WorldBench: Disambiguating Physics for Diagnostic Evaluation of World Models
作者: Rishi Upadhyay, Howard Zhang, Jim Solomon, Ayush Agrawal, Pranay Boreddy, Shruti Satya Narayana, Yunhao Ba, Alex Wong, Celso M de Melo, Achuta Kadambi
分类: cs.CV
发布日期: 2026-01-29
备注: Webpage: https://world-bench.github.io/
💡 一句话要点
WorldBench:用于诊断世界模型物理理解能力的解耦视频基准测试
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 物理推理 视频基准测试 解耦评估 物理概念
📋 核心要点
- 现有物理视频基准测试存在纠缠问题,无法有效诊断世界模型对特定物理概念的理解。
- WorldBench通过解耦的、概念特定的视频测试,隔离评估世界模型对单个物理定律的理解。
- 实验表明,现有SOTA世界模型在特定物理概念上存在失败模式,缺乏足够的物理一致性。
📝 摘要(中文)
生成式基础模型(又称“世界模型”)的最新进展激发了人们将其应用于机器人规划和自主系统训练等关键任务的兴趣。为了可靠部署,这些模型必须表现出高度的物理保真度,准确模拟真实世界的动力学。然而,现有的基于物理的视频基准测试存在纠缠问题,即单个测试同时评估多个物理定律和概念,从根本上限制了其诊断能力。我们引入了WorldBench,这是一种新颖的基于视频的基准测试,专门用于概念特定的、解耦的评估,从而能够严格地隔离和评估对单个物理概念或定律的理解。为了使WorldBench具有全面性,我们设计了两个不同级别的基准测试:1)评估对直观物理的理解,包括物体永存或尺度/透视等概念,以及2)评估低级物理常数和材料属性,例如摩擦系数或流体粘度。当在WorldBench上评估SOTA的基于视频的世界模型时,我们发现特定物理概念中存在特定的失败模式,所有测试模型都缺乏生成可靠的真实世界交互所需的物理一致性。通过其概念特定的评估,WorldBench为严格评估视频生成和世界模型的物理推理能力提供了一个更细致和可扩展的框架,为更强大和更通用的世界模型驱动学习铺平了道路。
🔬 方法详解
问题定义:现有的基于物理的视频基准测试存在“纠缠”问题,即一个测试用例同时评估多个物理定律和概念。这使得我们难以确定世界模型究竟在哪个具体的物理概念上存在理解偏差或错误。因此,需要一种能够针对特定物理概念进行独立评估的基准测试。
核心思路:WorldBench的核心思路是设计一系列解耦的视频测试用例,每个用例专注于评估一个特定的物理概念或定律。通过这种方式,可以精确地诊断世界模型在哪些物理概念上存在不足,从而为改进模型提供更明确的方向。
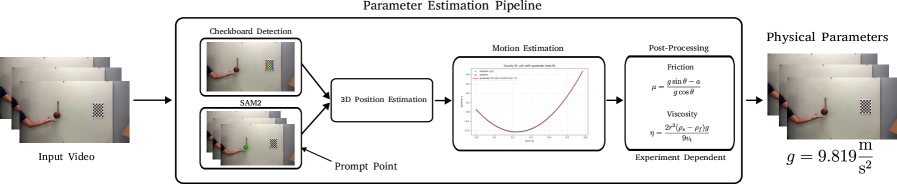
技术框架:WorldBench包含两个层级的基准测试: 1. 直观物理理解:评估模型对物体永存、尺度/透视等直观物理概念的理解。 2. 低级物理常数和材料属性:评估模型对摩擦系数、流体粘度等物理常数和材料属性的理解。 每个层级都包含多个精心设计的视频测试用例,用于评估模型在特定物理概念上的表现。评估过程通常涉及比较模型生成的视频与真实视频,或者评估模型对视频中物理事件的预测准确性。
关键创新:WorldBench的关键创新在于其解耦的设计,能够针对特定物理概念进行独立评估。这与现有的纠缠基准测试形成鲜明对比,后者难以诊断模型在哪些具体方面存在不足。此外,WorldBench还涵盖了从直观物理到低级物理常数的广泛物理概念,使其成为一个全面的评估工具。
关键设计:WorldBench的关键设计在于其视频测试用例的设计。每个用例都经过精心设计,以确保它主要评估一个特定的物理概念,并尽量减少其他因素的干扰。例如,在评估物体永存概念的用例中,物体可能会被短暂遮挡,以测试模型是否能够记住物体的位置和状态。在评估摩擦系数的用例中,物体会在不同材质的表面上滑动,以测试模型是否能够准确预测物体的运动轨迹。
🖼️ 关键图片


📊 实验亮点
在WorldBench上对SOTA世界模型的评估表明,这些模型在特定物理概念上存在明显的失败模式,例如对摩擦、流体动力学等概念的理解不足。所有测试模型都未能达到生成可靠的真实世界交互所需的物理一致性。这些结果突显了现有世界模型在物理推理方面的局限性,并强调了WorldBench在诊断和改进这些模型方面的重要性。
🎯 应用场景
WorldBench可用于评估和改进世界模型在机器人规划、自动驾驶、游戏AI等领域的应用。通过诊断模型在特定物理概念上的不足,可以指导模型训练,提高其在真实世界中的泛化能力和可靠性。此外,该基准测试还可以促进对物理推理能力更强的世界模型的研究。
📄 摘要(原文)
Recent advances in generative foundational models, often termed "world models," have propelled interest in applying them to critical tasks like robotic planning and autonomous system training. For reliable deployment, these models must exhibit high physical fidelity, accurately simulating real-world dynamics. Existing physics-based video benchmarks, however, suffer from entanglement, where a single test simultaneously evaluates multiple physical laws and concepts, fundamentally limiting their diagnostic capability. We introduce WorldBench, a novel video-based benchmark specifically designed for concept-specific, disentangled evaluation, allowing us to rigorously isolate and assess understanding of a single physical concept or law at a time. To make WorldBench comprehensive, we design benchmarks at two different levels: 1) an evaluation of intuitive physical understanding with concepts such as object permanence or scale/perspective, and 2) an evaluation of low-level physical constants and material properties such as friction coefficients or fluid viscosity. When SOTA video-based world models are evaluated on WorldBench, we find specific patterns of failure in particular physics concepts, with all tested models lacking the physical consistency required to generate reliable real-world interactions. Through its concept-specific evaluation, WorldBench offers a more nuanced and scalable framework for rigorously evaluating the physical reasoning capabilities of video generation and world models, paving the way for more robust and generalizable world-model-driven learning.