Multimodal Visual Surrogate Compression for Alzheimer's Disease Classification
作者: Dexuan Ding, Ciyuan Peng, Endrowednes Kuantama, Jingcai Guo, Jia Wu, Jian Yang, Amin Beheshti, Ming-Hsuan Yang, Yuankai Qi
分类: cs.CV
发布日期: 2026-01-29
💡 一句话要点
提出多模态视觉代理压缩MVSC,用于提升阿尔茨海默病分类精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 阿尔茨海默病 结构MRI 视觉代理压缩 多模态学习 深度学习 医学影像分析 预训练模型
📋 核心要点
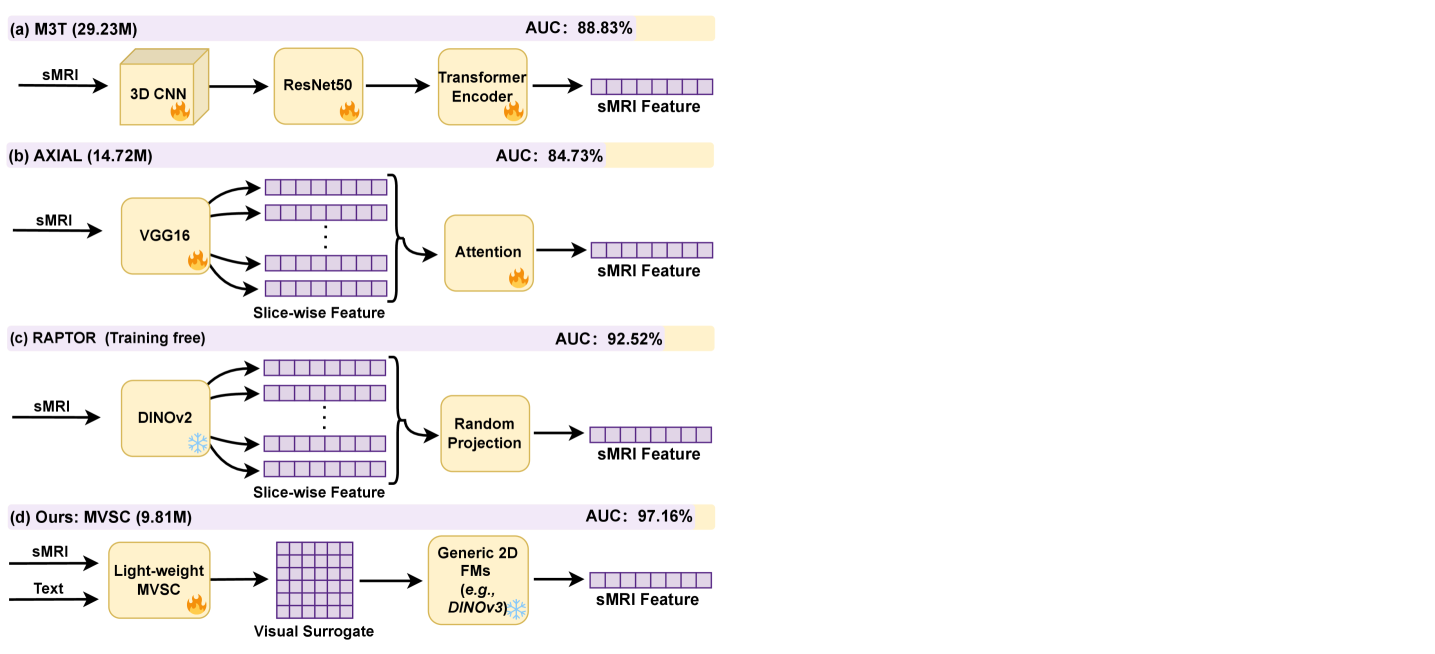
- 现有基于3D CNN、切片特征提取或2D基础模型的sMRI表征学习方法存在计算成本高、忽略切片间关系和特征区分能力有限等问题。
- MVSC通过学习将3D sMRI压缩为2D视觉代理,并与冻结的2D基础模型对齐,从而提取更具区分性的特征用于AD分类。
- 在三个大规模AD数据集上的实验表明,MVSC在二元和多类分类任务上均优于现有方法,证明了其有效性。
📝 摘要(中文)
本文提出了一种用于阿尔茨海默病(AD)诊断的多模态视觉代理压缩(MVSC)方法,旨在解决现有基于结构MRI(sMRI)图像的AD诊断方法中计算成本高、忽略切片间关系以及特征区分能力有限等问题。MVSC学习将大型3D sMRI体数据压缩并适配为紧凑的2D特征,即视觉代理,使其更好地与冻结的2D基础模型对齐,从而提取用于最终AD分类的强大表征。MVSC包含两个关键组件:一个在文本指导下捕获全局跨切片上下文的体数据上下文编码器,以及一个以文本增强的、块状方式聚合切片级信息的自适应切片融合模块。在三个大规模阿尔茨海默病基准数据集上的大量实验表明,与最先进的方法相比,MVSC在二元和多类分类任务上均表现出色。
🔬 方法详解
问题定义:现有基于结构MRI的阿尔茨海默病诊断方法,如3D CNN、切片特征提取加后期融合,以及使用2D预训练模型等,存在计算量大、忽略切片间关系、特征区分能力不足等问题,限制了诊断精度和效率。
核心思路:论文的核心思路是将3D sMRI体数据压缩成紧凑的2D视觉代理,然后利用预训练的2D基础模型提取特征。通过这种方式,既降低了计算成本,又可以利用预训练模型的强大表征能力。同时,通过文本引导和自适应融合,保留了重要的跨切片信息。
技术框架:MVSC主要包含两个模块:1) 体数据上下文编码器(Volume Context Encoder):该模块在文本指导下,捕获3D sMRI体数据的全局跨切片上下文信息。2) 自适应切片融合模块(Adaptive Slice Fusion):该模块以文本增强的、块状方式聚合切片级信息,生成最终的2D视觉代理。最终,使用预训练的2D基础模型提取特征,并进行AD分类。
关键创新:MVSC的关键创新在于将3D sMRI数据压缩为2D视觉代理,并结合文本信息进行引导,从而更好地利用预训练的2D基础模型。这种方法既降低了计算成本,又保留了重要的3D结构信息。此外,自适应切片融合模块能够有效地聚合切片级信息,提高特征的区分能力。
关键设计:体数据上下文编码器使用Transformer架构,并引入文本嵌入作为指导信号,以捕获全局上下文信息。自适应切片融合模块使用注意力机制,根据文本信息自适应地融合不同切片的特征。损失函数包括分类损失和重构损失,用于优化视觉代理的生成。
