Towards Geometry-Aware and Motion-Guided Video Human Mesh Recovery
作者: Hongjun Chen, Huan Zheng, Wencheng Han, Jianbing Shen
分类: cs.CV
发布日期: 2026-01-29
💡 一句话要点
提出HMRMamba,利用几何感知和运动引导实现更精确的视频人体网格重建
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱八:物理动画 (Physics-based Animation)
关键词: 人体网格重建 视频处理 结构化状态空间模型 Mamba 几何感知 运动引导 3D姿态估计
📋 核心要点
- 现有视频HMR方法依赖不准确的3D姿态锚点,且缺乏对复杂时空动态的有效建模,导致重建结果不符合物理规律。
- HMRMamba利用结构化状态空间模型(SSM)的优势,通过几何感知提升模块和运动引导重建网络,实现更精确的重建。
- 实验表明,HMRMamba在重建精度、时间一致性和计算效率方面均优于现有方法,并在多个benchmark上取得了SOTA。
📝 摘要(中文)
现有的基于视频的3D人体网格重建(HMR)方法由于依赖有缺陷的中间3D姿态锚点,并且无法有效地建模复杂的时空动态,因此经常产生不符合物理规律的结果。为了克服这些深层次的架构问题,我们引入了HMRMamba,这是一种新的HMR范例,它率先使用结构化状态空间模型(SSM),因其效率和长程建模能力而著称。我们的框架有两个核心贡献。首先,几何感知提升模块,采用了一种新颖的双扫描Mamba架构,为重建奠定了坚实的基础。它直接利用图像特征中的几何线索来支撑2D到3D的姿态提升过程,产生高度可靠的3D姿态序列,作为稳定的锚点。其次,运动引导重建网络利用这个锚点来显式地处理随时间的运动模式。通过注入这种关键的时间感知,它显著增强了最终网格的连贯性和鲁棒性,特别是在遮挡和运动模糊的情况下。在3DPW、MPI-INF-3DHP和Human3.6M基准上的综合评估证实,HMRMamba建立了一个新的最先进水平,在重建精度和时间一致性方面都优于现有方法,同时提供了卓越的计算效率。
🔬 方法详解
问题定义:现有基于视频的人体网格重建方法,由于依赖不准确的中间3D姿态估计作为锚点,并且难以有效建模视频中的复杂时空动态信息,导致重建结果在物理上不合理,时间上不连贯。尤其是在遮挡和运动模糊等情况下,重建效果会显著下降。
核心思路:HMRMamba的核心思路是利用几何信息引导的姿态提升模块生成更可靠的3D姿态序列作为锚点,并在此基础上,通过运动引导的重建网络显式地建模时间上的运动模式。通过这种方式,可以提高重建结果的精度和时间一致性,使其更符合物理规律。
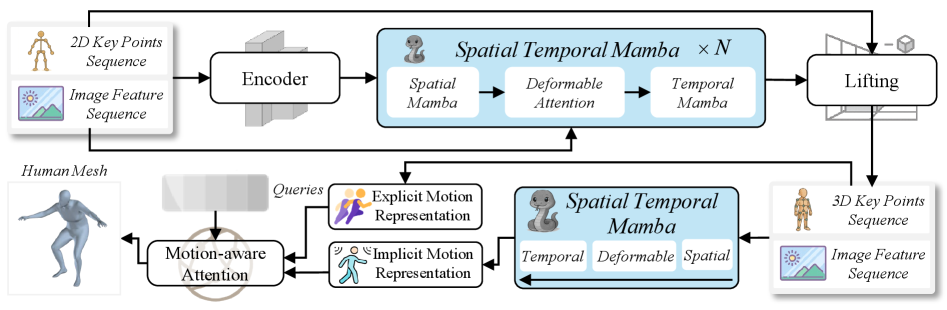
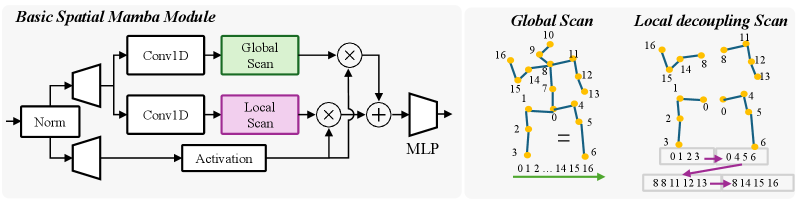
技术框架:HMRMamba框架主要包含两个核心模块:几何感知提升模块(Geometry-Aware Lifting Module)和运动引导重建网络(Motion-guided Reconstruction Network)。几何感知提升模块负责从2D图像特征中提取几何线索,并将其用于提升3D姿态的准确性。该模块使用双扫描Mamba架构,增强了对图像几何信息的理解。运动引导重建网络则利用几何感知提升模块输出的3D姿态序列作为锚点,并在此基础上建模时间上的运动模式,从而提高重建结果的连贯性和鲁棒性。
关键创新:HMRMamba的关键创新在于:1) 引入了结构化状态空间模型(SSM),特别是Mamba架构,用于人体网格重建,充分利用了SSM在长程建模方面的优势。2) 提出了几何感知提升模块,通过图像几何信息引导3D姿态的提升,从而生成更可靠的姿态锚点。3) 设计了运动引导重建网络,显式地建模时间上的运动模式,从而提高重建结果的时间一致性。与现有方法相比,HMRMamba不再仅仅依赖于中间3D姿态估计,而是更加注重几何信息和运动信息的融合。
