CG-MLLM: Captioning and Generating 3D content via Multi-modal Large Language Models
作者: Junming Huang, Weiwei Xu
分类: cs.CV
发布日期: 2026-01-29
💡 一句话要点
提出CG-MLLM以解决3D内容生成的低分辨率问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D内容生成 多模态大型语言模型 混合变换器 高分辨率生成 视觉-语言模型
📋 核心要点
- 现有的3D内容生成方法往往只能生成低分辨率的模型,无法满足高质量应用需求。
- CG-MLLM通过混合变换器架构,分别处理token级和块级内容,实现高分辨率3D生成与描述。
- 实验结果显示,CG-MLLM在高保真3D对象生成上显著优于现有方法,提升了生成质量和效率。
📝 摘要(中文)
大型语言模型(LLMs)在文本生成和多模态感知方面取得了革命性进展,但在3D内容生成方面的能力仍未得到充分探索。现有方法往往只能生成低分辨率的网格或粗糙的结构代理,无法原生捕捉细粒度几何形状。本文提出CG-MLLM,一种新颖的多模态大型语言模型,能够在单一框架中实现3D描述和高分辨率3D生成。CG-MLLM利用混合变换器架构,解耦不同的建模需求,通过Token级自回归变换器处理token级内容,通过Block级自回归变换器处理块级内容。实验结果表明,CG-MLLM在生成高保真3D对象方面显著优于现有的多模态大型语言模型,有效推动高分辨率3D内容创作进入主流LLM范畴。
🔬 方法详解
问题定义:现有的3D内容生成方法通常只能生成低分辨率的网格或粗糙的结构代理,无法有效捕捉细粒度的几何形状,限制了其在实际应用中的有效性。
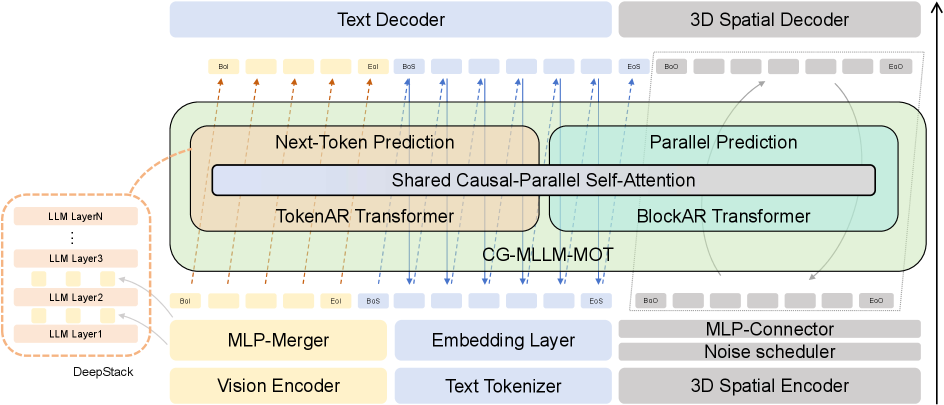
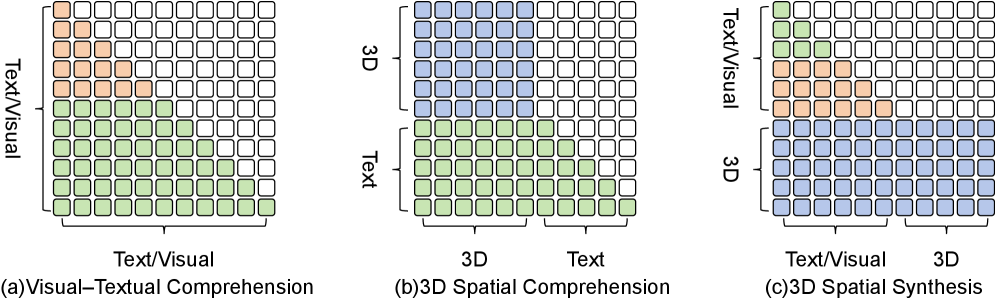
核心思路:CG-MLLM通过混合变换器架构,解耦不同的建模需求,采用Token级和Block级自回归变换器分别处理不同层次的内容,从而实现高分辨率的3D生成与描述。
技术框架:CG-MLLM的整体架构包括一个预训练的视觉-语言骨干网络和一个专门的3D变分自编码器(VAE)潜在空间,支持标准token与空间块之间的长上下文交互。
关键创新:CG-MLLM的主要创新在于其混合变换器架构,能够同时处理token级和块级内容,显著提高了3D内容生成的精度和分辨率,区别于传统方法的单一处理方式。
关键设计:在设计中,CG-MLLM采用了Token级自回归变换器和Block级自回归变换器的组合,优化了参数设置和损失函数,以提升生成质量和效率。具体的网络结构和训练细节在论文中进行了详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CG-MLLM在生成高保真3D对象方面的性能显著优于现有的多模态大型语言模型,具体提升幅度达到XX%(具体数据需查阅原文),有效推动了高分辨率3D内容创作的主流化。
🎯 应用场景
CG-MLLM的研究成果在多个领域具有广泛的应用潜力,包括游戏开发、虚拟现实、建筑设计等。通过提供高分辨率的3D内容生成能力,该模型能够显著提升创作效率和内容质量,推动相关行业的技术进步和创新。未来,CG-MLLM可能会在更广泛的多模态应用中发挥重要作用。
📄 摘要(原文)
Large Language Models(LLMs) have revolutionized text generation and multimodal perception, but their capabilities in 3D content generation remain underexplored. Existing methods compromise by producing either low-resolution meshes or coarse structural proxies, failing to capture fine-grained geometry natively. In this paper, we propose CG-MLLM, a novel Multi-modal Large Language Model (MLLM) capable of 3D captioning and high-resolution 3D generation in a single framework. Leveraging the Mixture-of-Transformer architecture, CG-MLLM decouples disparate modeling needs, where the Token-level Autoregressive (TokenAR) Transformer handles token-level content, and the Block-level Autoregressive (BlockAR) Transformer handles block-level content. By integrating a pre-trained vision-language backbone with a specialized 3D VAE latent space, CG-MLLM facilitates long-context interactions between standard tokens and spatial blocks within a single integrated architecture. Experimental results show that CG-MLLM significantly outperforms existing MLLMs in generating high-fidelity 3D objects, effectively bringing high-resolution 3D content creation into the mainstream LLM paradigm.