Bidirectional Cross-Perception for Open-Vocabulary Semantic Segmentation in Remote Sensing Imagery
作者: Jianzheng Wang, Huan Ni
分类: cs.CV
发布日期: 2026-01-29
🔗 代码/项目: GITHUB
💡 一句话要点
提出SDCI框架,解决遥感影像开放词汇语义分割中几何定位和语义预测难题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感影像 语义分割 开放词汇 跨模态融合 注意力机制
📋 核心要点
- 现有开放词汇语义分割方法在遥感影像中,难以同时满足几何定位精度和语义预测准确性的高要求。
- SDCI框架通过跨模型注意力融合、双向跨图扩散细化和超像素协同预测,实现更精确的分割。
- 实验表明,SDCI在多个遥感数据集上优于现有方法,并验证了超像素结构在深度学习中的有效性。
📝 摘要(中文)
高分辨率遥感影像具有地物目标密集分布和边界复杂的特点,对几何定位和语义预测提出了更高的要求。现有的免训练开放词汇语义分割(OVSS)方法通常采用“单向注入”和“浅层后处理”策略融合CLIP和视觉基础模型(VFMs),难以满足这些要求。为了解决这个问题,我们提出了一种空间正则化感知的双分支协同推理框架SDCI,用于免训练OVSS。首先,在特征编码过程中,SDCI引入了跨模型注意力融合(CAF)模块,通过将自注意力图相互注入来指导协同推理。其次,我们提出了一种双向跨图扩散细化(BCDR)模块,通过迭代随机游走扩散来增强双分支分割结果的可靠性。最后,我们结合低层超像素结构,并开发了一种基于凸优化的超像素协同预测(CSCP)机制,以进一步细化对象边界。在多个遥感语义分割基准上的实验表明,我们的方法比现有方法取得了更好的性能。此外,消融研究进一步证实了利用超像素结构的传统面向对象遥感图像分析方法在深度学习框架中仍然有效。
🔬 方法详解
问题定义:遥感影像的开放词汇语义分割任务面临着地物密集、边界复杂带来的挑战,现有方法如直接融合CLIP和视觉基础模型,采用单向特征注入和浅层后处理,难以有效利用多模态信息,导致分割精度受限,尤其是在几何定位和语义预测方面。
核心思路:论文的核心思路是设计一个双分支协同推理框架,通过跨模型的信息交互和空间正则化,提升分割的准确性和鲁棒性。具体来说,利用跨模型注意力融合增强特征表达,通过双向跨图扩散细化分割结果,并结合超像素信息优化边界。
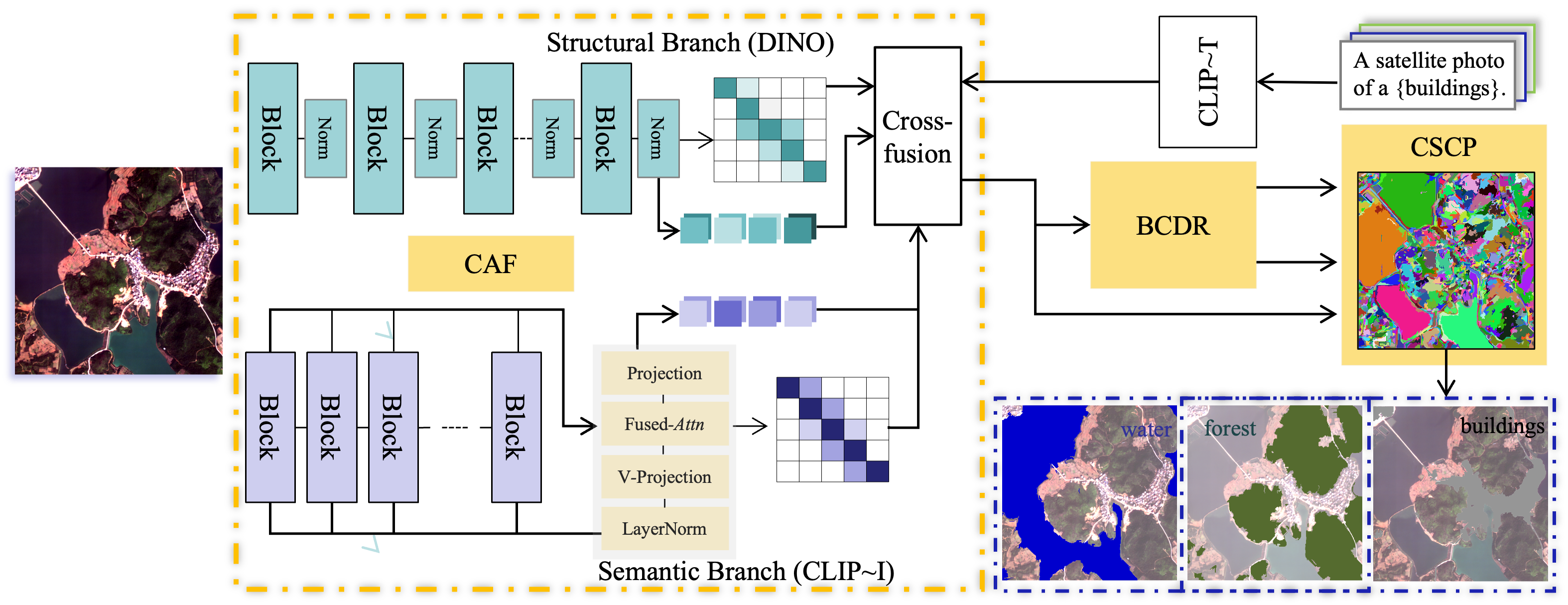
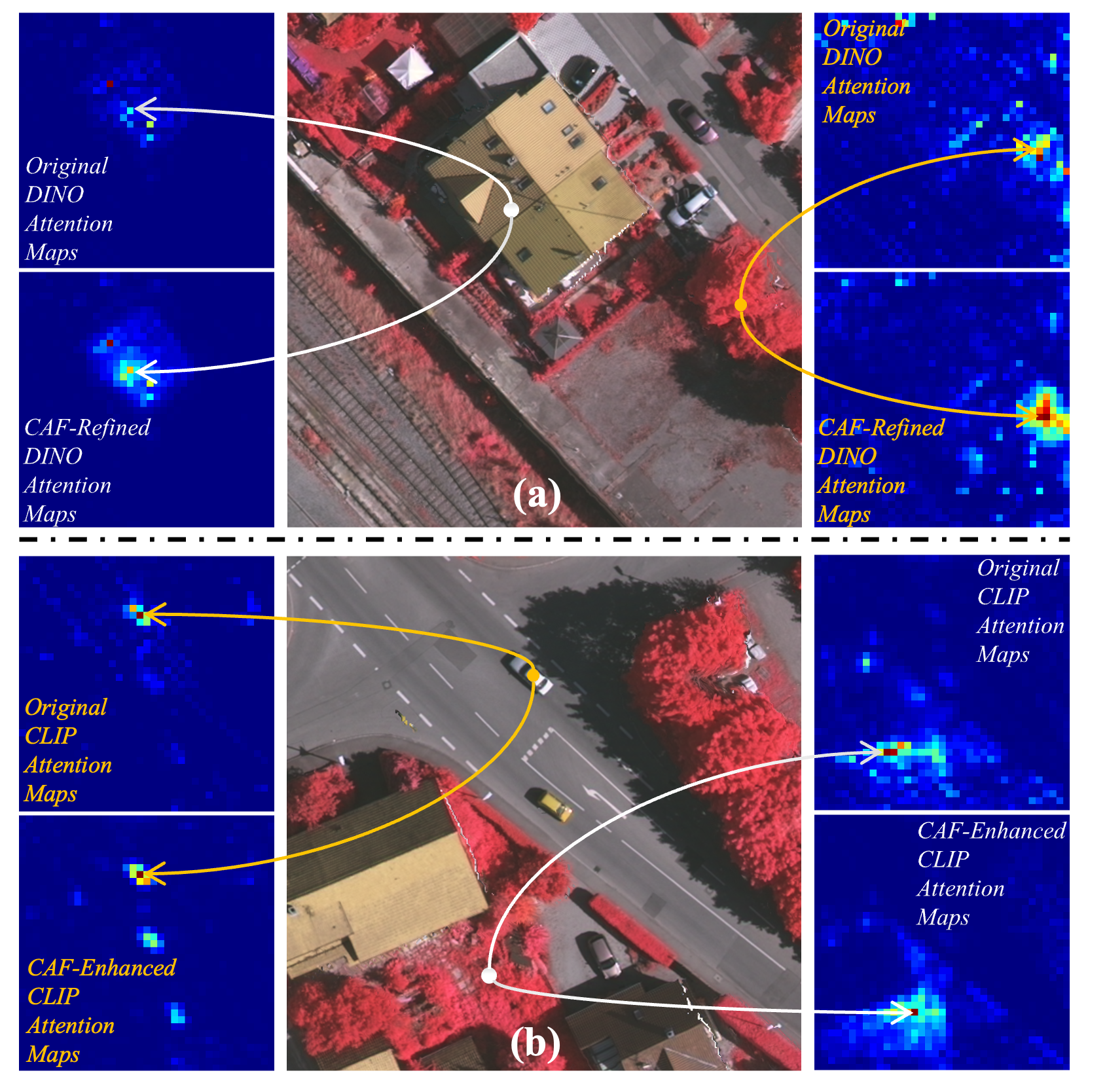
