CAF-Mamba: Mamba-Based Cross-Modal Adaptive Attention Fusion for Multimodal Depression Detection
作者: Bowen Zhou, Marc-André Fiedler, Ayoub Al-Hamadi
分类: cs.CV, cs.CY, cs.HC
发布日期: 2026-01-29
备注: The paper contains a total of 5 pages and 3 figures. This paper has been accepted for publication in the proceedings of 2026 IEEE ICASSP Conference
💡 一句话要点
提出CAF-Mamba,基于Mamba的跨模态自适应注意力融合框架,用于多模态抑郁症检测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 抑郁症检测 Mamba架构 自适应注意力 跨模态交互 心理健康 序列建模
📋 核心要点
- 现有抑郁症检测方法依赖有限特征,忽略跨模态交互,融合方式简单,限制了性能。
- CAF-Mamba通过Mamba架构显式和隐式地建模跨模态交互,并动态调整模态贡献。
- 在LMVD和D-Vlog数据集上,CAF-Mamba超越现有方法,达到state-of-the-art水平。
📝 摘要(中文)
抑郁症是一种常见的精神健康障碍,严重影响日常生活功能和生活质量。近年来,深度学习方法在抑郁症检测方面展现出潜力,但多数方法依赖于有限的特征类型,忽略了显式的跨模态交互,并采用简单的拼接或静态加权进行融合。为了克服这些局限性,我们提出了CAF-Mamba,一种新颖的基于Mamba的跨模态自适应注意力融合框架。CAF-Mamba不仅显式和隐式地捕获跨模态交互,还通过模态级别的注意力机制动态调整模态贡献,从而实现更有效的多模态融合。在两个真实场景的基准数据集LMVD和D-Vlog上的实验表明,CAF-Mamba始终优于现有方法,并实现了最先进的性能。
🔬 方法详解
问题定义:现有基于深度学习的抑郁症检测方法通常存在以下痛点:依赖于单一或有限的特征类型,无法充分利用多模态信息的互补性;忽略了不同模态之间的显式交互,导致信息融合不充分;采用简单的拼接或静态加权融合策略,无法根据不同模态的重要性动态调整其贡献。
核心思路:CAF-Mamba的核心思路是利用Mamba架构强大的序列建模能力,同时结合跨模态自适应注意力机制,实现对多模态信息的有效融合。Mamba能够捕获长程依赖关系,从而更好地建模跨模态交互。自适应注意力机制则可以动态地学习不同模态的重要性,并根据其贡献程度进行加权,从而提高融合效果。这样设计的目的是为了克服现有方法在跨模态交互建模和模态贡献度量方面的不足。
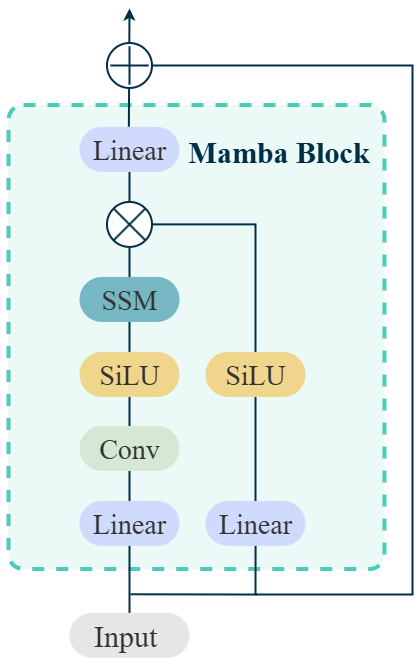
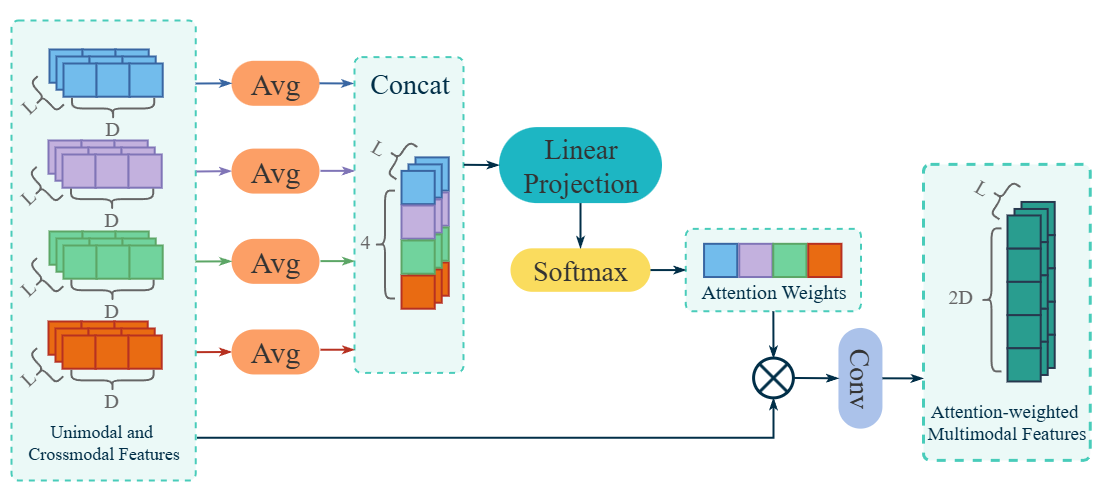
技术框架:CAF-Mamba的整体架构包含以下几个主要模块:1) 特征提取模块:用于从不同模态(如音频、视频、文本)中提取特征。2) Mamba编码器:利用Mamba架构对各模态特征进行编码,捕获模态内的长程依赖关系。3) 跨模态自适应注意力融合模块:通过注意力机制学习不同模态之间的交互关系,并动态调整模态贡献。4) 分类器:基于融合后的特征进行抑郁症检测。
