Causal World Modeling for Robot Control
作者: Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, Yinghao Xu
分类: cs.CV, cs.RO
发布日期: 2026-01-29
备注: Project page: https://technology.robbyant.com/lingbot-va Code: https://github.com/robbyant/lingbot-va
💡 一句话要点
LingBot-VA:基于因果世界模型的机器人控制框架,提升长时程操作和泛化能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人控制 世界模型 因果推理 自回归扩散模型 长时程操作 泛化能力 视频预测 混合Transformer
📋 核心要点
- 现有机器人学习方法在长时程任务和泛化性方面存在挑战,难以有效建模动作与环境变化之间的因果关系。
- LingBot-VA 采用自回归扩散模型,通过学习视频世界模型,预测未来帧,从而理解动作对环境的影响。
- 实验表明,LingBot-VA 在模拟和真实环境中均表现出优异的性能,尤其在长时程操作和泛化能力方面。
📝 摘要(中文)
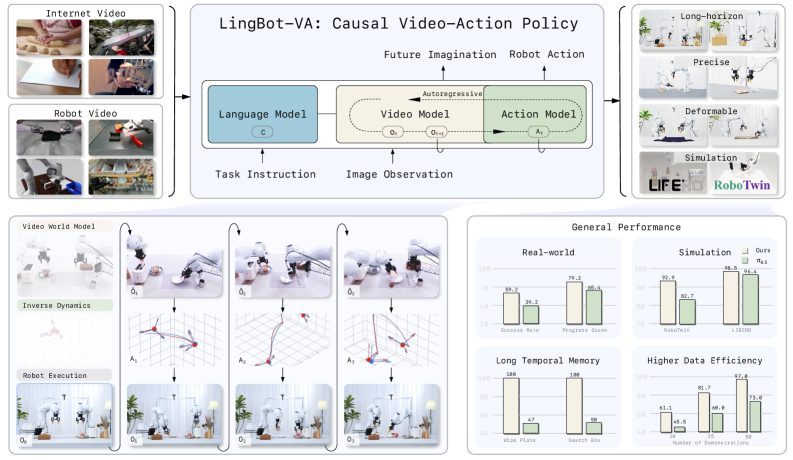
本研究强调,视频世界建模与视觉-语言预训练相结合,为机器人学习建立了一个全新的独立基础。直观地说,视频世界模型通过理解动作和视觉动态之间的因果关系,提供了预测近期未来的能力。受此启发,我们提出了 LingBot-VA,一个自回归扩散框架,可以同时学习帧预测和策略执行。我们的模型具有三个精心设计的特点:(1)一个共享的潜在空间,集成了视觉和动作 tokens,由混合Transformer(MoT)架构驱动;(2)一个闭环 rollout 机制,允许通过真实环境观测持续获取环境反馈;(3)一个异步推理流水线,并行化动作预测和电机执行,以支持高效控制。我们在模拟基准和真实场景中评估了我们的模型,结果表明它在长时程操作、后训练中的数据效率以及对新配置的强大泛化能力方面显示出巨大的潜力。代码和模型已公开提供,以方便社区使用。
🔬 方法详解
问题定义:现有机器人控制方法通常依赖于大量的真实世界数据,并且难以泛化到新的环境和任务。它们缺乏对动作与环境动态之间因果关系的有效建模,导致在长时程任务中表现不佳。此外,数据效率也是一个关键问题,尤其是在真实机器人应用中。
核心思路:LingBot-VA 的核心思路是利用视频世界模型来学习动作与视觉动态之间的因果关系。通过预测未来帧,模型能够“想象”动作的后果,从而做出更明智的决策。自回归扩散模型能够有效地捕捉视频中的复杂动态,并生成高质量的未来帧。
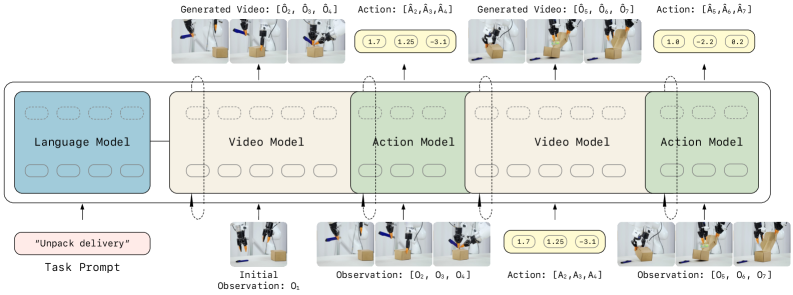
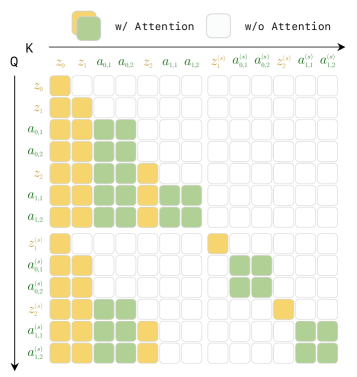
技术框架:LingBot-VA 的整体框架包括三个主要组成部分:共享潜在空间、闭环 rollout 机制和异步推理流水线。共享潜在空间使用混合Transformer(MoT)架构,将视觉和动作 tokens 集成到一个统一的表示中。闭环 rollout 机制允许模型在执行动作后,通过真实环境观测来更新其内部状态。异步推理流水线并行化动作预测和电机执行,从而提高控制效率。
关键创新:LingBot-VA 的关键创新在于将自回归扩散模型应用于机器人控制,并结合了共享潜在空间、闭环 rollout 机制和异步推理流水线。这种组合使得模型能够有效地学习动作与环境动态之间的因果关系,并在长时程任务和泛化能力方面取得显著提升。与现有方法相比,LingBot-VA 更加数据高效,并且能够更好地适应新的环境和任务。
