Drive-JEPA: Video JEPA Meets Multimodal Trajectory Distillation for End-to-End Driving
作者: Linhan Wang, Zichong Yang, Chen Bai, Guoxiang Zhang, Xiaotong Liu, Xiaoyin Zheng, Xiao-Xiao Long, Chang-Tien Lu, Cheng Lu
分类: cs.CV
发布日期: 2026-01-29
💡 一句话要点
Drive-JEPA:融合视频JEPA与多模态轨迹蒸馏的端到端自动驾驶框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 端到端自动驾驶 自监督学习 视频预训练 轨迹蒸馏 多模态学习 V-JEPA Transformer
📋 核心要点
- 现有端到端自动驾驶方法在利用视频预训练学习规划表征时,面临场景理解能力提升有限以及驾驶行为多模态性难以学习的挑战。
- Drive-JEPA通过结合V-JEPA的视频表征学习能力和多模态轨迹蒸馏,学习与轨迹规划对齐的预测表征,并融合多样化的驾驶行为。
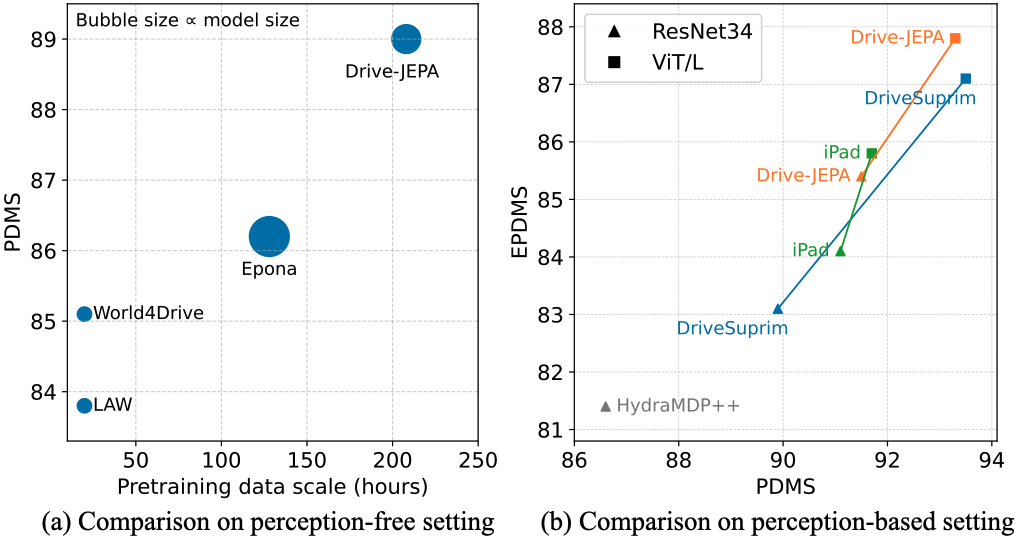
- 实验结果表明,Drive-JEPA在NAVSIM数据集上显著超越现有方法,在v1和v2版本上均取得了state-of-the-art的性能。
📝 摘要(中文)
端到端自动驾驶越来越多地利用自监督视频预训练来学习可迁移的规划表征。然而,用于场景理解的视频世界模型的预训练迄今为止只带来了有限的改进。这种限制因驾驶的内在模糊性而加剧:每个场景通常只提供一条人类轨迹,使得学习多模态行为变得困难。本文提出了Drive-JEPA,一个集成了视频联合嵌入预测架构(V-JEPA)与多模态轨迹蒸馏的端到端驾驶框架。首先,我们将V-JEPA适配于端到端驾驶,在大规模驾驶视频上预训练ViT编码器,以产生与轨迹规划对齐的预测表征。其次,我们引入了一个以提议为中心的规划器,它将模拟器生成的多样化轨迹与人类轨迹一起蒸馏,并采用一种具有动量感知的选择机制来促进稳定和安全的行为。在NAVSIM上的评估表明,V-JEPA表征结合一个简单的基于Transformer的解码器,在无感知设置下,性能超过了先前的方法3个PDMS。完整的Drive-JEPA框架在v1上实现了93.3 PDMS,在v2上实现了87.8 EPDMS,创造了新的state-of-the-art。
🔬 方法详解
问题定义:端到端自动驾驶旨在直接从传感器数据(如摄像头图像)预测车辆的控制指令。现有的方法在利用自监督学习从大规模驾驶视频中学习通用表征时,存在两个主要痛点:一是视频世界模型的预训练效果有限,难以充分理解复杂的驾驶场景;二是驾驶行为的内在模糊性,即同一场景下可能存在多种合理的驾驶轨迹,而现有方法通常只学习单一的人类轨迹,难以捕捉这种多模态性。
核心思路:Drive-JEPA的核心思路是结合视频联合嵌入预测架构(V-JEPA)的强大表征学习能力和多模态轨迹蒸馏,从而克服上述两个痛点。V-JEPA能够学习与轨迹规划对齐的预测表征,而多模态轨迹蒸馏则能够融合来自模拟器和人类驾驶员的多样化驾驶行为。
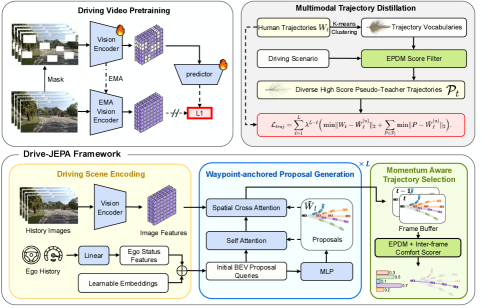
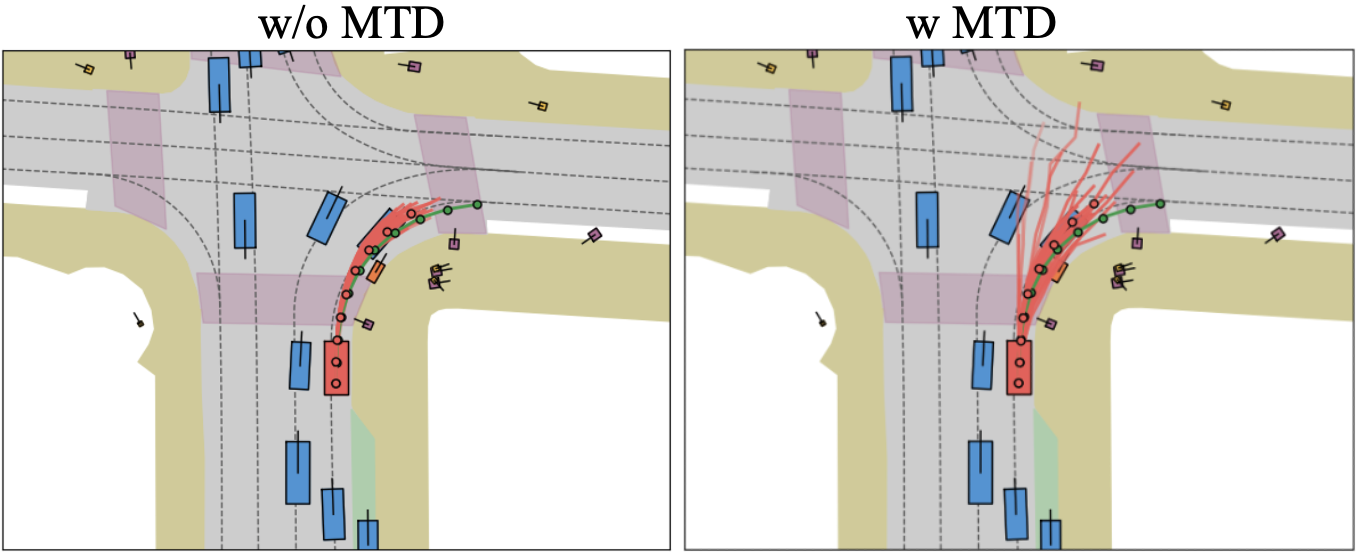
技术框架:Drive-JEPA框架主要包含两个阶段:预训练阶段和微调阶段。在预训练阶段,使用V-JEPA在大规模驾驶视频上训练一个ViT编码器,使其能够预测未来的视频帧。在微调阶段,将预训练的ViT编码器与一个基于Transformer的解码器结合,并使用多模态轨迹蒸馏来训练整个模型。多模态轨迹蒸馏涉及从模拟器生成多样化的轨迹,并使用一个动量感知的选择机制来选择稳定和安全的轨迹。
关键创新:Drive-JEPA的关键创新在于将V-JEPA和多模态轨迹蒸馏相结合,从而能够学习到更具表达力和泛化能力的驾驶表征。V-JEPA通过预测未来的视频帧来学习场景的动态特性,而多模态轨迹蒸馏则通过融合多样化的驾驶行为来提高模型的鲁棒性和安全性。与现有方法相比,Drive-JEPA能够更好地理解复杂的驾驶场景,并生成更合理和安全的驾驶轨迹。