🖼️ 关键图片

📊 实验亮点
MVSC在三个大规模阿尔茨海默病基准数据集上进行了评估,实验结果表明,MVSC在二元和多类分类任务上均优于现有最先进的方法。具体性能提升数据在论文中给出,相较于现有方法,MVSC在分类精度上有显著提升。
🎯 应用场景
该研究成果可应用于阿尔茨海默病的早期诊断和辅助诊断,有助于医生更准确地判断病情,制定更有效的治疗方案。此外,该方法也可推广到其他医学影像分析任务中,例如脑肿瘤检测、脑卒中诊断等,具有广泛的应用前景。
📄 摘要(原文)
High-dimensional structural MRI (sMRI) images are widely used for Alzheimer's Disease (AD) diagnosis. Most existing methods for sMRI representation learning rely on 3D architectures (e.g., 3D CNNs), slice-wise feature extraction with late aggregation, or apply training-free feature extractions using 2D foundation models (e.g., DINO). However, these three paradigms suffer from high computational cost, loss of cross-slice relations, and limited ability to extract discriminative features, respectively. To address these challenges, we propose Multimodal Visual Surrogate Compression (MVSC). It learns to compress and adapt large 3D sMRI volumes into compact 2D features, termed as visual surrogates, which are better aligned with frozen 2D foundation models to extract powerful representations for final AD classification. MVSC has two key components: a Volume Context Encoder that captures global cross-slice context under textual guidance, and an Adaptive Slice Fusion module that aggregates slice-level information in a text-enhanced, patch-wise manner. Extensive experiments on three large-scale Alzheimer's disease benchmarks demonstrate our MVSC performs favourably on both binary and multi-class classification tasks compared against state-of-the-art methods.