关键设计:共享潜在空间中的混合Transformer(MoT)架构允许模型学习视觉和动作 tokens 之间的复杂关系。闭环 rollout 机制通过ground-truth观测不断修正模型的预测,从而提高控制的准确性。异步推理流水线通过并行化动作预测和电机执行,减少了控制延迟。损失函数的设计旨在优化帧预测的准确性和策略执行的效率。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
LingBot-VA 在模拟和真实世界实验中均取得了显著成果。在长时程操作任务中,LingBot-VA 表现出优于现有方法的性能。此外,LingBot-VA 在后训练中表现出较高的数据效率,并且能够很好地泛化到新的配置。这些结果表明 LingBot-VA 在机器人控制领域具有巨大的潜力。
🎯 应用场景
LingBot-VA 有潜力应用于各种机器人控制任务,例如家庭服务机器人、工业自动化和自动驾驶。它可以帮助机器人更好地理解环境,并做出更明智的决策,从而提高机器人的自主性和适应性。该研究为机器人学习提供了一个新的方向,并有望推动机器人技术的发展。
📄 摘要(原文)
This work highlights that video world modeling, alongside vision-language pre-training, establishes a fresh and independent foundation for robot learning. Intuitively, video world models provide the ability to imagine the near future by understanding the causality between actions and visual dynamics. Inspired by this, we introduce LingBot-VA, an autoregressive diffusion framework that learns frame prediction and policy execution simultaneously. Our model features three carefully crafted designs: (1) a shared latent space, integrating vision and action tokens, driven by a Mixture-of-Transformers (MoT) architecture, (2) a closed-loop rollout mechanism, allowing for ongoing acquisition of environmental feedback with ground-truth observations, (3) an asynchronous inference pipeline, parallelizing action prediction and motor execution to support efficient control. We evaluate our model on both simulation benchmarks and real-world scenarios, where it shows significant promise in long-horizon manipulation, data efficiency in post-training, and strong generalizability to novel configurations. The code and model are made publicly available to facilitate the community.