LAMP: Learning Universal Adversarial Perturbations for Multi-Image Tasks via Pre-trained Models
作者: Alvi Md Ishmam, Najibul Haque Sarker, Zaber Ibn Abdul Hakim, Chris Thomas
分类: cs.CV
发布日期: 2026-01-29
备注: Accepted in main technical track AAAI 2026
💡 一句话要点
LAMP:通过预训练模型学习多图像任务的通用对抗扰动
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 对抗攻击 通用对抗扰动 黑盒攻击 视觉语言模型
📋 核心要点
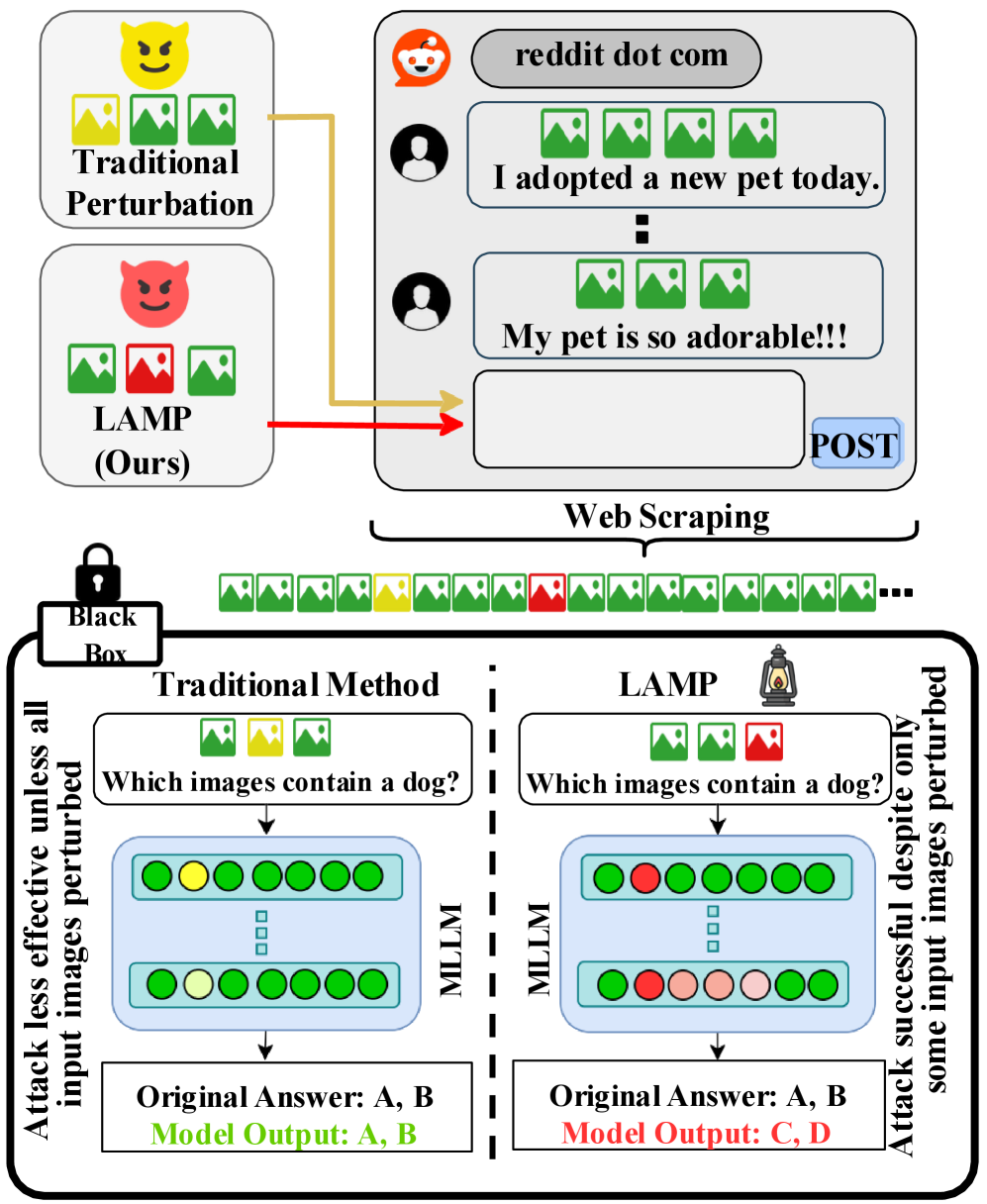
- 现有对抗攻击主要针对单图像,且依赖不切实际的白盒假设,忽略了多图像MLLM的脆弱性。
- LAMP通过注意力约束、跨图像传染约束和索引注意力抑制损失,实现了黑盒通用对抗扰动攻击。
- 实验表明,LAMP在多种视觉-语言任务和模型上,攻击成功率超越了现有最优方法。
📝 摘要(中文)
多模态大型语言模型(MLLM)在视觉-语言任务中取得了显著的性能。最近的进展使得这些模型能够处理多个图像作为输入。然而,多图像MLLM的脆弱性仍未被探索。现有的对抗攻击主要集中在单图像设置,并且通常假设白盒威胁模型,这在许多现实场景中是不切实际的。本文介绍了一种黑盒方法LAMP,用于学习针对多图像MLLM的通用对抗扰动(UAP)。LAMP应用了一种基于注意力的约束,以阻止模型有效地聚合跨图像的信息。LAMP还引入了一种新颖的跨图像传染约束,该约束迫使受扰动的token影响干净的token,从而在不需要修改所有输入的情况下传播对抗效果。此外,索引注意力抑制损失实现了鲁棒的位置不变攻击。实验结果表明,LAMP优于SOTA基线,并在多个视觉-语言任务和模型中实现了最高的攻击成功率。
🔬 方法详解
问题定义:论文旨在解决多图像多模态大语言模型(MLLM)在面对对抗攻击时的脆弱性问题。现有的对抗攻击方法主要集中于单张图像,并且通常假设攻击者拥有模型的全部信息(白盒攻击),这在实际应用中是不现实的。因此,如何在黑盒场景下,有效地攻击多图像MLLM是一个亟待解决的问题。
核心思路:论文的核心思路是通过学习一种通用的对抗扰动(Universal Adversarial Perturbation, UAP),使其能够应用于不同的输入图像,从而欺骗多图像MLLM。为了实现这一目标,论文设计了多种约束和损失函数,以增强扰动的攻击性和泛化能力。
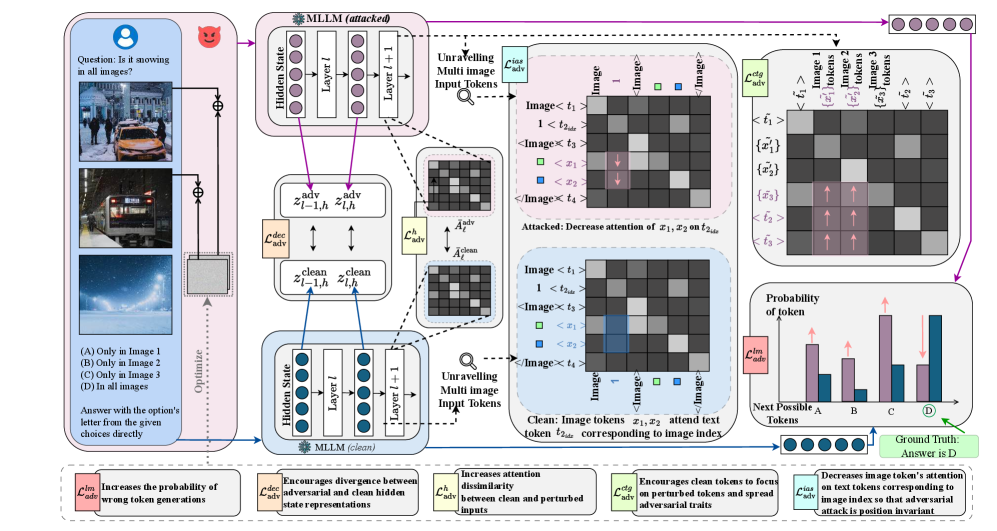
技术框架:LAMP的整体框架包括以下几个关键模块:1) 扰动生成器:负责生成对抗扰动。2) 注意力约束模块:阻止模型有效地聚合跨图像的信息。3) 跨图像传染约束模块:迫使受扰动的token影响干净的token,传播对抗效果。4) 索引注意力抑制损失:实现鲁棒的位置不变攻击。整个流程是,首先生成扰动,然后将其添加到输入图像中,再将扰动后的图像输入到MLLM中,最后通过计算损失函数来优化扰动生成器。
关键创新:LAMP的关键创新在于以下几个方面:1) 黑盒攻击:无需访问模型内部参数,更符合实际应用场景。2) 通用对抗扰动:生成的扰动可以应用于不同的输入图像,具有更强的泛化能力。3) 跨图像传染约束:通过迫使受扰动的token影响干净的token,实现了更有效的攻击。4) 索引注意力抑制损失:增强了攻击的位置不变性。
