Spava: Accelerating Long-Video Understanding via Sequence-Parallelism-aware Approximate Attention
作者: Yuxiang Huang, Mingye Li, Xu Han, Chaojun Xiao, Weilin Zhao, Ao Sun, Ziqi Yuan, Hao Zhou, Fandong Meng, Zhiyuan Liu
分类: cs.CV, cs.AI, cs.CL
发布日期: 2026-01-29
备注: Preprint
🔗 代码/项目: GITHUB
💡 一句话要点
Spava:通过序列并行近似注意力加速长视频理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 序列并行 近似注意力 多模态模型 分布式计算
📋 核心要点
- 现有长视频理解方法受限于单GPU的计算能力,压缩视觉嵌入或采用稀疏注意力导致性能下降。
- Spava通过序列并行框架和优化的近似注意力,在多GPU上分配计算,提高并行性和效率。
- 实验表明,Spava在加速长视频推理方面显著优于现有方法,且性能损失不明显。
📝 摘要(中文)
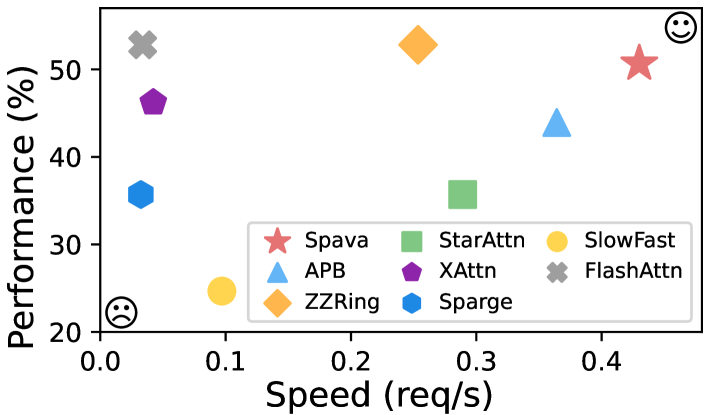
长视频推理的效率仍然是一个关键瓶颈,这主要是由于大型多模态模型(LMM)在预填充阶段的密集计算。现有方法要么压缩视觉嵌入,要么在单个GPU上应用稀疏注意力,导致加速效果有限或性能下降,并限制了LMM处理更长、更复杂视频的能力。为了克服这些问题,我们提出了Spava,一个具有优化注意力的序列并行框架,可以跨多个GPU加速长视频推理。通过分配近似注意力,Spava减少了计算量并增加了并行性,从而能够有效处理更多的视觉嵌入而无需压缩,进而提高了任务性能。系统级优化,如负载平衡和融合前向传递,进一步释放了Spava的潜力,与FlashAttn、ZigZagRing和APB相比,分别实现了12.72倍、1.70倍和1.18倍的加速,且没有明显的性能损失。
🔬 方法详解
问题定义:论文旨在解决长视频理解中,大型多模态模型(LMMs)推理效率低下的问题,尤其是在预填充(prefill)阶段,由于视觉嵌入的密集计算,导致计算瓶颈。现有方法,如压缩视觉嵌入或使用稀疏注意力,要么牺牲性能,要么加速效果有限,无法充分利用LMMs处理长视频的能力。
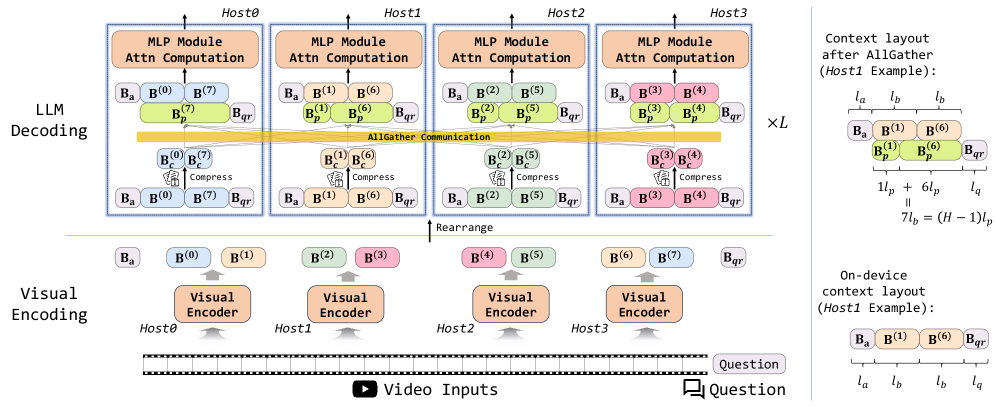
核心思路:Spava的核心思路是利用序列并行(Sequence Parallelism)框架,将长视频的视觉嵌入序列分割到多个GPU上进行并行处理。同时,采用近似注意力机制,降低每个GPU上的计算负担,从而在不显著降低性能的前提下,大幅提升推理速度。通过优化注意力计算和系统层面的优化,Spava旨在实现更高的并行度和更低的通信开销。
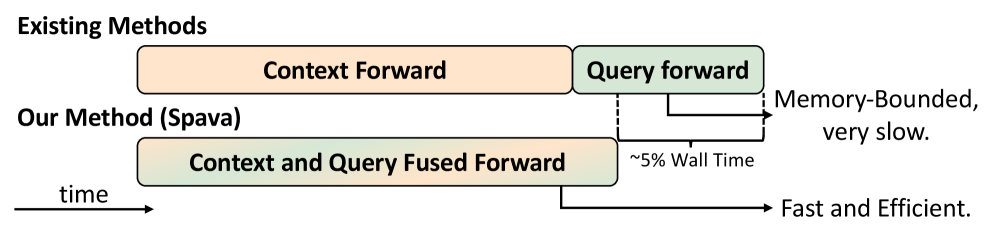
技术框架:Spava的整体框架包含以下几个主要部分:1) 视觉嵌入提取:将长视频转换为视觉特征序列。2) 序列并行分割:将视觉特征序列分割到多个GPU上。3) 近似注意力计算:在每个GPU上并行计算近似注意力。4) 系统级优化:包括负载均衡和融合前向传递等优化策略。整个流程旨在实现高效的分布式计算,从而加速长视频的推理过程。
关键创新:Spava的关键创新在于序列并行框架与近似注意力的结合。传统的序列并行主要应用于自然语言处理领域,而Spava将其应用于长视频理解,并针对视觉数据的特点进行了优化。此外,Spava的近似注意力机制能够在保证一定性能的前提下,显著降低计算复杂度,从而提高并行效率。
