MetricAnything: Scaling Metric Depth Pretraining with Noisy Heterogeneous Sources
作者: Baorui Ma, Jiahui Yang, Donglin Di, Xuancheng Zhang, Jianxun Cui, Hao Li, Yan Xie, Wei Chen
分类: cs.CV, cs.AI
发布日期: 2026-01-29
备注: Project Page: https://metric-anything.github.io/metric-anything-io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MetricAnything:利用噪声异构数据源扩展度量深度预训练
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 度量深度估计 预训练 稀疏提示 多模态学习 视觉基础模型
📋 核心要点
- 现有度量深度估计方法难以处理异构传感器噪声和相机偏差,限制了模型在真实场景中的泛化能力。
- MetricAnything通过引入稀疏度量提示,解耦空间推理与传感器和相机偏差,实现从大规模噪声数据中学习度量深度。
- 实验表明,预训练模型在多种下游任务上表现出色,并且可以提升多模态大型语言模型在空间智能方面的能力。
📝 摘要(中文)
由于异构传感器噪声、相机相关的偏差以及噪声跨源3D数据中的度量模糊性,扩展视觉基础模型到度量深度估计仍然具有挑战。我们提出了Metric Anything,一个简单且可扩展的预训练框架,可以从噪声、多样化的3D源中学习度量深度,而无需手动设计的提示、相机特定的建模或任务特定的架构。我们方法的关键是稀疏度量提示,通过随机掩蔽深度图创建,它作为一个通用接口,将空间推理与传感器和相机偏差解耦。使用跨越10000个相机模型的约2000万图像-深度对,涵盖重建、捕获和渲染的3D数据,我们首次展示了度量深度轨迹中清晰的缩放趋势。预训练模型擅长提示驱动的任务,如深度补全、超分辨率和雷达-相机融合,而其蒸馏的无提示学生模型在单目深度估计、相机内参恢复、单/多视图度量3D重建和VLA规划方面实现了最先进的结果。我们还表明,使用Metric Anything的预训练ViT作为视觉编码器可以显著提高多模态大型语言模型在空间智能方面的能力。这些结果表明,度量深度估计可以受益于驱动现代基础模型的相同缩放定律,从而为可扩展和高效的真实世界度量感知建立了一条新途径。我们开源了MetricAnything,以支持社区研究。
🔬 方法详解
问题定义:现有的度量深度估计方法在处理来自不同传感器和相机的数据时,面临着严重的挑战。不同传感器具有不同的噪声特性,而不同相机则存在固有的偏差。此外,跨源3D数据中还存在度量模糊性,这些因素都阻碍了模型在真实世界场景中的泛化能力。现有方法通常需要手动设计的提示或相机特定的建模,这限制了其可扩展性和适用性。
核心思路:MetricAnything的核心思路是利用大规模的、带有噪声的异构3D数据进行预训练,并通过稀疏度量提示来解耦空间推理与传感器和相机偏差。通过随机掩蔽深度图,生成稀疏度量提示,迫使模型学习从局部信息推断全局结构,从而提高模型的鲁棒性和泛化能力。这种方法避免了手动设计提示和相机特定建模的需要,使得模型可以更容易地适应不同的数据源。
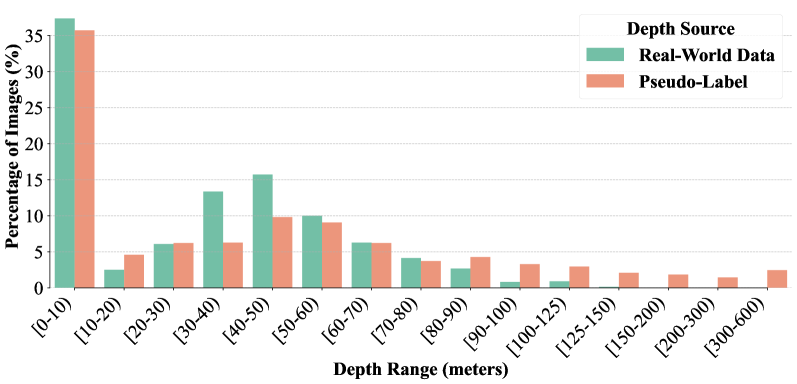
技术框架:MetricAnything的整体框架包括数据收集、预训练和下游任务应用三个主要阶段。首先,收集来自不同来源的约2000万图像-深度对,涵盖重建、捕获和渲染的3D数据。然后,使用这些数据对模型进行预训练,采用稀疏度量提示作为输入。预训练完成后,可以将模型直接应用于各种下游任务,如深度补全、超分辨率和雷达-相机融合。此外,还可以将预训练模型蒸馏成一个无提示的学生模型,用于单目深度估计、相机内参恢复和3D重建等任务。
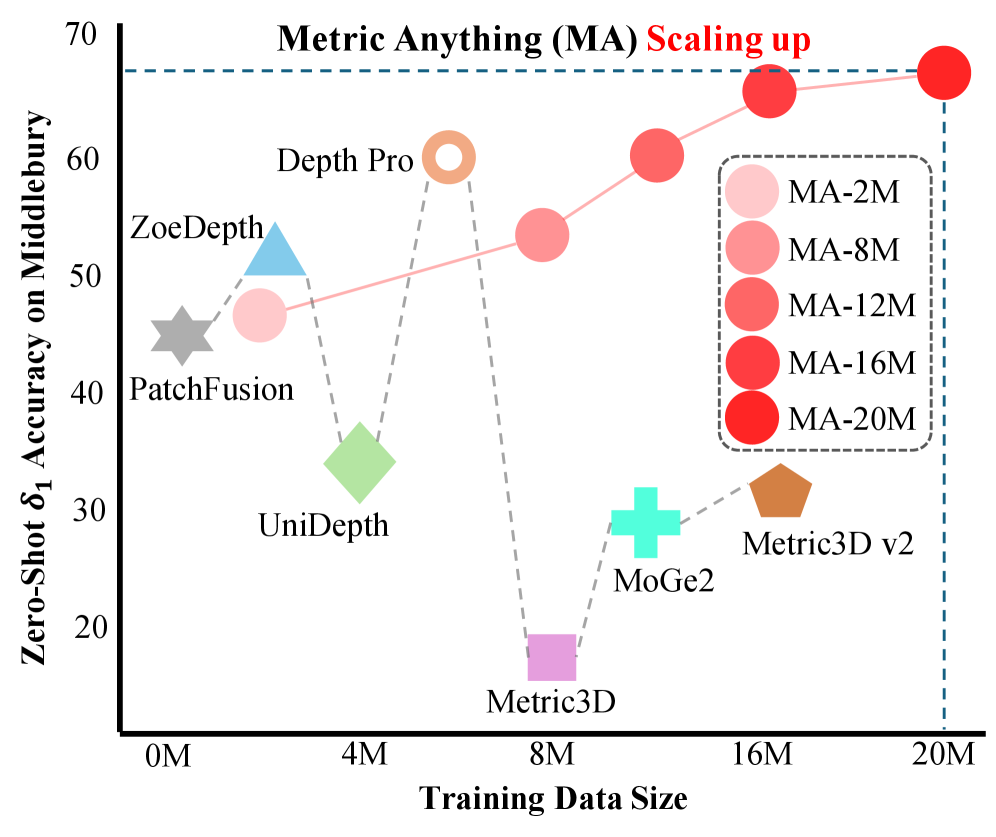
关键创新:MetricAnything最重要的技术创新点是稀疏度量提示。通过随机掩蔽深度图,生成稀疏度量提示,迫使模型学习从局部信息推断全局结构,从而提高模型的鲁棒性和泛化能力。与现有方法相比,稀疏度量提示不需要手动设计提示或相机特定建模,使得模型可以更容易地适应不同的数据源。此外,MetricAnything还展示了度量深度估计中清晰的缩放趋势,表明可以通过增加数据量来提高模型的性能。
关键设计:MetricAnything的关键设计包括:1) 大规模异构数据集的构建,涵盖了各种不同的传感器和相机模型;2) 稀疏度量提示的生成,通过随机掩蔽深度图实现;3) 基于Transformer的模型架构,能够有效地学习空间关系;4) 蒸馏训练,将预训练模型的知识迁移到更小的学生模型中,提高模型的效率。
