Inference-Time Dynamic Modality Selection for Incomplete Multimodal Classification
作者: Siyi Du, Xinzhe Luo, Declan P. O'Regan, Chen Qin
分类: cs.CV
发布日期: 2026-01-30
备注: 27 pages (including appendix), accepted by ICLR 2026
💡 一句话要点
DyMo:针对不完整多模态分类的推理时动态模态选择框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 不完整数据 动态模态选择 深度学习 分类 医学图像 推理时优化
📋 核心要点
- 现有不完整多模态学习方法面临丢弃有用信息或引入噪声的困境,限制了模型性能。
- DyMo框架通过动态选择可靠的恢复模态,最大化利用任务相关信息,避免了传统方法的局限。
- 实验表明,DyMo在多种数据集和缺失场景下,显著优于现有不完整多模态学习方法。
📝 摘要(中文)
多模态深度学习(MDL)在各个领域取得了显著的成功,但其实际部署常常受到不完整多模态数据的阻碍。现有的不完整MDL方法要么丢弃缺失的模态,从而可能丢失有价值的任务相关信息,要么恢复它们,可能引入不相关的噪声,导致丢弃-填补困境。为了解决这个困境,本文提出DyMo,一种新的推理时动态模态选择框架,它自适应地识别和整合可靠的恢复模态,充分探索超出传统丢弃或填补范式的任务相关信息。DyMo的核心是一种新颖的选择算法,它为每个测试样本最大化多模态任务相关信息。由于在测试时直接估计此类信息因未知数据分布而难以处理,因此我们在理论上建立了信息与任务损失之间的联系,我们在推理时将其计算为可处理的代理。在此基础上,提出了一种新的基于原则的奖励函数来指导模态选择。此外,我们设计了一个灵活的多模态网络架构,与任意模态组合兼容,以及为鲁棒表示学习量身定制的训练策略。在各种自然和医学图像数据集上的大量实验表明,DyMo在各种缺失数据场景中显著优于最先进的不完整/动态MDL方法。
🔬 方法详解
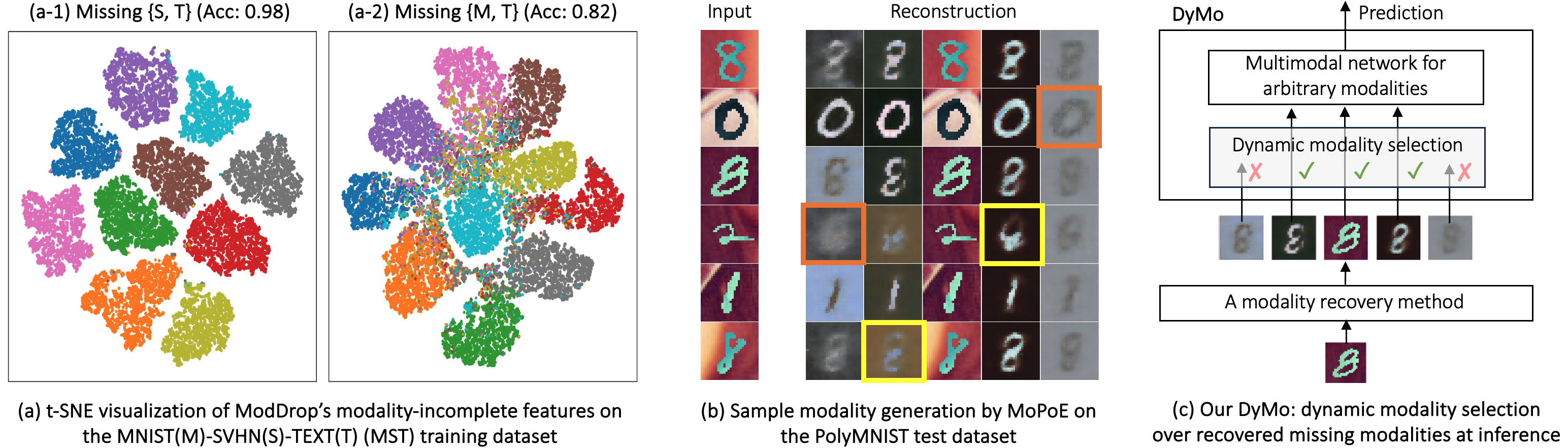
问题定义:论文旨在解决不完整多模态分类问题,即在推理阶段,某些模态的数据可能缺失。现有方法要么直接丢弃缺失模态,导致信息损失;要么对缺失模态进行填补,但可能引入噪声,影响分类精度。这两种策略都无法充分利用可用的信息。
核心思路:论文的核心思路是动态地选择在推理时可用的模态,而不是简单地丢弃或填补缺失的模态。通过学习一个选择策略,模型可以根据每个样本的实际情况,选择最可靠和信息量最大的模态组合进行分类。这种方法旨在最大化利用任务相关信息,同时避免引入不必要的噪声。
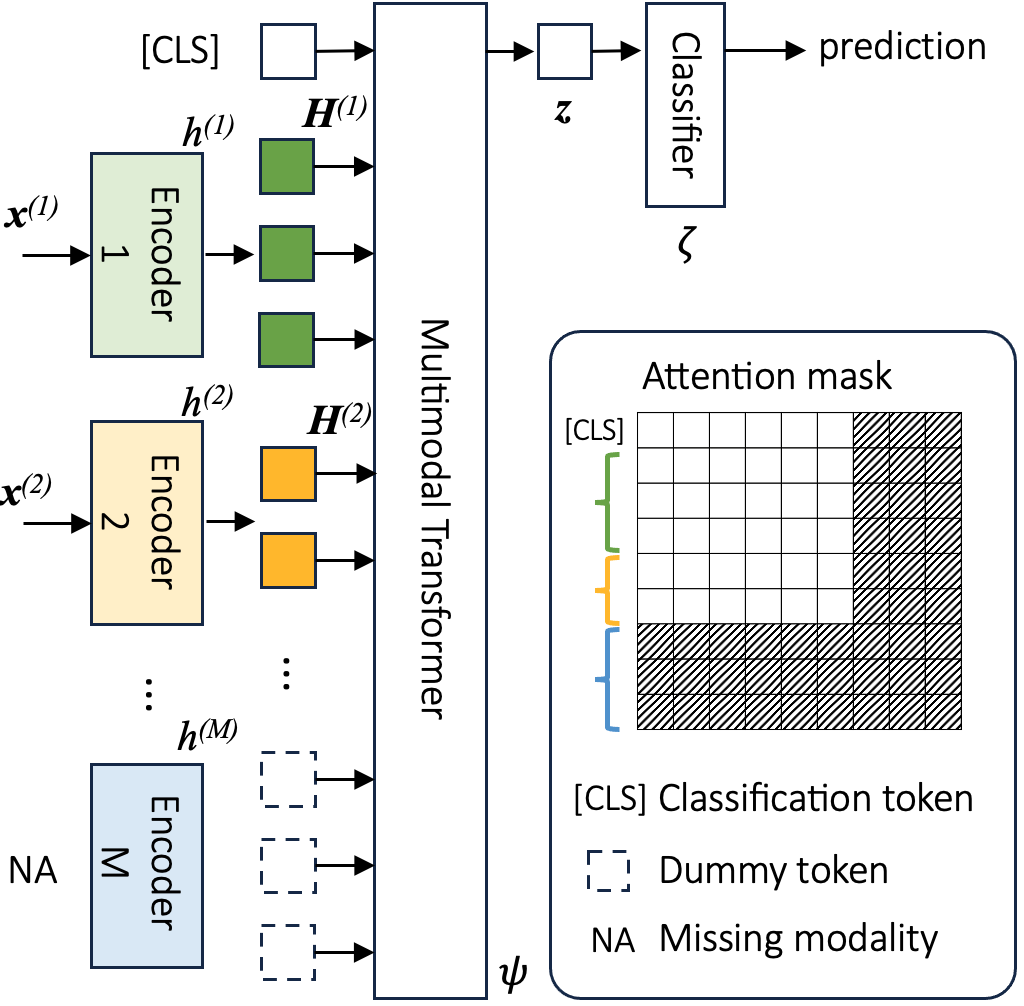
技术框架:DyMo框架包含以下几个主要组成部分:1) 一个灵活的多模态网络架构,可以处理任意模态组合;2) 一个模态选择算法,用于在推理时动态选择模态;3) 一个基于任务损失的奖励函数,用于指导模态选择;4) 一个定制的训练策略,用于学习鲁棒的模态表示。整体流程是,对于每个测试样本,首先使用多模态网络提取各个模态的特征,然后使用模态选择算法选择合适的模态组合,最后使用选择的模态进行分类。
关键创新:论文的关键创新在于提出了一个基于任务损失的奖励函数来指导模态选择。由于直接估计任务相关信息在推理时是不可行的,论文在理论上建立了信息与任务损失之间的联系,并将任务损失作为信息量的代理。通过最小化任务损失,模型可以学习到选择最有利于分类的模态组合。这种方法避免了手动设计模态选择规则的困难,并能够自适应地处理不同的缺失模式。
关键设计:在网络结构方面,论文设计了一个可以灵活处理任意模态组合的多模态网络。在训练策略方面,论文采用了一种定制的训练方法,以学习鲁棒的模态表示。奖励函数的设计是基于任务损失的,具体形式未知,但其目标是最小化分类误差。模态选择算法的细节未知,但其核心是最大化选择的模态组合的信息量。
🖼️ 关键图片
📊 实验亮点
