FreeFix: Boosting 3D Gaussian Splatting via Fine-Tuning-Free Diffusion Models
作者: Hongyu Zhou, Zisen Shao, Sheng Miao, Pan Wang, Dongfeng Bai, Bingbing Liu, Yiyi Liao
分类: cs.CV
发布日期: 2026-01-28
备注: Our project page is at https://xdimlab.github.io/freefix
💡 一句话要点
FreeFix:通过免微调扩散模型提升3D高斯溅射渲染质量
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 扩散模型 神经渲染 novel view synthesis 免微调 图像细化 多帧一致性
📋 核心要点
- 现有神经渲染方法依赖密集输入,外推视角下性能下降,且微调扩散模型易过拟合。
- FreeFix 提出免微调的 2D-3D 交错细化策略,利用预训练图像扩散模型提升渲染质量。
- 实验表明,FreeFix 在保持泛化性的同时,实现了与微调方法相当甚至更优的性能。
📝 摘要(中文)
神经辐射场和3D高斯溅射技术在 novel view synthesis 领域取得了显著进展,但它们仍然依赖于密集的输入,并且在推断视角下性能会下降。最近的方法利用生成模型(如扩散模型)来提供额外的监督,但面临泛化性和保真度之间的权衡:为去除伪影而微调扩散模型会提高保真度,但也存在过拟合的风险;而免微调方法虽然保留了泛化能力,但通常会产生较低的保真度。我们提出了 FreeFix,一种免微调方法,通过使用预训练的图像扩散模型来增强外推渲染,从而突破了这种权衡的界限。我们提出了一种交错的2D-3D细化策略,表明图像扩散模型可以用于一致的细化,而无需依赖昂贵的视频扩散模型。此外,我们更仔细地研究了2D细化的指导信号,并提出了一个逐像素置信度掩码,以识别不确定区域进行有针对性的改进。在多个数据集上的实验表明,FreeFix 提高了多帧一致性,并实现了与基于微调的方法相当或超过的性能,同时保持了强大的泛化能力。
🔬 方法详解
问题定义:现有神经渲染方法,如3D高斯溅射,在 novel view synthesis 任务中表现出色,但依赖于密集的输入视图。当输入视图稀疏或需要外推到未见过的视角时,渲染质量会显著下降。利用扩散模型进行增强的方法,要么需要对扩散模型进行微调,导致过拟合和泛化能力下降,要么采用免微调策略,但渲染质量提升有限。
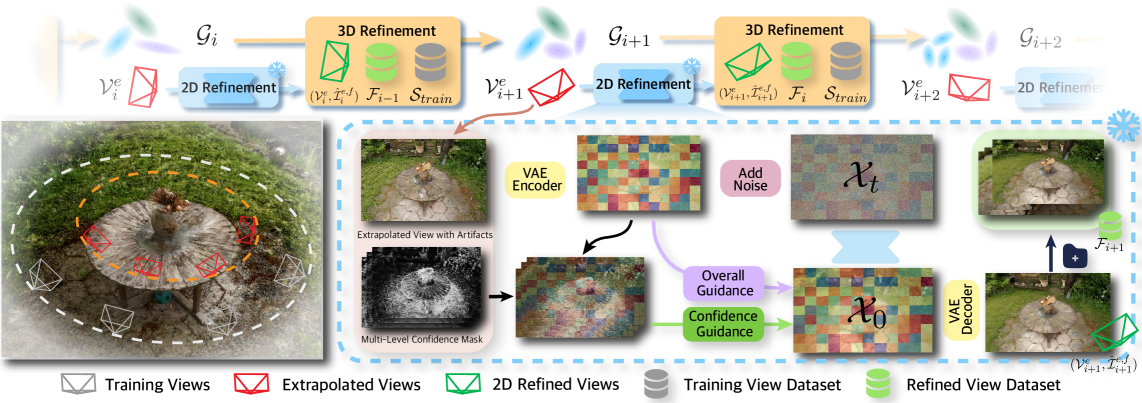
核心思路:FreeFix 的核心思路是利用预训练的图像扩散模型,在不进行微调的情况下,对3D高斯溅射的渲染结果进行后处理,从而提高渲染质量和多帧一致性。通过交错的2D-3D细化策略,将图像扩散模型的先验知识融入到3D场景的渲染中,同时避免了微调带来的过拟合问题。
技术框架:FreeFix 的整体框架包含以下几个主要步骤:1) 使用3D高斯溅射进行初始渲染;2) 使用预训练的图像扩散模型对渲染结果进行2D细化;3) 将细化后的2D图像反投影回3D空间,更新3D高斯参数;4) 重复2D细化和3D更新过程,直到达到预定的迭代次数。该框架的关键在于2D细化和3D更新的交错进行,以及如何有效地利用图像扩散模型的指导信号。
关键创新:FreeFix 的关键创新在于提出了一种免微调的扩散模型应用方法,以及一种交错的2D-3D细化策略。与现有方法相比,FreeFix 避免了对扩散模型的微调,从而保留了其强大的泛化能力。同时,通过交错的2D-3D细化,实现了对3D场景渲染结果的有效增强,提高了渲染质量和多帧一致性。
关键设计:FreeFix 的关键设计包括:1) 使用预训练的图像扩散模型进行2D细化,例如 Stable Diffusion;2) 提出了一种逐像素置信度掩码,用于识别渲染结果中的不确定区域,并对这些区域进行有针对性的细化;3) 设计了一种损失函数,用于指导3D高斯参数的更新,以最小化细化后的2D图像与原始渲染结果之间的差异,同时保持场景的一致性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FreeFix 在多个数据集上取得了显著的性能提升。例如,在 NeRF++ 数据集上,FreeFix 的 PSNR 指标提高了 1-2 dB,SSIM 指标提高了 0.02-0.04。与基于微调的方法相比,FreeFix 在保持泛化能力的同时,实现了相当甚至更优的性能。此外,FreeFix 显著提高了多帧一致性,减少了渲染结果中的伪影和抖动。
🎯 应用场景
FreeFix 可应用于 novel view synthesis、3D场景重建、虚拟现实和增强现实等领域。该方法能够提高渲染质量和多帧一致性,从而改善用户体验。此外,FreeFix 的免微调特性使其更易于部署和应用,降低了对计算资源和专业知识的要求。未来,该方法有望应用于自动驾驶、机器人导航等需要高质量3D场景理解的领域。
📄 摘要(原文)
Neural Radiance Fields and 3D Gaussian Splatting have advanced novel view synthesis, yet still rely on dense inputs and often degrade at extrapolated views. Recent approaches leverage generative models, such as diffusion models, to provide additional supervision, but face a trade-off between generalization and fidelity: fine-tuning diffusion models for artifact removal improves fidelity but risks overfitting, while fine-tuning-free methods preserve generalization but often yield lower fidelity. We introduce FreeFix, a fine-tuning-free approach that pushes the boundary of this trade-off by enhancing extrapolated rendering with pretrained image diffusion models. We present an interleaved 2D-3D refinement strategy, showing that image diffusion models can be leveraged for consistent refinement without relying on costly video diffusion models. Furthermore, we take a closer look at the guidance signal for 2D refinement and propose a per-pixel confidence mask to identify uncertain regions for targeted improvement. Experiments across multiple datasets show that FreeFix improves multi-frame consistency and achieves performance comparable to or surpassing fine-tuning-based methods, while retaining strong generalization ability.