Compression Tells Intelligence: Visual Coding, Visual Token Technology, and the Unification
作者: Xin Jin, Jinming Liu, Yuntao Wei, Junyan Lin, Zhicheng Wang, Jianguo Huang, Xudong Yang, Yanxiao Liu, Wenjun Zeng
分类: cs.CV
发布日期: 2026-01-28
💡 一句话要点
统一视觉编码与视觉Token技术,为多模态大模型及具身智能提供高效压缩方案
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉编码 视觉Token技术 多模态学习 大型语言模型 压缩算法 AI生成内容 具身智能
📋 核心要点
- 现有视觉编码和视觉Token技术各自发展,缺乏统一视角,难以充分挖掘压缩效率和模型性能的潜力。
- 本文从优化角度统一视觉编码和视觉Token技术,揭示了压缩效率与模型性能的权衡本质,并提出了统一的公式。
- 实验表明,面向任务的Token技术在多模态LLM、AIGC和具身AI等领域具有巨大潜力,为通用Token技术标准化提供了思路。
📝 摘要(中文)
本文探讨了人工智能领域中,尤其是在(多模态)大型语言模型(LLMs/MLLMs)中,压缩效率与模型性能和能力之间的相关性。文章首先全面概述了两种主要技术体系——视觉编码和视觉Token技术。然后,从优化的角度统一了这两种技术,讨论了压缩效率和模型性能之间的权衡本质。基于统一的公式,文章综合了视觉编码和视觉Token技术的双向见解,并预测了下一代视觉编解码器和Token技术。最后,实验表明,面向任务的Token技术在多模态LLM(MLLM)、AI生成内容(AIGC)和具身AI等实际任务中具有巨大潜力,并为统一高效地标准化通用Token技术(如传统编解码器H.264/265)以用于各种智能任务提供了可能性。
🔬 方法详解
问题定义:论文旨在解决如何更有效地压缩视觉信息,以提高多模态大型语言模型(MLLMs)、AI生成内容(AIGC)和具身AI等应用的性能。现有视觉编码技术和视觉Token技术各自独立发展,缺乏统一的理论框架,无法充分利用彼此的优势,并且在压缩效率和模型性能之间存在权衡问题。
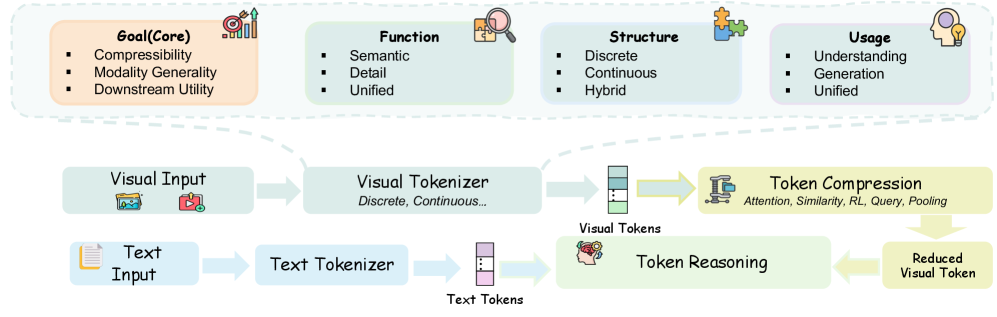
核心思路:论文的核心思路是将视觉编码和视觉Token技术视为同一优化问题的不同实现方式,即在最大化语义信息保真度的同时,最小化计算成本。通过建立统一的数学模型,可以更好地理解这两种技术的本质,并指导下一代视觉压缩技术的发展。
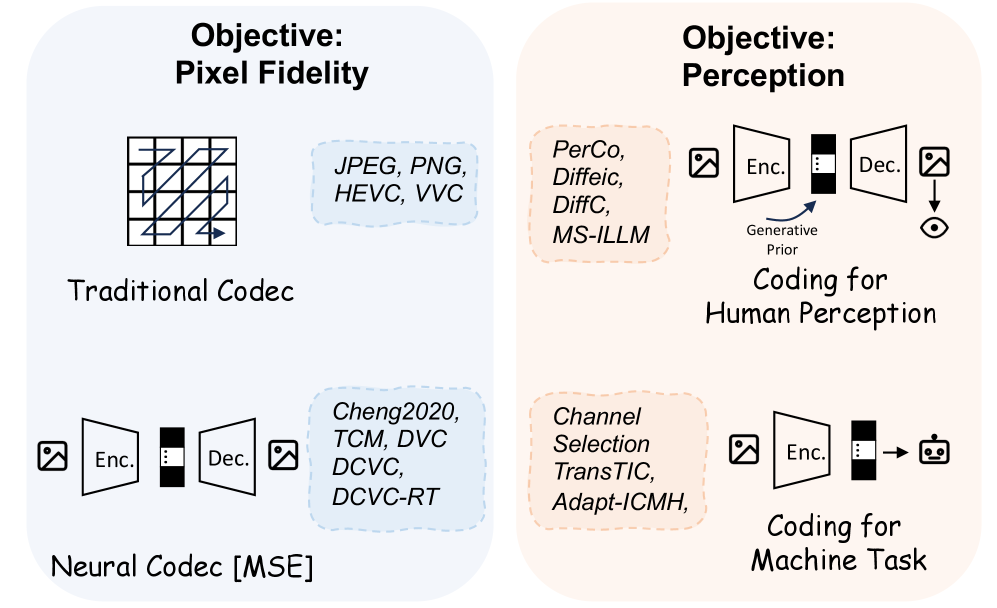