关键设计:LAMP的关键设计包括:1) 注意力约束:通过限制模型对不同图像的注意力权重,阻止模型有效地聚合跨图像的信息。具体实现方式未知。2) 跨图像传染约束:通过设计特定的损失函数,迫使受扰动的token影响干净的token,从而传播对抗效果。具体实现方式未知。3) 索引注意力抑制损失:通过抑制特定位置的注意力权重,增强攻击的位置不变性。具体实现方式未知。4) 扰动生成器:具体网络结构未知,但其目标是生成能够欺骗MLLM的对抗扰动。
🖼️ 关键图片

📊 实验亮点
LAMP在多个视觉-语言任务和模型上实现了最高的攻击成功率,超越了现有最优方法。具体性能数据未知,但论文强调了LAMP在黑盒攻击和通用对抗扰动方面的优势,以及跨图像传染约束和索引注意力抑制损失的有效性。
🎯 应用场景
该研究成果可应用于评估和提升多模态大语言模型的安全性,尤其是在图像理解、视觉问答等任务中。通过发现模型的脆弱性,可以促进更鲁棒的模型的开发,从而提高模型在实际应用中的可靠性,例如自动驾驶、医疗诊断等领域。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved remarkable performance across vision-language tasks. Recent advancements allow these models to process multiple images as inputs. However, the vulnerabilities of multi-image MLLMs remain unexplored. Existing adversarial attacks focus on single-image settings and often assume a white-box threat model, which is impractical in many real-world scenarios. This paper introduces LAMP, a black-box method for learning Universal Adversarial Perturbations (UAPs) targeting multi-image MLLMs. LAMP applies an attention-based constraint that prevents the model from effectively aggregating information across images. LAMP also introduces a novel cross-image contagious constraint that forces perturbed tokens to influence clean tokens, spreading adversarial effects without requiring all inputs to be modified. Additionally, an index-attention suppression loss enables a robust position-invariant attack. Experimental results show that LAMP outperforms SOTA baselines and achieves the highest attack success rates across multiple vision-language tasks and models.