技术框架:SDCI框架包含三个主要模块:1) 跨模型注意力融合(CAF):用于在特征编码阶段,将不同模型的自注意力图相互注入,实现特征的协同表达。2) 双向跨图扩散细化(BCDR):通过迭代随机游走扩散,增强双分支分割结果的一致性和可靠性。3) 超像素协同预测(CSCP):利用低层超像素结构,通过凸优化方法,进一步细化对象边界。
关键创新:论文的关键创新在于提出了一个双向跨感知的协同推理框架,它不同于以往的单向注入和浅层融合方法。通过跨模型注意力融合和双向跨图扩散,实现了更深层次的信息交互和结果优化。此外,将传统的超像素分析方法与深度学习框架相结合,进一步提升了分割精度。
关键设计:CAF模块使用自注意力图作为引导信息,通过注意力机制将一个模型的特征注入到另一个模型中。BCDR模块采用随机游走扩散算法,迭代更新分割结果,并使用双向扩散保证一致性。CSCP模块使用凸优化方法,将超像素作为约束条件,优化像素级别的分割结果。损失函数方面,论文可能使用了交叉熵损失或其他适用于语义分割的损失函数,具体细节在论文中应有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SDCI框架在多个遥感语义分割基准数据集上取得了显著的性能提升,优于现有的开放词汇语义分割方法。消融实验验证了各个模块的有效性,特别是超像素协同预测模块,进一步提升了分割精度。这些结果表明,SDCI框架能够有效解决遥感影像开放词汇语义分割中的挑战。
🎯 应用场景
该研究成果可应用于智慧城市建设、农业监测、灾害评估、环境监测等多个领域。通过高精度的遥感影像语义分割,可以为城市规划提供更准确的地物信息,辅助农作物长势监测和产量预测,快速评估灾害影响范围,并监测环境变化,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
High-resolution remote sensing imagery is characterized by densely distributed land-cover objects and complex boundaries, which places higher demands on both geometric localization and semantic prediction. Existing training-free open-vocabulary semantic segmentation (OVSS) methods typically fuse CLIP and vision foundation models (VFMs) using "one-way injection" and "shallow post-processing" strategies, making it difficult to satisfy these requirements. To address this issue, we propose a spatial-regularization-aware dual-branch collaborative inference framework for training-free OVSS, termed SDCI. First, during feature encoding, SDCI introduces a cross-model attention fusion (CAF) module, which guides collaborative inference by injecting self-attention maps into each other. Second, we propose a bidirectional cross-graph diffusion refinement (BCDR) module that enhances the reliability of dual-branch segmentation scores through iterative random-walk diffusion. Finally, we incorporate low-level superpixel structures and develop a convex-optimization-based superpixel collaborative prediction (CSCP) mechanism to further refine object boundaries. Experiments on multiple remote sensing semantic segmentation benchmarks demonstrate that our method achieves better performance than existing approaches. Moreover, ablation studies further confirm that traditional object-based remote sensing image analysis methods leveraging superpixel structures remain effective within deep learning frameworks. Code: https://github.com/yu-ni1989/SDCI.