关键设计:Spava的关键设计包括:1) 序列分割策略:如何将长视频序列有效地分割到多个GPU上,以实现负载均衡。2) 近似注意力机制的选择和优化:选择合适的近似注意力方法,并针对视觉数据进行调整,以在计算效率和性能之间取得平衡。3) 系统级优化策略:如何通过负载均衡和融合前向传递等手段,进一步提高并行效率和降低通信开销。具体的参数设置、损失函数和网络结构等细节在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片
📊 实验亮点
Spava在长视频推理任务中取得了显著的加速效果。实验结果表明,Spava相对于FlashAttn、ZigZagRing和APB,分别实现了12.72倍、1.70倍和1.18倍的加速,且没有明显的性能损失。这些数据表明,Spava在提高长视频理解效率方面具有显著优势。
🎯 应用场景
Spava的潜在应用领域包括视频监控、自动驾驶、视频内容分析、智能安防等。通过加速长视频理解,Spava可以使LMMs更高效地处理复杂的视频数据,从而提高这些应用场景的智能化水平。例如,在视频监控中,Spava可以帮助LMMs更快地识别异常行为;在自动驾驶中,可以更快地理解周围环境,提高安全性。
📄 摘要(原文)
The efficiency of long-video inference remains a critical bottleneck, mainly due to the dense computation in the prefill stage of Large Multimodal Models (LMMs). Existing methods either compress visual embeddings or apply sparse attention on a single GPU, yielding limited acceleration or degraded performance and restricting LMMs from handling longer, more complex videos. To overcome these issues, we propose Spava, a sequence-parallel framework with optimized attention that accelerates long-video inference across multiple GPUs. By distributing approximate attention, Spava reduces computation and increases parallelism, enabling efficient processing of more visual embeddings without compression and thereby improving task performance. System-level optimizations, such as load balancing and fused forward passes, further unleash the potential of Spava, delivering speedups of 12.72x, 1.70x, and 1.18x over FlashAttn, ZigZagRing, and APB, without notable performance loss. Code available at https://github.com/thunlp/APB