ExpAlign: Expectation-Guided Vision-Language Alignment for Open-Vocabulary Grounding
作者: Junyi Hu, Tian Bai, Fengyi Wu, Wenyan Li, Zhenming Peng, Yi Zhang
分类: cs.CV
发布日期: 2026-01-30
备注: 20 pages, 6 figures
💡 一句话要点
提出ExpAlign以解决开放词汇基础上的视觉-语言对齐问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇 视觉-语言对齐 多实例学习 零-shot学习 能量基正则化
📋 核心要点
- 现有方法在开放词汇基础上进行视觉-语言对齐时,常常依赖于全局句子嵌入,缺乏细粒度的表达能力。
- ExpAlign通过引入期望对齐头,利用注意力机制进行软多实例池化,实现隐式的标记和实例选择,避免了额外的标注需求。
- 在实验中,ExpAlign在LVIS minival分割上取得了36.2 AP_r的成绩,超越了其他同类方法,同时保持轻量和高效的推理性能。
📝 摘要(中文)
开放词汇基础上的对齐需要在弱监督下实现准确的视觉-语言对齐,然而现有方法要么依赖缺乏细粒度表达能力的全局句子嵌入,要么引入显式监督或复杂的交叉注意力设计。我们提出了ExpAlign,这是一个基于理论的视觉-语言对齐框架,建立在原则性的多实例学习公式上。ExpAlign引入了期望对齐头,通过基于注意力的软多实例池化来处理标记-区域相似性,实现隐式的标记和实例选择,无需额外注释。为了进一步稳定对齐学习,我们开发了一种基于能量的多尺度一致性正则化方案,包括Top-K多正样本对比目标和基于拉格朗日约束的自由能量最小化推导的几何感知一致性目标。大量实验表明,ExpAlign在开放词汇检测和零-shot实例分割上持续改善,尤其是在长尾类别上。
🔬 方法详解
问题定义:本论文旨在解决开放词汇基础上的视觉-语言对齐问题,现有方法在处理细粒度信息时存在不足,尤其是在弱监督条件下。
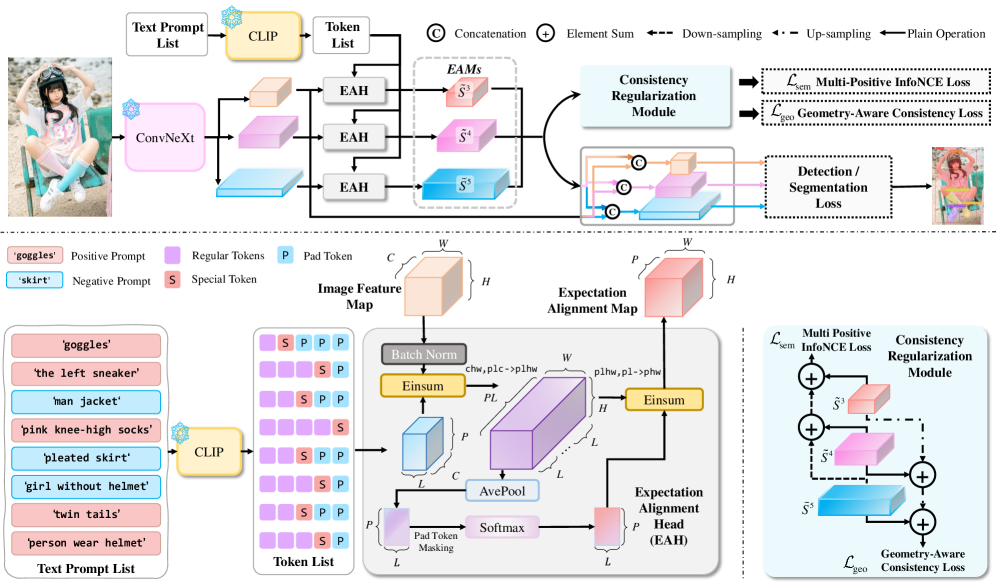
核心思路:我们提出的ExpAlign框架基于多实例学习,通过期望对齐头实现隐式的标记和实例选择,避免了对显式监督的依赖。
技术框架:ExpAlign的整体架构包括期望对齐头和能量基多尺度一致性正则化模块,前者负责处理标记-区域相似性,后者则用于稳定对齐学习。
关键创新:ExpAlign的主要创新在于引入了期望对齐头和基于能量的多尺度一致性正则化,这些设计使得模型在无额外注释的情况下实现了更好的对齐效果。
关键设计:在损失函数设计上,我们采用了Top-K多正样本对比目标和几何感知一致性目标,确保模型在不同尺度上保持一致性,同时优化了计算效率。
🖼️ 关键图片


📊 实验亮点
ExpAlign在开放词汇检测和零-shot实例分割任务中表现优异,特别是在长尾类别上,取得了36.2 AP_r的成绩,显著超越了其他最先进的方法,且在模型规模相当的情况下保持了轻量和高效的推理能力。
🎯 应用场景
该研究的潜在应用领域包括开放词汇的视觉识别、图像分割和多模态学习等。通过提高视觉-语言对齐的准确性,ExpAlign能够在实际场景中更好地支持智能助手、自动标注和人机交互等应用,未来可能推动相关技术的广泛应用和发展。
📄 摘要(原文)
Open-vocabulary grounding requires accurate vision-language alignment under weak supervision, yet existing methods either rely on global sentence embeddings that lack fine-grained expressiveness or introduce token-level alignment with explicit supervision or heavy cross-attention designs. We propose ExpAlign, a theoretically grounded vision-language alignment framework built on a principled multiple instance learning formulation. ExpAlign introduces an Expectation Alignment Head that performs attention-based soft MIL pooling over token-region similarities, enabling implicit token and instance selection without additional annotations. To further stabilize alignment learning, we develop an energy-based multi-scale consistency regularization scheme, including a Top-K multi-positive contrastive objective and a Geometry-Aware Consistency Objective derived from a Lagrangian-constrained free-energy minimization. Extensive experiments show that ExpAlign consistently improves open-vocabulary detection and zero-shot instance segmentation, particularly on long-tail categories. Most notably, it achieves 36.2 AP$_r$ on the LVIS minival split, outperforming other state-of-the-art methods at comparable model scale, while remaining lightweight and inference-efficient.