🖼️ 关键图片

📊 实验亮点
MetricAnything在多个下游任务上取得了显著的性能提升。例如,在单目深度估计任务上,其蒸馏的无提示学生模型达到了最先进的结果。此外,使用MetricAnything的预训练ViT作为视觉编码器,可以显著提高多模态大型语言模型在空间智能方面的能力。实验结果表明,度量深度估计可以受益于与现代基础模型相同的缩放定律。
🎯 应用场景
MetricAnything在机器人导航、自动驾驶、增强现实和虚拟现实等领域具有广泛的应用前景。它可以用于提高机器人对周围环境的感知能力,帮助自动驾驶车辆进行精确的场景理解,以及为AR/VR应用提供更逼真的3D场景重建。此外,该研究还可以促进多模态大型语言模型在空间智能方面的发展。
📄 摘要(原文)
Scaling has powered recent advances in vision foundation models, yet extending this paradigm to metric depth estimation remains challenging due to heterogeneous sensor noise, camera-dependent biases, and metric ambiguity in noisy cross-source 3D data. We introduce Metric Anything, a simple and scalable pretraining framework that learns metric depth from noisy, diverse 3D sources without manually engineered prompts, camera-specific modeling, or task-specific architectures. Central to our approach is the Sparse Metric Prompt, created by randomly masking depth maps, which serves as a universal interface that decouples spatial reasoning from sensor and camera biases. Using about 20M image-depth pairs spanning reconstructed, captured, and rendered 3D data across 10000 camera models, we demonstrate-for the first time-a clear scaling trend in the metric depth track. The pretrained model excels at prompt-driven tasks such as depth completion, super-resolution and Radar-camera fusion, while its distilled prompt-free student achieves state-of-the-art results on monocular depth estimation, camera intrinsics recovery, single/multi-view metric 3D reconstruction, and VLA planning. We also show that using pretrained ViT of Metric Anything as a visual encoder significantly boosts Multimodal Large Language Model capabilities in spatial intelligence. These results show that metric depth estimation can benefit from the same scaling laws that drive modern foundation models, establishing a new path toward scalable and efficient real-world metric perception. We open-source MetricAnything at http://metric-anything.github.io/metric-anything-io/ to support community research.