论文在多个自然和医学图像数据集上进行了实验,结果表明DyMo显著优于现有的不完整/动态MDL方法。具体的性能提升幅度未知,但摘要中强调了“显著优于”,表明DyMo在各种缺失数据场景下都具有竞争力。实验结果验证了DyMo框架的有效性和鲁棒性。
🎯 应用场景
该研究成果可应用于医学图像诊断、自动驾驶、情感识别等领域。在这些领域中,多模态数据经常存在缺失或不完整的情况。DyMo框架能够有效地利用不完整的多模态数据,提高分类精度和鲁棒性,具有重要的实际应用价值。未来,该方法可以进一步扩展到其他多模态学习任务,例如多模态检索和多模态生成。
📄 摘要(原文)
Multimodal deep learning (MDL) has achieved remarkable success across various domains, yet its practical deployment is often hindered by incomplete multimodal data. Existing incomplete MDL methods either discard missing modalities, risking the loss of valuable task-relevant information, or recover them, potentially introducing irrelevant noise, leading to the discarding-imputation dilemma. To address this dilemma, in this paper, we propose DyMo, a new inference-time dynamic modality selection framework that adaptively identifies and integrates reliable recovered modalities, fully exploring task-relevant information beyond the conventional discard-or-impute paradigm. Central to DyMo is a novel selection algorithm that maximizes multimodal task-relevant information for each test sample. Since direct estimation of such information at test time is intractable due to the unknown data distribution, we theoretically establish a connection between information and the task loss, which we compute at inference time as a tractable proxy. Building on this, a novel principled reward function is proposed to guide modality selection. In addition, we design a flexible multimodal network architecture compatible with arbitrary modality combinations, alongside a tailored training strategy for robust representation learning. Extensive experiments on diverse natural and medical image datasets show that DyMo significantly outperforms state-of-the-art incomplete/dynamic MDL methods across various missing-data scenarios. Our code is available at https://github.com//siyi-wind/DyMo.