关键设计:V-JEPA使用ViT作为编码器,并采用掩码预测的方式进行训练。多模态轨迹蒸馏使用一个以提议为中心的规划器,该规划器首先生成多个候选轨迹,然后使用一个动量感知的选择机制来选择最佳轨迹。动量感知的选择机制通过考虑过去轨迹的平滑性和安全性来选择轨迹,从而避免了突兀的控制指令变化。
🖼️ 关键图片
📊 实验亮点
Drive-JEPA在NAVSIM数据集上取得了显著的性能提升。在无感知设置下,仅使用V-JEPA表征结合Transformer解码器就超越了先前方法3个PDMS。完整的Drive-JEPA框架在v1版本上达到了93.3 PDMS,在v2版本上达到了87.8 EPDMS,刷新了state-of-the-art的性能记录,证明了该方法的有效性。
🎯 应用场景
Drive-JEPA具有广泛的应用前景,可用于提升自动驾驶系统的性能和安全性。该方法可以应用于各种自动驾驶场景,例如城市道路、高速公路和越野环境。此外,Drive-JEPA还可以用于训练更安全、更可靠的机器人,例如服务机器人和工业机器人。该研究的成果有助于推动自动驾驶技术的进一步发展,并为人们带来更安全、更便捷的出行体验。
📄 摘要(原文)
End-to-end autonomous driving increasingly leverages self-supervised video pretraining to learn transferable planning representations. However, pretraining video world models for scene understanding has so far brought only limited improvements. This limitation is compounded by the inherent ambiguity of driving: each scene typically provides only a single human trajectory, making it difficult to learn multimodal behaviors. In this work, we propose Drive-JEPA, a framework that integrates Video Joint-Embedding Predictive Architecture (V-JEPA) with multimodal trajectory distillation for end-to-end driving. First, we adapt V-JEPA for end-to-end driving, pretraining a ViT encoder on large-scale driving videos to produce predictive representations aligned with trajectory planning. Second, we introduce a proposal-centric planner that distills diverse simulator-generated trajectories alongside human trajectories, with a momentum-aware selection mechanism to promote stable and safe behavior. When evaluated on NAVSIM, the V-JEPA representation combined with a simple transformer-based decoder outperforms prior methods by 3 PDMS in the perception-free setting. The complete Drive-JEPA framework achieves 93.3 PDMS on v1 and 87.8 EPDMS on v2, setting a new state-of-the-art.