MultiModal Fine-tuning with Synthetic Captions
作者: Shohei Enomoto, Shin'ya Yamaguchi
分类: cs.CV
发布日期: 2026-01-29
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于多模态大语言模型生成合成字幕的多模态微调方法,提升图像分类性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 图像分类 合成数据 大语言模型 微调 少样本学习 对比学习
📋 核心要点
- 现有微调方法主要为单模态,无法充分利用多模态预训练带来的视觉理解能力。
- 利用多模态大语言模型生成高质量合成图像字幕,将单模态数据集转化为多模态数据集。
- 实验结果表明,该方法在多个图像分类基准上优于现有方法,尤其在少样本学习中提升显著。
📝 摘要(中文)
本文旨在解决深度神经网络预训练和微调之间存在的差距:预训练已从单模态转向多模态学习,增强了视觉理解,而微调主要仍为单模态,限制了预训练表征的优势。为此,我们提出了一种新方法,利用多模态大语言模型(MLLM)生成合成图像字幕,将单模态数据集转换为多模态数据集,从而使用多模态目标函数微调模型。我们的方法采用精心设计的提示,结合类别标签和领域上下文,生成高质量的、针对分类任务定制的字幕。此外,我们引入了一种监督对比损失函数,显式地鼓励微调期间同类别表征的聚类,以及一种新的推理技术,利用每个图像的多个合成字幕的类别平均文本嵌入。在13个图像分类基准上的大量实验表明,我们的方法优于基线方法,在少样本学习场景中尤其显著。我们的工作为数据集增强建立了一种新范式,有效地弥合了多模态预训练和微调之间的差距。代码已开源。
🔬 方法详解
问题定义:现有深度学习模型通常采用预训练-微调的范式。预训练阶段已经发展到多模态学习,能够学习到更丰富的视觉表征。然而,微调阶段仍然主要依赖于单模态数据(例如,只有图像标签),无法充分利用预训练阶段学习到的多模态信息。这导致了预训练和微调之间的gap,限制了模型性能的进一步提升。
核心思路:本文的核心思路是利用多模态大语言模型(MLLM)生成图像的合成字幕,从而将单模态的图像分类数据集转化为多模态数据集。这样,在微调阶段就可以利用图像和文本之间的关联信息,更好地利用预训练模型学习到的多模态表征。通过多模态微调,可以提升模型的泛化能力和分类精度。
技术框架:该方法主要包含以下几个阶段: 1. 合成字幕生成:使用MLLM为每张图像生成多个合成字幕。提示语(prompt)的设计至关重要,需要包含类别标签和领域上下文信息,以生成高质量的、与分类任务相关的字幕。 2. 多模态微调:使用图像和合成字幕对预训练模型进行微调。微调的目标是学习图像和文本之间的联合表征,使得相同类别的图像和文本在特征空间中更接近。 3. 推理:在推理阶段,利用每个图像的多个合成字幕的类别平均文本嵌入来预测图像的类别。
关键创新:该方法的主要创新点在于: 1. 利用MLLM生成合成字幕:这是一种将单模态数据集转化为多模态数据集的有效方法,可以弥合预训练和微调之间的gap。 2. 监督对比损失函数:该损失函数显式地鼓励微调期间同类别表征的聚类,从而提升模型的分类性能。 3. 类别平均文本嵌入推理:该推理技术利用多个合成字幕的信息,可以提高预测的鲁棒性。
关键设计: 1. 提示语设计:提示语需要包含类别标签和领域上下文信息,以生成高质量的字幕。例如,可以使用如下提示语:“A photo of a [类别标签] in [领域上下文]”。 2. 监督对比损失函数:使用InfoNCE loss,鼓励同类别样本的embedding更接近,不同类别样本的embedding更远离。 3. 类别平均文本嵌入:对每个图像生成的多个字幕的文本embedding进行平均,得到该图像的类别平均文本嵌入。在推理时,使用该嵌入与图像embedding进行匹配,从而预测图像的类别。
🖼️ 关键图片

