Training-Free Representation Guidance for Diffusion Models with a Representation Alignment Projector
作者: Wenqiang Zu, Shenghao Xie, Bo Lei, Lei Ma
分类: cs.CV, cs.AI
发布日期: 2026-01-30
💡 一句话要点
提出基于表征对齐投影的无训练扩散模型引导方法,提升图像生成质量。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 扩散模型 图像生成 表征学习 语义引导 无监督学习
📋 核心要点
- 扩散模型推理时引导方法未能充分利用无监督特征表示,导致语义对齐不佳。
- 提出一种基于表征对齐投影器的引导方案,在采样过程中注入语义锚点,无需修改模型架构。
- 实验表明,该方法显著降低了类条件ImageNet合成的FID分数,并能与无分类器引导互补。
📝 摘要(中文)
扩散模型在高质量图像合成方面取得了显著进展,支持可控采样和大规模训练。诸如无分类器引导和代表性引导等推理时引导方法通过修改采样动态来增强语义对齐;然而,它们并未充分利用无监督特征表示。尽管这些视觉表示包含丰富的语义结构,但在生成过程中的整合受到推理时缺乏真实参考图像的限制。本研究揭示了扩散Transformer早期去噪阶段的语义漂移现象,即使在相同条件下,随机性也会导致不一致的对齐。为了缓解这个问题,我们引入了一种使用表征对齐投影器的引导方案,将投影器预测的表征注入到中间采样步骤中,从而提供有效的语义锚点,而无需修改模型架构。在SiTs和REPAs上的实验表明,在类条件ImageNet合成方面取得了显著改进,实现了显著降低的FID分数;例如,REPA-XL/2从5.9提高到3.3,并且该方法在应用于SiT模型时优于代表性引导。该方法与无分类器引导结合使用时,可产生互补的增益,从而增强语义连贯性和视觉保真度。这些结果确立了表征引导的扩散采样作为增强语义保持和图像一致性的实用策略。
🔬 方法详解
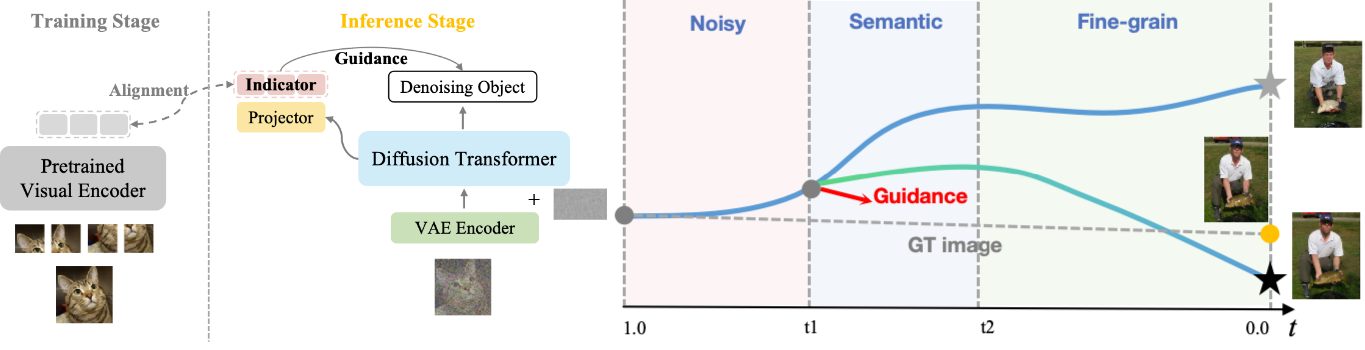
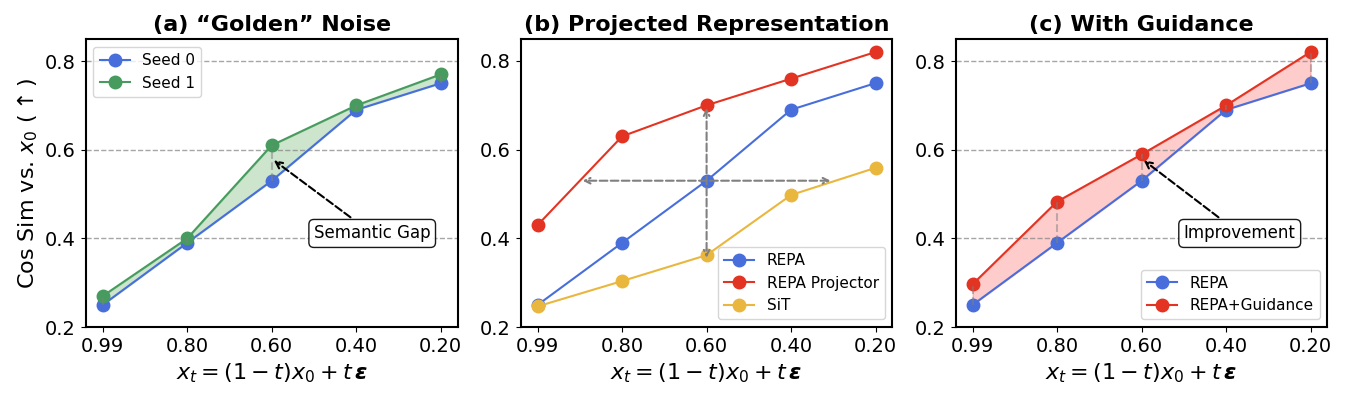
问题定义:扩散模型在图像生成任务中,虽然取得了显著进展,但推理时的引导方法(如无分类器引导)未能充分利用图像的无监督特征表示。这些特征表示蕴含丰富的语义信息,但由于缺乏ground-truth参考图像,难以在生成过程中有效整合,导致生成图像出现语义漂移,尤其是在扩散过程的早期阶段。现有方法无法保证生成图像与期望语义的一致性。
核心思路:本论文的核心思路是利用一个“表征对齐投影器”,将图像的无监督特征表示注入到扩散模型的中间采样步骤中,从而为生成过程提供一个语义锚点。通过在去噪过程中不断地将生成图像的特征与投影器预测的特征对齐,可以有效抑制语义漂移,提高生成图像的语义一致性和视觉保真度。这种方法无需修改扩散模型的原始架构,易于集成。
技术框架:该方法主要包含以下几个模块:1) 预训练的扩散模型(如SiT或REPA);2) 表征提取器:用于提取生成图像的无监督特征表示;3) 表征对齐投影器:将提取的特征投影到与扩散模型中间层特征空间对齐的空间;4) 引导模块:在扩散模型的中间采样步骤中,将投影后的特征注入到模型中,引导生成过程。整个流程是在推理阶段进行的,不需要重新训练扩散模型。
关键创新:该方法最重要的创新点在于提出了“表征对齐投影器”的概念,并将其应用于扩散模型的引导过程。与传统的引导方法(如无分类器引导)相比,该方法能够更有效地利用图像的无监督特征表示,从而提高生成图像的语义一致性。此外,该方法无需修改扩散模型的原始架构,具有良好的通用性和可扩展性。
关键设计:表征对齐投影器的具体实现方式未知,论文中可能使用了某种神经网络结构(如MLP或Transformer)来实现特征的投影和对齐。损失函数的设计也至关重要,可能使用了对比学习或相似性度量等方法来保证投影后的特征与扩散模型中间层特征的对齐。具体的参数设置和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在类条件ImageNet图像合成任务中取得了显著的性能提升。例如,在REPA-XL/2模型上,使用该方法后,FID分数从5.9降低到3.3,表明生成图像的质量和多样性得到了显著提高。此外,该方法在应用于SiT模型时,优于代表性引导方法。与无分类器引导结合使用时,可以获得互补的增益,进一步提高生成图像的语义连贯性和视觉保真度。
