StreamSense: Streaming Social Task Detection with Selective Vision-Language Model Routing
作者: Han Wang, Deyi Ji, Lanyun Zhu, Jiebo Luo, Roy Ka-Wei Lee
分类: cs.CV
发布日期: 2026-01-30
备注: 10 pages, 4 figures, The Web Conference 2026
💡 一句话要点
StreamSense:基于选择性VLM路由的流式社交任务检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 流媒体分析 社交任务检测 视觉-语言模型 选择性路由 实时处理
📋 核心要点
- 现有方法难以兼顾流媒体平台实时性和准确性需求,尤其是在处理复杂社交信号时。
- StreamSense通过轻量级编码器处理常规情况,并将困难样本选择性地路由到VLM专家,实现效率与精度的平衡。
- 实验表明,StreamSense在多个社交流媒体任务中,以更低的延迟和计算成本,实现了比纯VLM方案更高的准确率。
📝 摘要(中文)
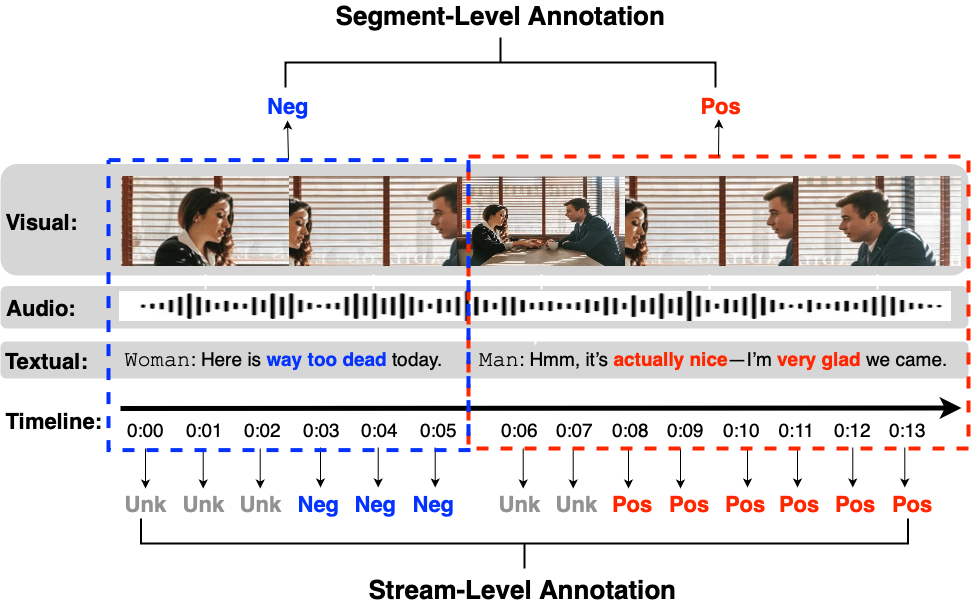
实时流媒体平台需要对来自视频、文本和音频的部分和异步证据进行实时监控和响应。我们提出了StreamSense,一个流式检测器,它将轻量级流式编码器与选择性路由到视觉-语言模型(VLM)专家相结合。StreamSense使用轻量级流式编码器处理大多数时间戳,将困难/模糊的情况升级到VLM,并在上下文不足时推迟决策。该编码器使用(i)跨模态对比项来对齐视觉/音频线索与文本信号,以及(ii)IoU加权损失来降低不良重叠目标片段的权重,从而减轻片段边界上的标签干扰进行训练。我们在多个社交流媒体检测任务(例如,情感分类和仇恨内容审核)上评估StreamSense,结果表明,StreamSense实现了比仅VLM流媒体更高的准确性,同时仅偶尔调用VLM,从而降低了平均延迟和计算成本。我们的结果表明,选择性升级和延迟是理解流式社交任务的有效原语。代码已在GitHub上公开。
🔬 方法详解
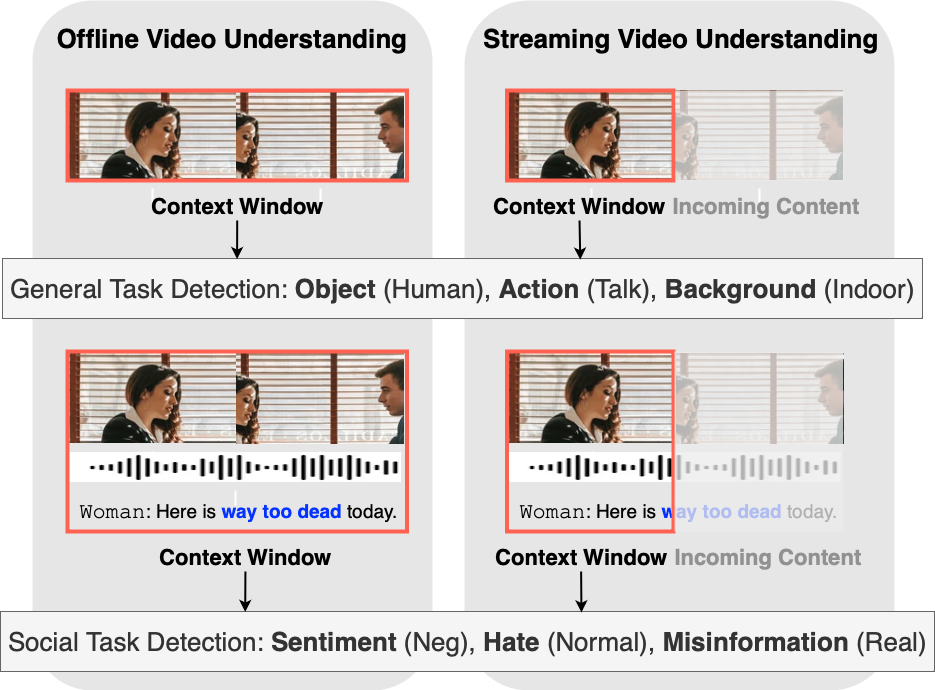
问题定义:现有流媒体社交任务检测方法通常面临计算资源和延迟的挑战。直接使用大型视觉-语言模型(VLM)进行实时处理成本过高,而轻量级模型在处理复杂或模糊的社交信号时精度不足。因此,如何在保证实时性的前提下,提高流媒体社交任务检测的准确率是一个关键问题。
