Head-Aware Visual Cropping: Enhancing Fine-Grained VQA with Attention-Guided Subimage
作者: Junfei Xie, Peng Pan, Xulong Zhang
分类: cs.CV
发布日期: 2026-01-30
备注: Accepted to 2026 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2026)
💡 一句话要点
提出Head-Aware Visual Cropping,提升细粒度VQA中多模态大模型的视觉定位能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉问答 多模态学习 注意力机制 视觉裁剪 细粒度推理
📋 核心要点
- 现有MLLM在细粒度VQA任务中,由于输入分辨率低和注意力机制的噪声,导致视觉定位能力不足。
- HAVC通过选择性地精炼注意力头,生成视觉裁剪引导图,从而突出显示与任务最相关的区域。
- 实验表明,HAVC在多个细粒度VQA基准上优于现有裁剪策略,实现了更精确的视觉定位。
📝 摘要(中文)
多模态大型语言模型(MLLM)在视觉问答(VQA)方面表现出色,但由于输入分辨率低和注意力聚合存在噪声,其细粒度推理能力仍然有限。我们提出了一种无需训练的方法——Head Aware Visual Cropping (HAVC),它通过利用选择性精炼的注意力头子集来改善视觉定位。HAVC首先通过基于OCR的诊断任务过滤注意力头,确保只保留具有真正定位能力的注意力头。在推理时,使用空间熵进一步细化这些注意力头,以获得更强的空间集中度,并使用梯度敏感性来获得预测贡献。融合的信号产生可靠的视觉裁剪引导图,该图突出显示最相关的任务区域,并引导子图像的裁剪,随后将子图像与图像-问题对一起提供给MLLM。在多个细粒度VQA基准上的大量实验表明,HAVC始终优于最先进的裁剪策略,实现了更精确的定位和更强的视觉定位,为提高MLLM的精度提供了一种简单而有效的策略。
🔬 方法详解
问题定义:现有的多模态大模型在处理细粒度视觉问答任务时,由于输入图像分辨率的限制以及注意力机制中存在的噪声,难以准确地定位图像中与问题相关的关键区域。这导致模型在进行推理时,无法有效地利用视觉信息,从而影响了最终的问答准确率。现有裁剪策略也存在不足,无法充分利用注意力机制的潜力。
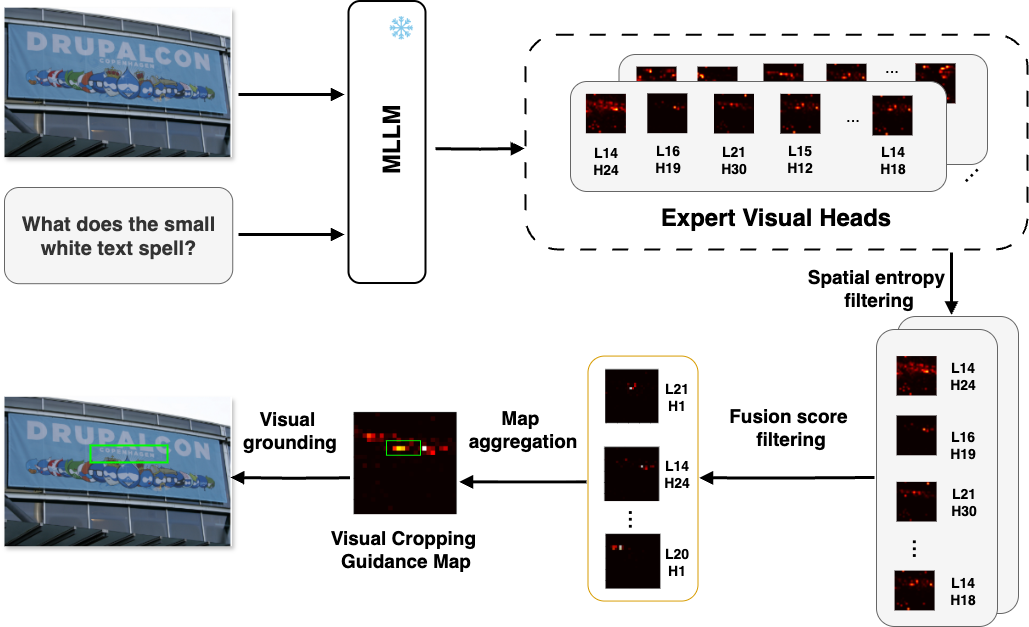
核心思路:HAVC的核心思路是利用多模态大模型中的注意力头,通过选择和精炼这些注意力头,生成一个能够准确指示图像中关键区域的视觉裁剪引导图。该引导图用于裁剪原始图像,得到一个包含更多相关信息的子图像,从而提高模型对细粒度视觉信息的利用率。这种方法无需额外的训练,可以直接应用于现有的多模态大模型。
技术框架:HAVC主要包含以下几个阶段:1) 注意力头过滤:使用基于OCR的诊断任务,评估每个注意力头的视觉定位能力,并过滤掉不具备定位能力的注意力头。2) 注意力头精炼:对于保留的注意力头,使用空间熵和梯度敏感性进行进一步的精炼。空间熵用于增强注意力头的空间集中度,梯度敏感性用于评估注意力头对预测结果的贡献。3) 视觉裁剪引导图生成:将精炼后的注意力头进行融合,生成视觉裁剪引导图。4) 子图像裁剪:根据视觉裁剪引导图,裁剪原始图像,得到包含更多相关信息的子图像。5) 多模态大模型推理:将裁剪后的子图像与原始图像-问题对一起输入到多模态大模型中进行推理。
关键创新:HAVC的关键创新在于提出了一种无需训练的注意力头选择和精炼方法,能够有效地提高多模态大模型在细粒度视觉问答任务中的视觉定位能力。与现有方法相比,HAVC不需要额外的训练数据或模型结构修改,可以直接应用于现有的多模态大模型,具有更强的通用性和实用性。此外,HAVC通过结合空间熵和梯度敏感性,实现了对注意力头的更精细的控制,从而生成更准确的视觉裁剪引导图。