🎯 应用场景
该研究成果可广泛应用于图像生成、图像编辑、图像修复等领域。例如,可以用于生成具有特定语义属性的高质量图像,也可以用于对现有图像进行语义编辑,例如改变图像中物体的类别或属性。此外,该方法还可以应用于视频生成和三维内容生成等领域,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Recent progress in generative modeling has enabled high-quality visual synthesis with diffusion-based frameworks, supporting controllable sampling and large-scale training. Inference-time guidance methods such as classifier-free and representative guidance enhance semantic alignment by modifying sampling dynamics; however, they do not fully exploit unsupervised feature representations. Although such visual representations contain rich semantic structure, their integration during generation is constrained by the absence of ground-truth reference images at inference. This work reveals semantic drift in the early denoising stages of diffusion transformers, where stochasticity results in inconsistent alignment even under identical conditioning. To mitigate this issue, we introduce a guidance scheme using a representation alignment projector that injects representations predicted by a projector into intermediate sampling steps, providing an effective semantic anchor without modifying the model architecture. Experiments on SiTs and REPAs show notable improvements in class-conditional ImageNet synthesis, achieving substantially lower FID scores; for example, REPA-XL/2 improves from 5.9 to 3.3, and the proposed method outperforms representative guidance when applied to SiT models. The approach further yields complementary gains when combined with classifier-free guidance, demonstrating enhanced semantic coherence and visual fidelity. These results establish representation-informed diffusion sampling as a practical strategy for reinforcing semantic preservation and image consistency.