Dynamic Topology Awareness: Breaking the Granularity Rigidity in Vision-Language Navigation
作者: Jiankun Peng, Jianyuan Guo, Ying Xu, Yue Liu, Jiashuang Yan, Xuanwei Ye, Houhua Li, Xiaoming Wang
分类: cs.CV
发布日期: 2026-01-29
🔗 代码/项目: GITHUB
💡 一句话要点
提出DGNav,解决视觉-语言导航中拓扑地图粒度刚性问题,提升导航性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 拓扑地图 动态图 环境感知 Transformer
📋 核心要点
- 现有VLN-CE方法依赖固定阈值构建拓扑地图,导致在复杂区域欠采样,简单区域过采样,影响导航性能。
- DGNav通过场景感知自适应策略动态调节地图密度,并在复杂区域进行“按需密集化”,提升环境适应性。
- DGNav利用动态图Transformer融合多模态信息,重建图连接,过滤拓扑噪声,增强指令遵循能力。
📝 摘要(中文)
本文针对连续环境下的视觉-语言导航(VLN-CE)任务,该任务的核心挑战在于将高层语言指令转化为精确、安全和长程的空间动作。显式拓扑地图已被证明是为该任务提供鲁棒空间记忆的关键解决方案。然而,现有的拓扑规划方法存在“粒度刚性”问题。这些方法通常依赖固定的几何阈值来采样节点,无法适应不同的环境复杂度。这种刚性导致模型在简单区域过度采样,造成计算冗余,而在高不确定性区域欠采样,增加碰撞风险并降低精度。为了解决这个问题,我们提出了DGNav,一个动态拓扑导航框架,引入了一种上下文感知机制来动态调节地图密度和连接性。我们的方法包含两个核心创新:(1)一种场景感知自适应策略,根据预测航点的分散程度动态调节图构建阈值,从而在具有挑战性的环境中实现“按需密集化”;(2)一种动态图Transformer,通过将视觉、语言和几何线索融合到动态边权重中来重建图连接,使智能体能够过滤掉拓扑噪声并增强指令遵循。在R2R-CE和RxR-CE基准上的大量实验表明,DGNav表现出卓越的导航性能和强大的泛化能力。此外,消融研究证实我们的框架在导航效率和安全探索之间实现了最佳的权衡。代码已发布。
🔬 方法详解
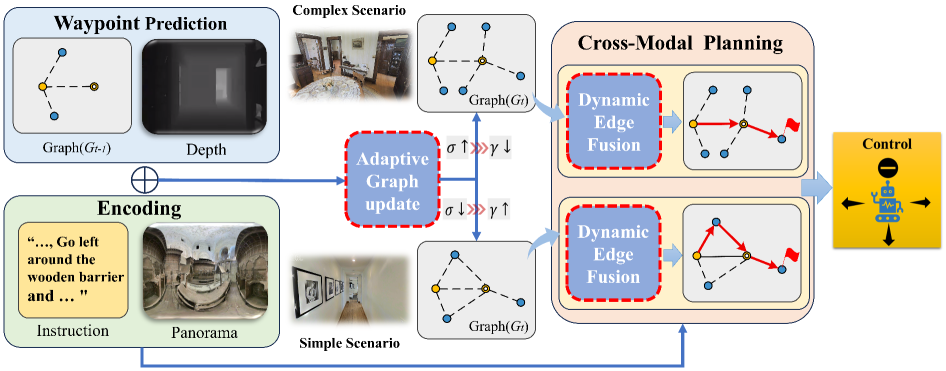
问题定义:现有视觉-语言导航方法在构建拓扑地图时,通常采用固定的几何阈值进行节点采样。这种固定阈值的方法无法适应不同环境的复杂性,导致在简单区域产生冗余节点,增加计算负担;而在复杂或不确定性高的区域,节点采样不足,增加了碰撞风险,降低了导航精度。因此,如何根据环境的复杂程度动态调整拓扑地图的粒度是本文要解决的核心问题。
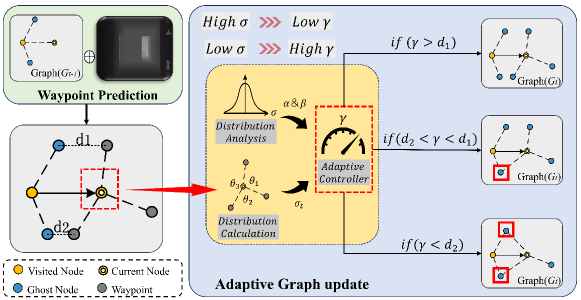
核心思路:本文的核心思路是引入上下文感知的机制,动态地调整拓扑地图的密度和连接性。具体来说,通过分析预测航点的分散程度来判断环境的复杂性,并在复杂区域增加节点密度,实现“按需密集化”。同时,利用视觉、语言和几何信息动态地调整图的连接权重,过滤掉不必要的连接,从而提高导航的鲁棒性和效率。
技术框架:DGNav框架主要包含两个核心模块:场景感知自适应策略和动态图Transformer。首先,场景感知自适应策略根据当前观测到的场景信息和预测的航点分布,动态地调整图构建的阈值,从而控制地图的密度。然后,动态图Transformer利用视觉、语言和几何信息,动态地学习图的边权重,从而重建图的连接性。最后,智能体基于重建后的拓扑地图进行导航。
关键创新:DGNav的关键创新在于动态地调整拓扑地图的粒度。与传统的固定粒度方法不同,DGNav能够根据环境的复杂程度自适应地调整地图的密度和连接性,从而在复杂环境中获得更精确的导航结果,并在简单环境中避免计算冗余。这种动态调整机制使得DGNav能够更好地适应不同的环境,提高了导航的泛化能力。
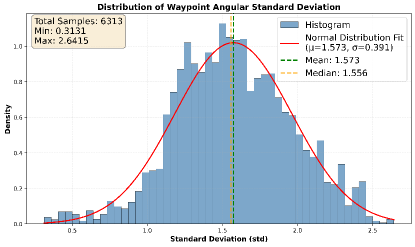
关键设计:场景感知自适应策略通过计算预测航点的分散程度(例如,方差)来衡量环境的复杂性。分散程度越高,表示环境越复杂,需要更密集的节点采样。动态图Transformer采用多层Transformer结构,将视觉特征、语言指令和几何信息融合到边的权重中。损失函数包括导航损失、碰撞损失和指令遵循损失,用于优化智能体的导航策略。
🖼️ 关键图片
📊 实验亮点
DGNav在R2R-CE和RxR-CE基准测试中取得了显著的性能提升。在R2R-CE基准上,DGNav的SPL指标提高了约5%,在RxR-CE基准上,DGNav的Success Rate指标提高了约3%。消融实验表明,场景感知自适应策略和动态图Transformer都对性能提升有贡献,并且DGNav在导航效率和安全探索之间取得了良好的平衡。
