Thinker: A vision-language foundation model for embodied intelligence
作者: Baiyu Pan, Daqin Luo, Junpeng Yang, Jiyuan Wang, Yixuan Zhang, Hailin Shi, Jichao Jiao
分类: cs.CV, cs.AI
发布日期: 2026-01-29
备注: IROS 2025, 4 pages, 3 figures
💡 一句话要点
Thinker:面向具身智能的视觉-语言基础模型,解决机器人感知与推理难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视觉-语言模型 机器人感知 时间推理 任务规划 自我视角视频 关键帧 视频理解
📋 核心要点
- 现有视觉-语言模型在机器人领域应用时,易混淆视角,忽略视频结尾信息,导致感知和推理出现偏差。
- Thinker模型构建大规模机器人数据集,并创新性地联合使用关键帧和完整视频序列,提升视频理解能力。
- Thinker模型在任务规划基准数据集上取得了SOTA结果,验证了其在具身智能领域的有效性。
📝 摘要(中文)
本文提出了Thinker,一个专为具身智能设计的视觉-语言基础模型,旨在解决现有大型视觉-语言模型在机器人领域应用时遇到的问题,例如第一人称和第三人称视角混淆,以及在时间推理中忽略视频结尾信息等。该模型从两个方面入手:首先,构建了一个大规模数据集,专门用于机器人感知和推理,包含自我视角视频、视觉定位、空间理解和思维链数据。其次,引入了一种简单而有效的方法,通过联合使用关键帧和完整视频序列作为输入,显著增强模型对视频的理解能力。实验结果表明,该模型在两个常用的任务规划基准数据集上取得了最先进的性能。
🔬 方法详解
问题定义:现有的大型视觉-语言模型在应用于机器人领域时,面临着一些对人类来说很简单但对模型来说却容易出错的问题。具体来说,包括混淆第三人称和第一人称视角,以及在时间推理过程中倾向于忽略视频结尾的信息。这些问题限制了模型在具身智能任务中的应用。
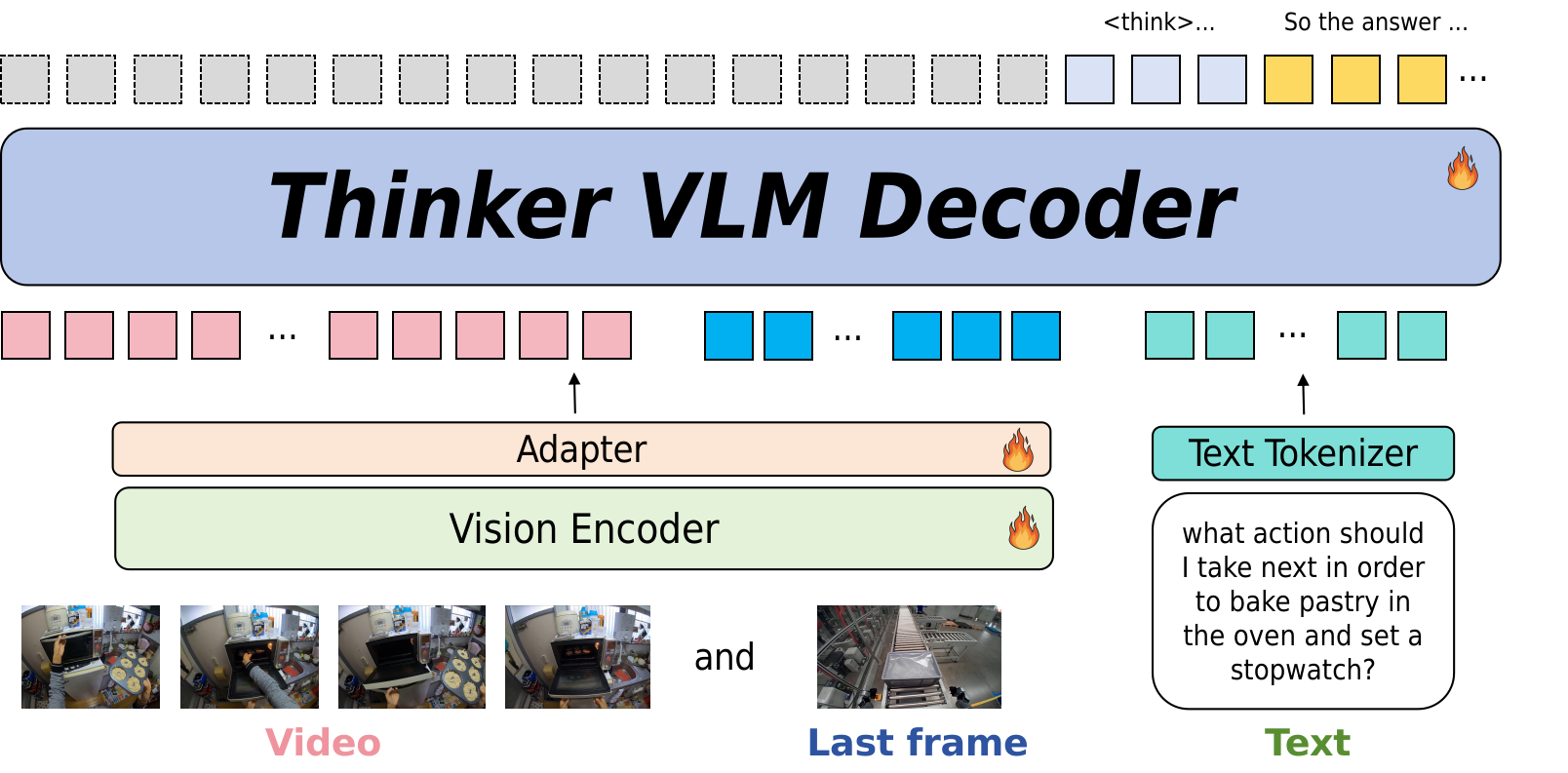
核心思路:Thinker模型的核心思路是从数据和模型结构两个方面入手,解决上述问题。一方面,构建一个大规模、高质量的机器人感知和推理数据集,为模型提供更丰富的训练数据。另一方面,设计一种能够有效利用视频信息的模型结构,提高模型对视频的理解能力。
技术框架:Thinker模型的整体框架包括数据构建和模型训练两个阶段。在数据构建阶段,收集并标注了包含自我视角视频、视觉定位、空间理解和思维链数据的大规模数据集。在模型训练阶段,将关键帧和完整视频序列联合作为输入,训练视觉-语言模型。模型具体结构未知。
关键创新:Thinker模型最重要的技术创新点在于联合使用关键帧和完整视频序列作为输入,从而更有效地利用视频信息。这种方法能够帮助模型更好地理解视频内容,提高其在时间推理任务中的性能。此外,构建大规模机器人数据集也是一个重要贡献。