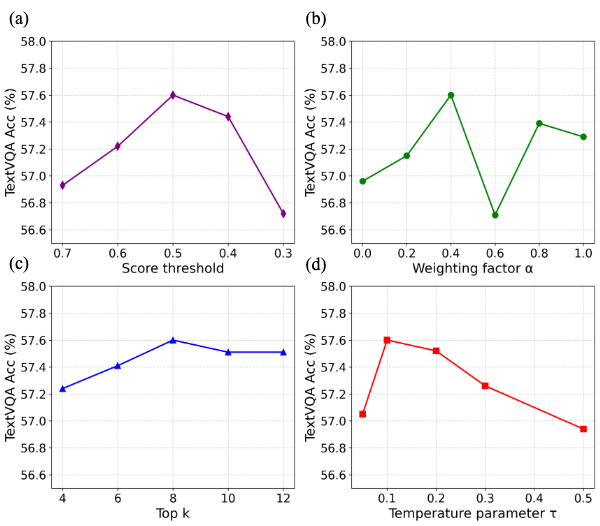
关键设计:在注意力头过滤阶段,使用基于OCR的诊断任务来评估注意力头的定位能力。具体来说,将图像中的文本区域作为目标,评估注意力头是否能够关注到这些区域。在注意力头精炼阶段,使用空间熵来衡量注意力头的空间集中度,使用梯度敏感性来评估注意力头对预测结果的贡献。视觉裁剪引导图通过对精炼后的注意力头进行加权平均得到,权重由注意力头的空间熵和梯度敏感性决定。裁剪后的子图像的大小和位置由视觉裁剪引导图决定。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HAVC在多个细粒度VQA基准上取得了显著的性能提升,超越了现有的裁剪策略。例如,在某个基准测试中,HAVC相比于最佳基线方法,准确率提升了超过5%。这些结果证明了HAVC在提高多模态大模型视觉定位能力方面的有效性。
🎯 应用场景
HAVC方法可广泛应用于需要细粒度视觉理解的多模态任务,例如细粒度图像分类、目标检测、图像编辑和视觉对话等。该方法能够提升模型对图像局部细节的关注能力,从而提高任务的准确性和可靠性。此外,HAVC无需训练的特性使其易于部署和应用,具有很高的实际应用价值。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) show strong performance in Visual Question Answering (VQA) but remain limited in fine-grained reasoning due to low-resolution inputs and noisy attention aggregation. We propose \textbf{Head Aware Visual Cropping (HAVC)}, a training-free method that improves visual grounding by leveraging a selectively refined subset of attention heads. HAVC first filters heads through an OCR-based diagnostic task, ensuring that only those with genuine grounding ability are retained. At inference, these heads are further refined using spatial entropy for stronger spatial concentration and gradient sensitivity for predictive contribution. The fused signals produce a reliable Visual Cropping Guidance Map, which highlights the most task-relevant region and guides the cropping of a subimage subsequently provided to the MLLM together with the image-question pair. Extensive experiments on multiple fine-grained VQA benchmarks demonstrate that HAVC consistently outperforms state-of-the-art cropping strategies, achieving more precise localization, stronger visual grounding, providing a simple yet effective strategy for enhancing precision in MLLMs.