Open-Vocabulary Functional 3D Human-Scene Interaction Generation
作者: Jie Liu, Yu Sun, Alpar Cseke, Yao Feng, Nicolas Heron, Michael J. Black, Yan Zhang
分类: cs.CV, cs.AI
发布日期: 2026-01-28
备注: 18 pages
💡 一句话要点
提出FunHSI框架,实现开放词汇的功能性3D人-场景交互生成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人-场景交互 3D场景理解 功能推理 视觉-语言模型 姿态生成
📋 核心要点
- 现有方法缺乏对物体功能和人-场景接触的显式推理,导致生成的人-场景交互不合理或功能不正确。
- FunHSI框架通过功能感知的接触推理、视觉-语言模型和阶段性优化,实现了功能正确且物理合理的人-场景交互生成。
- 实验表明,FunHSI在各种场景中生成了更合理和功能性的人-场景交互,支持通用和细粒度的交互任务。
📝 摘要(中文)
本文提出FunHSI,一个无需训练、功能驱动的框架,用于从开放词汇的任务提示中生成功能正确的人-场景交互。该框架通过功能感知的接触推理来识别场景中的功能元素,重建其3D几何形状,并通过接触图对高级交互进行建模。然后,利用视觉-语言模型合成图像中执行任务的人,并估计提出的3D身体和手部姿势。最后,通过阶段性的优化来细化提出的3D身体配置,以确保物理合理性和功能正确性。与现有方法相比,FunHSI不仅合成了更合理的通用3D交互,例如“坐在沙发上”,还支持细粒度的功能性人-场景交互,例如“提高室温”。大量实验表明,FunHSI在各种室内和室外场景中始终如一地生成功能正确且物理合理的人-场景交互。
🔬 方法详解
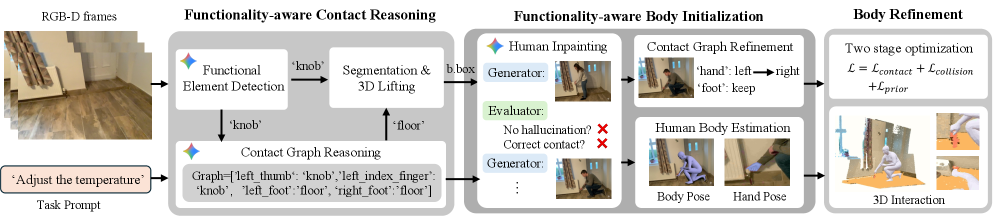
问题定义:论文旨在解决3D人与3D场景进行功能性交互生成的问题。现有方法的痛点在于缺乏对场景中功能元素的显式推理,以及对人与场景之间接触关系的建模,导致生成的结果在功能上不正确或者在物理上不合理。例如,无法准确生成“人打开冰箱”或者“人坐在椅子上”这类需要理解物体功能和人与物体交互关系的场景。
核心思路:论文的核心思路是利用功能感知的接触推理来显式地建模人与场景之间的交互关系。具体来说,首先识别场景中的功能元素,然后重建这些元素的3D几何形状,并使用接触图来表示人与这些功能元素之间的高级交互。之后,利用视觉-语言模型来生成人的姿态,并通过优化来保证姿态的物理合理性和功能正确性。
技术框架:FunHSI框架主要包含以下几个阶段:1) 功能元素识别与重建:根据任务提示,识别场景中的功能元素,并重建其3D几何形状。2) 接触图构建:构建接触图来表示人与功能元素之间的高级交互关系。3) 人体姿态生成:利用视觉-语言模型生成执行任务的人体姿态。4) 姿态优化:通过阶段性的优化来细化人体姿态,确保物理合理性和功能正确性。
关键创新:该论文的关键创新在于提出了一个无需训练、功能驱动的框架,能够从开放词汇的任务提示中生成功能正确的人-场景交互。与现有方法相比,FunHSI能够显式地推理场景中的功能元素,并建模人与这些元素之间的交互关系,从而生成更合理和功能性的人-场景交互。
关键设计:在功能元素识别阶段,使用了预训练的3D场景理解模型来识别场景中的功能元素。在接触图构建阶段,使用了基于规则的方法来确定人与功能元素之间的交互关系。在人体姿态生成阶段,使用了预训练的视觉-语言模型来生成初始的人体姿态。在姿态优化阶段,使用了基于物理的优化方法来保证姿态的物理合理性,并使用基于功能的损失函数来保证姿态的功能正确性。具体损失函数和参数设置未知。
🖼️ 关键图片


📊 实验亮点
FunHSI在各种室内和室外场景中生成了功能正确且物理合理的人-场景交互。与现有方法相比,FunHSI不仅合成了更合理的通用3D交互,例如“坐在沙发上”,还支持细粒度的功能性人-场景交互,例如“提高室温”。具体性能数据和对比基线未知。
🎯 应用场景
该研究成果可应用于具身智能、机器人和交互式内容创作等领域。例如,可以用于训练机器人与环境进行交互,生成虚拟现实或增强现实环境中的人-场景交互内容,以及辅助设计人员创建更逼真的人-场景交互动画。
📄 摘要(原文)
Generating 3D humans that functionally interact with 3D scenes remains an open problem with applications in embodied AI, robotics, and interactive content creation. The key challenge involves reasoning about both the semantics of functional elements in 3D scenes and the 3D human poses required to achieve functionality-aware interaction. Unfortunately, existing methods typically lack explicit reasoning over object functionality and the corresponding human-scene contact, resulting in implausible or functionally incorrect interactions. In this work, we propose FunHSI, a training-free, functionality-driven framework that enables functionally correct human-scene interactions from open-vocabulary task prompts. Given a task prompt, FunHSI performs functionality-aware contact reasoning to identify functional scene elements, reconstruct their 3D geometry, and model high-level interactions via a contact graph. We then leverage vision-language models to synthesize a human performing the task in the image and estimate proposed 3D body and hand poses. Finally, the proposed 3D body configuration is refined via stage-wise optimization to ensure physical plausibility and functional correctness. In contrast to existing methods, FunHSI not only synthesizes more plausible general 3D interactions, such as "sitting on a sofa'', while supporting fine-grained functional human-scene interactions, e.g., "increasing the room temperature''. Extensive experiments demonstrate that FunHSI consistently generates functionally correct and physically plausible human-scene interactions across diverse indoor and outdoor scenes.