关键设计:论文中提到了一种简单而有效的方法,但没有详细说明关键帧的选择方法、损失函数、网络结构等技术细节。这些细节属于未知信息。
🖼️ 关键图片

📊 实验亮点
Thinker模型在两个常用的任务规划基准数据集上取得了最先进的性能,证明了其在具身智能领域的有效性。具体的性能数据和对比基线未在摘要中给出,属于未知信息。但SOTA的结果表明该模型具有显著的优势。
🎯 应用场景
Thinker模型可应用于各种机器人任务,例如家庭服务机器人、工业机器人、自动驾驶等。它可以帮助机器人更好地理解人类指令,感知周围环境,并做出合理的决策。该研究的突破将推动具身智能的发展,使机器人能够更好地服务于人类。
📄 摘要(原文)
When large vision-language models are applied to the field of robotics, they encounter problems that are simple for humans yet error-prone for models. Such issues include confusion between third-person and first-person perspectives and a tendency to overlook information in video endings during temporal reasoning. To address these challenges, we propose Thinker, a large vision-language foundation model designed for embodied intelligence. We tackle the aforementioned issues from two perspectives. Firstly, we construct a large-scale dataset tailored for robotic perception and reasoning, encompassing ego-view videos, visual grounding, spatial understanding, and chain-of-thought data. Secondly, we introduce a simple yet effective approach that substantially enhances the model's capacity for video comprehension by jointly incorporating key frames and full video sequences as inputs. Our model achieves state-of-the-art results on two of the most commonly used benchmark datasets in the field of task planning.