关键创新:CAF-Mamba最重要的技术创新点在于将Mamba架构引入到多模态抑郁症检测任务中,并结合了跨模态自适应注意力机制。与传统的RNN或Transformer相比,Mamba具有更高的计算效率和更强的序列建模能力。与简单的拼接或静态加权融合相比,自适应注意力机制能够更有效地利用多模态信息。
关键设计:在CAF-Mamba中,Mamba编码器的层数和隐藏层维度需要根据具体数据集进行调整。跨模态自适应注意力机制采用多头注意力机制,头数通常设置为8或16。损失函数采用交叉熵损失函数,优化器采用AdamW优化器,学习率和权重衰减系数需要进行精细调整。
🖼️ 关键图片
📊 实验亮点
CAF-Mamba在LMVD和D-Vlog两个数据集上均取得了state-of-the-art的性能。例如,在LMVD数据集上,CAF-Mamba相比于现有最佳方法提升了约2-3个百分点。实验结果表明,CAF-Mamba能够有效地捕获跨模态交互,并动态调整模态贡献,从而提高抑郁症检测的准确率。
🎯 应用场景
CAF-Mamba可应用于心理健康领域的抑郁症早期筛查、诊断辅助和病情监测。通过分析患者的语音、面部表情和文本信息,可以客观评估其心理状态,为医生提供辅助决策支持。该研究还有助于开发智能心理健康服务平台,提升心理健康服务的可及性和效率。
📄 摘要(原文)
Depression is a prevalent mental health disorder that severely impairs daily functioning and quality of life. While recent deep learning approaches for depression detection have shown promise, most rely on limited feature types, overlook explicit cross-modal interactions, and employ simple concatenation or static weighting for fusion. To overcome these limitations, we propose CAF-Mamba, a novel Mamba-based cross-modal adaptive attention fusion framework. CAF-Mamba not only captures cross-modal interactions explicitly and implicitly, but also dynamically adjusts modality contributions through a modality-wise attention mechanism, enabling more effective multimodal fusion. Experiments on two in-the-wild benchmark datasets, LMVD and D-Vlog, demonstrate that CAF-Mamba consistently outperforms existing methods and achieves state-of-the-art performance.