩散Transformer (DiT),用于生成新的DINO特征向量。
关键创新:论文的关键创新点在于:1) 提出了解耦语义信息和细节信息的思想,允许特征向量的幅值具有一定的灵活性;2) 提出了分层卷积块嵌入模块,用于增强局部结构和纹理的保留;3) 利用黎曼流匹配在球面潜在空间上训练扩散模型,提高了生成效率。与现有方法相比,DINO-SAE能够更好地保留图像的细节信息,并生成更高质量的图像。
关键设计:分层卷积块嵌入模块包含多个卷积层,用于提取不同尺度的特征。余弦相似度对齐目标用于约束编码后的特征向量与原始DINO特征向量之间的语义一致性。黎曼流匹配使用球面上的流形结构来指导扩散模型的训练。扩散Transformer (DiT) 的具体结构未知,但应该针对球面数据进行了优化。
🖼️ 关键图片

📊 实验亮点
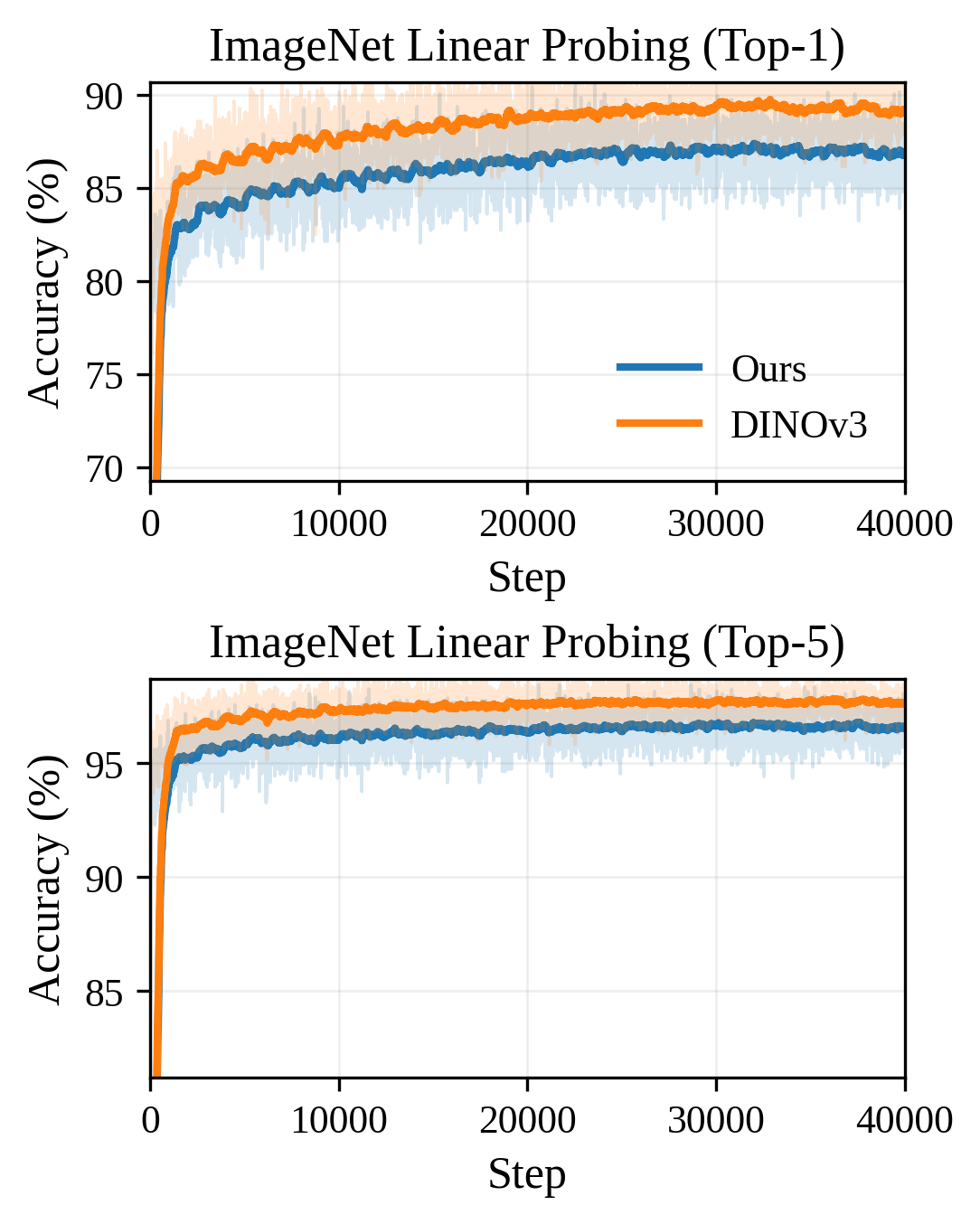
DINO-SAE在ImageNet-1K数据集上取得了显著的性能提升,重建质量达到SOTA水平,rFID为0.37,PSNR为26.2 dB,表明其在高保真图像重建方面的优越性。同时,基于黎曼流匹配的DiT在80个epoch时达到3.47的gFID,展示了其高效的收敛速度和强大的生成能力。这些结果证明了DINO-SAE在图像重建和生成任务中的有效性。
🎯 应用场景
DINO-SAE可应用于图像修复、超分辨率、图像生成等领域。通过提升图像重建的保真度,可以改善图像修复和超分辨率的效果。此外,DINO-SAE还可以用于生成高质量的图像,例如用于艺术创作、游戏开发等。该研究的未来影响在于,可以促进生成模型的进一步发展,并推动其在更多领域的应用。
📄 摘要(原文)
Recent studies have explored using pretrained Vision Foundation Models (VFMs) such as DINO for generative autoencoders, showing strong generative performance. Unfortunately, existing approaches often suffer from limited reconstruction fidelity due to the loss of high-frequency details. In this work, we present the DINO Spherical Autoencoder (DINO-SAE), a framework that bridges semantic representation and pixel-level reconstruction. Our key insight is that semantic information in contrastive representations is primarily encoded in the direction of feature vectors, while forcing strict magnitude matching can hinder the encoder from preserving fine-grained details. To address this, we introduce Hierarchical Convolutional Patch Embedding module that enhances local structure and texture preservation, and Cosine Similarity Alignment objective that enforces semantic consistency while allowing flexible feature magnitudes for detail retention. Furthermore, leveraging the observation that SSL-based foundation model representations intrinsically lie on a hypersphere, we employ Riemannian Flow Matching to train a Diffusion Transformer (DiT) directly on this spherical latent manifold. Experiments on ImageNet-1K demonstrate that our approach achieves state-of-the-art reconstruction quality, reaching 0.37 rFID and 26.2 dB PSNR, while maintaining strong semantic alignment to the pretrained VFM. Notably, our Riemannian Flow Matching-based DiT exhibits efficient convergence, achieving a gFID of 3.47 at 80 epochs.