OCRVerse: Towards Holistic OCR in End-to-End Vision-Language Models
作者: Yufeng Zhong, Lei Chen, Xuanle Zhao, Wenkang Han, Liming Zheng, Jing Huang, Deyang Jiang, Yilin Cao, Lin Ma, Zhixiong Zeng
分类: cs.CV
发布日期: 2026-01-29
💡 一句话要点
提出OCRVerse,实现端到端视觉语言模型中的整体OCR,统一处理文本和视觉元素。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 整体OCR 视觉语言模型 文本识别 图表识别 多域训练 强化学习 数据工程
📋 核心要点
- 现有OCR方法侧重于文本识别,忽略了对图表、网页等视觉元素的识别,限制了其在视觉信息密集型场景的应用。
- OCRVerse提出了一种端到端的整体OCR方法,通过统一处理文本和视觉元素,实现更全面的信息提取。
- 通过两阶段SFT-RL多域训练,OCRVerse在文本和视觉中心数据上均取得良好效果,可与现有模型媲美。
📝 摘要(中文)
大型视觉语言模型的发展推动了对管理和应用海量多模态数据的需求,使得OCR技术日益普及。然而,现有的OCR方法主要集中于识别图像或扫描文档中的文本元素(文本中心OCR),而忽略了从视觉信息密集的图像源(视觉中心OCR)中识别视觉元素,例如图表、网页和科学绘图。实际上,这些视觉信息密集的图像在互联网上广泛存在,并具有重要应用价值,例如数据可视化和网页分析。本报告提出了OCRVerse,这是第一个端到端整体OCR方法,能够统一进行文本中心OCR和视觉中心OCR。为此,我们构建了全面的数据工程,涵盖了各种文本中心文档(如报纸、杂志和书籍)以及视觉中心渲染合成图像(包括图表、网页和科学绘图)。此外,我们提出了一种两阶段SFT-RL多域训练方法。SFT直接混合跨域数据进行训练,建立初始领域知识,而RL则侧重于为每个领域的特征设计个性化的奖励策略。具体而言,由于不同领域需要不同的输出格式和预期输出,我们在RL阶段提供了足够的灵活性,为每个领域定制灵活的奖励信号,从而提高跨域融合并避免数据冲突。实验结果表明了OCRVerse的有效性,在文本中心和视觉中心数据类型上都取得了有竞争力的结果,甚至可以与大规模开源和闭源模型相媲美。
🔬 方法详解
问题定义:现有OCR方法主要关注文本识别,忽略了视觉信息密集型图像中的视觉元素识别,例如图表、网页等。这限制了OCR技术在数据可视化、网页分析等领域的应用。现有方法无法同时处理文本和视觉元素,缺乏通用性和灵活性。
核心思路:OCRVerse的核心思路是构建一个端到端的模型,能够统一处理文本中心和视觉中心的OCR任务。通过构建包含文本和视觉元素的数据集,并采用多域训练方法,使模型能够学习到通用的OCR能力。针对不同领域定制奖励策略,提高模型在特定领域的性能。
技术框架:OCRVerse采用两阶段训练框架:SFT(Supervised Fine-Tuning)和RL(Reinforcement Learning)。SFT阶段,模型在混合的跨域数据上进行训练,以建立初始的领域知识。RL阶段,针对每个领域的特点,设计个性化的奖励策略,以提高模型在特定领域的性能。整体流程是先通过SFT进行预训练,然后通过RL进行精调。
关键创新:OCRVerse的关键创新在于提出了一个整体OCR框架,能够统一处理文本和视觉元素。此外,提出的两阶段SFT-RL多域训练方法,能够有效地融合不同领域的数据,并针对每个领域进行优化。这种方法避免了数据冲突,提高了模型的泛化能力。
关键设计:在RL阶段,针对不同领域设计不同的奖励函数。例如,对于文本识别任务,奖励函数可以基于识别的准确率;对于图表识别任务,奖励函数可以基于识别的图表类型和数据点的准确性。SFT阶段采用标准的交叉熵损失函数。具体的网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

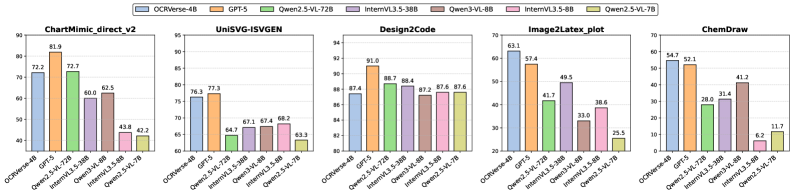

📊 实验亮点
OCRVerse在文本中心和视觉中心数据类型上都取得了有竞争力的结果,甚至可以与大规模开源和闭源模型相媲美。这表明OCRVerse在处理复杂视觉信息方面具有很强的能力,能够有效地统一处理文本和视觉元素。
🎯 应用场景
OCRVerse可广泛应用于数据可视化、网页分析、科学文档处理等领域。例如,可以自动从网页中提取表格数据,从科学论文中提取图表信息,从而提高信息获取和分析的效率。未来,OCRVerse有望成为视觉语言模型的重要组成部分,促进多模态信息的理解和应用。
📄 摘要(原文)
The development of large vision language models drives the demand for managing, and applying massive amounts of multimodal data, making OCR technology, which extracts information from visual images, increasingly popular. However, existing OCR methods primarily focus on recognizing text elements from images or scanned documents (\textbf{Text-centric OCR}), neglecting the identification of visual elements from visually information-dense image sources (\textbf{Vision-centric OCR}), such as charts, web pages and science plots. In reality, these visually information-dense images are widespread on the internet and have significant real-world application value, such as data visualization and web page analysis. In this technical report, we propose \textbf{OCRVerse}, the first holistic OCR method in end-to-end manner that enables unified text-centric OCR and vision-centric OCR. To this end, we constructe comprehensive data engineering to cover a wide range of text-centric documents, such as newspapers, magazines and books, as well as vision-centric rendered composites, including charts, web pages and scientific plots. Moreover, we propose a two-stage SFT-RL multi-domain training method for OCRVerse. SFT directly mixes cross-domain data to train and establish initial domain knowledge, while RL focuses on designing personalized reward strategies for the characteristics of each domain. Specifically, since different domains require various output formats and expected outputs, we provide sufficient flexibility in the RL stage to customize flexible reward signals for each domain, thereby improving cross-domain fusion and avoiding data conflicts. Experimental results demonstrate the effectiveness of OCRVerse, achieving competitive results across text-centric and vision-centric data types, even comparable to large-scale open-source and closed-source models.