关键设计:几何感知提升模块采用了双扫描Mamba架构,通过正向和反向两次扫描图像特征,从而更好地理解图像的几何信息。运动引导重建网络的具体结构未知,但其核心在于如何有效地利用3D姿态序列作为锚点,并建模时间上的运动模式。论文中未提及具体的损失函数和参数设置等细节,这部分信息未知。
🖼️ 关键图片

📊 实验亮点
HMRMamba在3DPW、MPI-INF-3DHP和Human3.6M等多个benchmark上取得了state-of-the-art的结果,证明了其在重建精度和时间一致性方面的优越性。具体的性能数据和提升幅度未知,但摘要中明确指出HMRMamba优于现有方法,并具有更高的计算效率。
🎯 应用场景
HMRMamba在虚拟现实、增强现实、游戏开发、运动分析、人机交互等领域具有广泛的应用前景。它可以用于创建更逼真、更自然的虚拟人物,也可以用于分析运动员的运动姿态,从而提高训练效果。此外,HMRMamba还可以用于开发更智能的人机交互系统,例如,通过识别用户的身体姿态,从而实现更自然的人机交互。
📄 摘要(原文)
Existing video-based 3D Human Mesh Recovery (HMR) methods often produce physically implausible results, stemming from their reliance on flawed intermediate 3D pose anchors and their inability to effectively model complex spatiotemporal dynamics. To overcome these deep-rooted architectural problems, we introduce HMRMamba, a new paradigm for HMR that pioneers the use of Structured State Space Models (SSMs) for their efficiency and long-range modeling prowess. Our framework is distinguished by two core contributions. First, the Geometry-Aware Lifting Module, featuring a novel dual-scan Mamba architecture, creates a robust foundation for reconstruction. It directly grounds the 2D-to-3D pose lifting process with geometric cues from image features, producing a highly reliable 3D pose sequence that serves as a stable anchor. Second, the Motion-guided Reconstruction Network leverages this anchor to explicitly process kinematic patterns over time. By injecting this crucial temporal awareness, it significantly enhances the final mesh's coherence and robustness, particularly under occlusion and motion blur. Comprehensive evaluations on 3DPW, MPI-INF-3DHP, and Human3.6M benchmarks confirm that HMRMamba sets a new state-of-the-art, outperforming existing methods in both reconstruction accuracy and temporal consistency while offering superior computational efficiency.