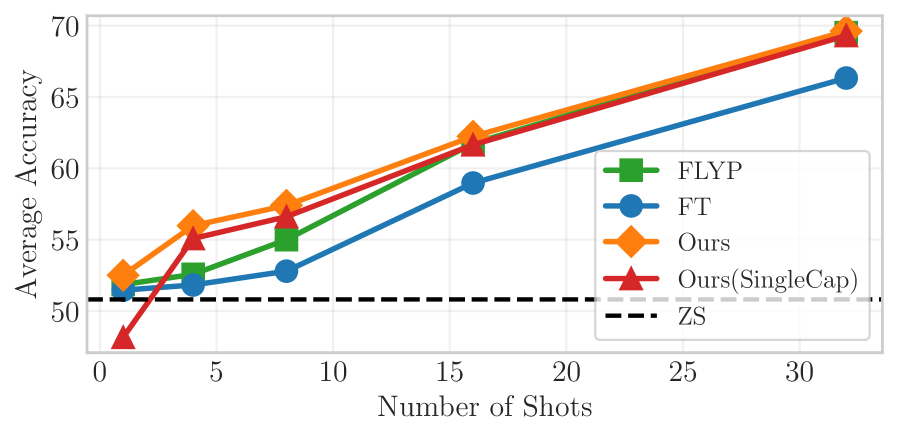
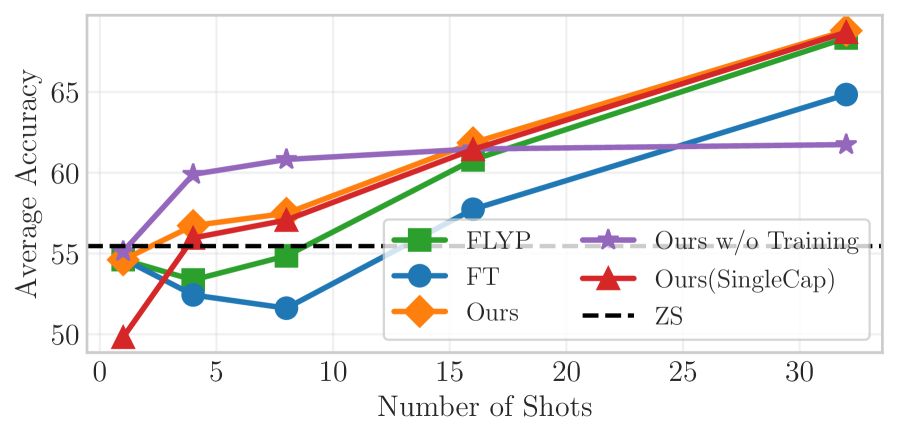
📊 实验亮点
在13个图像分类基准测试中,该方法显著优于基线方法,尤其在少样本学习场景中表现突出。例如,在某些数据集上,该方法可以将分类精度提高5%以上。实验结果表明,利用多模态信息可以有效提升模型的性能,弥合预训练和微调之间的gap。
🎯 应用场景
该研究成果可广泛应用于图像分类、图像检索、目标检测等计算机视觉任务中。通过将单模态数据集转化为多模态数据集,可以提升模型的泛化能力和鲁棒性。该方法尤其适用于数据量较少的场景,例如少样本学习和零样本学习。未来,该方法可以扩展到其他模态的数据,例如音频和视频,从而实现更强大的多模态学习模型。
📄 摘要(原文)
In this paper, we address a fundamental gap between pre-training and fine-tuning of deep neural networks: while pre-training has shifted from unimodal to multimodal learning with enhanced visual understanding, fine-tuning predominantly remains unimodal, limiting the benefits of rich pre-trained representations. To bridge this gap, we propose a novel approach that transforms unimodal datasets into multimodal ones using Multimodal Large Language Models (MLLMs) to generate synthetic image captions for fine-tuning models with a multimodal objective. Our method employs carefully designed prompts incorporating class labels and domain context to produce high-quality captions tailored for classification tasks. Furthermore, we introduce a supervised contrastive loss function that explicitly encourages clustering of same-class representations during fine-tuning, along with a new inference technique that leverages class-averaged text embeddings from multiple synthetic captions per image. Extensive experiments across 13 image classification benchmarks demonstrate that our approach outperforms baseline methods, with particularly significant improvements in few-shot learning scenarios. Our work establishes a new paradigm for dataset enhancement that effectively bridges the gap between multimodal pre-training and fine-tuning. Our code is available at https://github.com/s-enmt/MMFT.