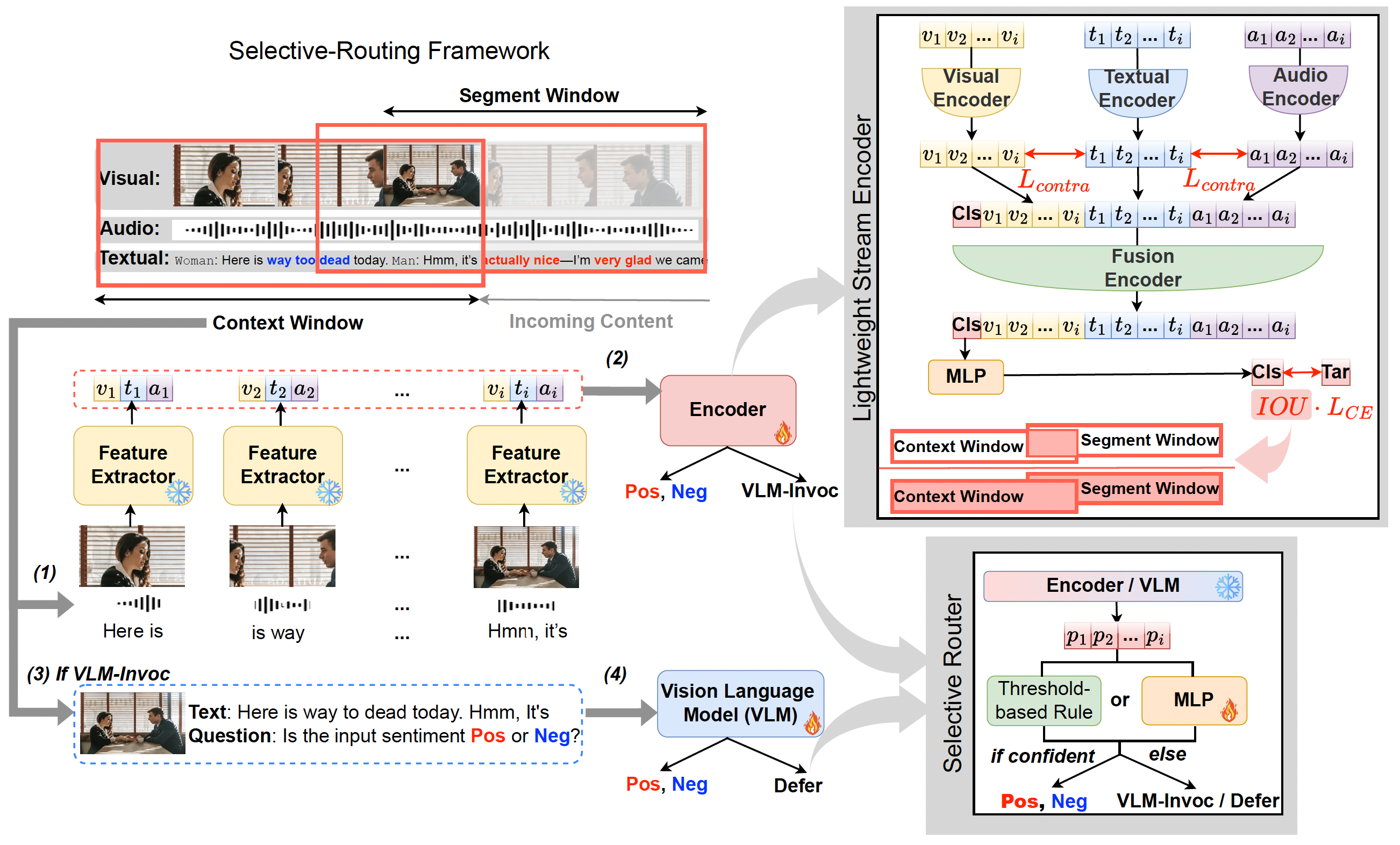
核心思路:StreamSense的核心思路是采用一种选择性路由机制,将计算资源分配给最需要的部分。它使用一个轻量级的流式编码器处理大部分简单情况,只有当遇到困难或模糊的样本时,才将它们路由到计算量更大的VLM专家进行处理。此外,StreamSense还支持延迟决策,即在上下文信息不足时,暂时推迟判断,等待更多信息后再做决定。
技术框架:StreamSense的整体架构包含三个主要模块:1) 轻量级流式编码器:用于快速处理输入流,提取初步特征。2) 选择性路由机制:根据编码器的输出,判断是否需要将样本路由到VLM专家。3) VLM专家:用于处理困难或模糊的样本,提供更准确的预测。此外,系统还包含一个决策延迟机制,用于在信息不足时推迟决策。
关键创新:StreamSense的关键创新在于其选择性路由机制和决策延迟机制。选择性路由机制能够根据样本的难易程度,动态地分配计算资源,从而在保证实时性的前提下,提高整体准确率。决策延迟机制则能够处理上下文信息不足的情况,避免过早做出错误的判断。
关键设计:StreamSense的训练过程包含两个关键的损失函数:1) 跨模态对比损失:用于对齐视觉/音频线索与文本信号,提高编码器的跨模态理解能力。2) IoU加权损失:用于降低不良重叠目标片段的权重,减轻片段边界上的标签干扰。此外,选择性路由机制的阈值需要根据具体任务进行调整,以平衡计算成本和准确率。
🖼️ 关键图片
📊 实验亮点
StreamSense在多个社交流媒体检测任务上进行了评估,包括情感分类和仇恨内容审核。实验结果表明,StreamSense在保持较低延迟和计算成本的同时,实现了比仅使用VLM更高的准确率。具体而言,StreamSense仅偶尔调用VLM,但仍能取得优于VLM-only streaming的性能,证明了选择性升级和延迟策略的有效性。
🎯 应用场景
StreamSense可应用于各种实时流媒体平台,用于情感分析、仇恨言论检测、事件检测等社交任务。该技术能够帮助平台更有效地监控和管理内容,提升用户体验,并及时响应突发事件。未来,StreamSense还可扩展到其他需要实时处理多模态数据的场景,如智能监控、自动驾驶等。
📄 摘要(原文)
Live streaming platforms require real-time monitoring and reaction to social signals, utilizing partial and asynchronous evidence from video, text, and audio. We propose StreamSense, a streaming detector that couples a lightweight streaming encoder with selective routing to a Vision-Language Model (VLM) expert. StreamSense handles most timestamps with the lightweight streaming encoder, escalates hard/ambiguous cases to the VLM, and defers decisions when context is insufficient. The encoder is trained using (i) a cross-modal contrastive term to align visual/audio cues with textual signals, and (ii) an IoU-weighted loss that down-weights poorly overlapping target segments, mitigating label interference across segment boundaries. We evaluate StreamSense on multiple social streaming detection tasks (e.g., sentiment classification and hate content moderation), and the results show that StreamSense achieves higher accuracy than VLM-only streaming while only occasionally invoking the VLM, thereby reducing average latency and compute. Our results indicate that selective escalation and deferral are effective primitives for understanding streaming social tasks. Code is publicly available on GitHub.