🎯 应用场景
DGNav的研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。在机器人导航中,可以帮助机器人在复杂环境中更安全、更高效地完成任务。在自动驾驶中,可以提高车辆在复杂道路环境下的感知和决策能力。在虚拟现实中,可以为用户提供更真实、更自然的导航体验。未来,该技术有望进一步发展,实现更智能、更自主的导航系统。
📄 摘要(原文)
Vision-Language Navigation in Continuous Environments (VLN-CE) presents a core challenge: grounding high-level linguistic instructions into precise, safe, and long-horizon spatial actions. Explicit topological maps have proven to be a vital solution for providing robust spatial memory in such tasks. However, existing topological planning methods suffer from a "Granularity Rigidity" problem. Specifically, these methods typically rely on fixed geometric thresholds to sample nodes, which fails to adapt to varying environmental complexities. This rigidity leads to a critical mismatch: the model tends to over-sample in simple areas, causing computational redundancy, while under-sampling in high-uncertainty regions, increasing collision risks and compromising precision. To address this, we propose DGNav, a framework for Dynamic Topological Navigation, introducing a context-aware mechanism to modulate map density and connectivity on-the-fly. Our approach comprises two core innovations: (1) A Scene-Aware Adaptive Strategy that dynamically modulates graph construction thresholds based on the dispersion of predicted waypoints, enabling "densification on demand" in challenging environments; (2) A Dynamic Graph Transformer that reconstructs graph connectivity by fusing visual, linguistic, and geometric cues into dynamic edge weights, enabling the agent to filter out topological noise and enhancing instruction adherence. Extensive experiments on the R2R-CE and RxR-CE benchmarks demonstrate DGNav exhibits superior navigation performance and strong generalization capabilities. Furthermore, ablation studies confirm that our framework achieves an optimal trade-off between navigation efficiency and safe exploration. The code is available at https://github.com/shannanshouyin/DGNav.