技术框架:论文首先回顾了传统的视觉编码技术,如基于信息论的图像/视频压缩标准(如H.264/H.265)。然后,介绍了新兴的视觉Token技术,这些技术通常用于生成式多模态大模型中。接着,论文提出了一个统一的优化框架,将视觉编码和视觉Token技术都纳入其中。最后,论文通过实验验证了面向任务的Token技术在实际应用中的潜力。
关键创新:论文最重要的创新点在于提出了一个统一的框架,将视觉编码和视觉Token技术联系起来。这种统一视角有助于理解这两种技术的本质,并为未来的研究方向提供了新的思路。此外,论文还强调了面向任务的Token技术的重要性,并展示了其在多模态LLM等领域的潜力。
关键设计:论文的关键设计在于如何建立一个能够同时描述视觉编码和视觉Token技术的统一优化模型。具体的参数设置、损失函数和网络结构等细节可能因不同的应用场景而异,但核心思想是平衡语义信息保真度和计算成本。
🖼️ 关键图片
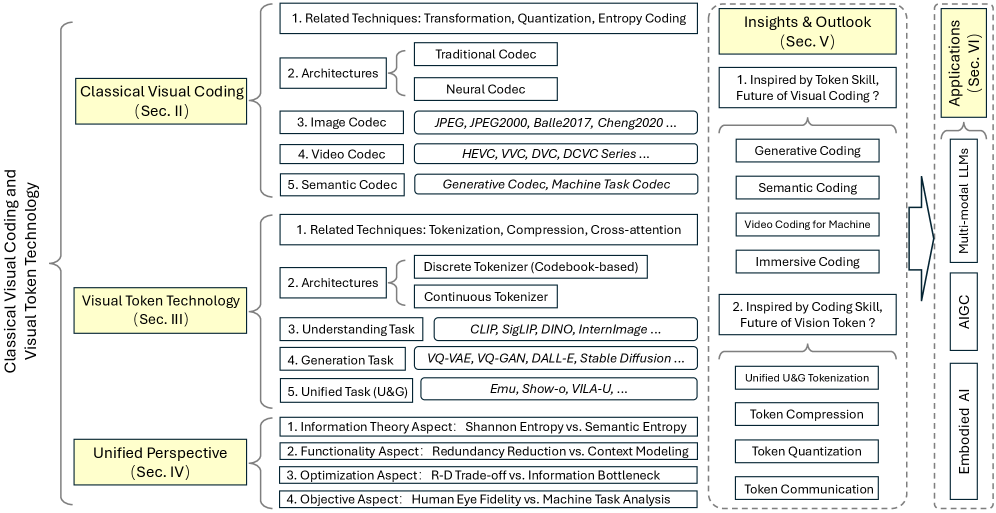
📊 实验亮点
论文通过实验验证了面向任务的Token技术在多模态LLM等实际应用中的潜力,表明该技术能够有效提升模型性能,并降低计算成本。虽然具体性能数据未在摘要中给出,但实验结果为未来视觉Token技术的发展方向提供了重要参考。
🎯 应用场景
该研究成果可应用于多模态大型语言模型(MLLMs)、AI生成内容(AIGC)、具身AI等领域,通过更高效的视觉信息压缩,提升模型性能和推理速度,降低计算资源消耗。未来有望推动通用视觉Token技术的标准化,为各种智能任务提供统一高效的解决方案。
📄 摘要(原文)
"Compression Tells Intelligence", is supported by research in artificial intelligence, particularly concerning (multimodal) large language models (LLMs/MLLMs), where compression efficiency often correlates with improved model performance and capabilities. For compression, classical visual coding based on traditional information theory has developed over decades, achieving great success with numerous international industrial standards widely applied in multimedia (e.g., image/video) systems. Except that, the recent emergingvisual token technology of generative multi-modal large models also shares a similar fundamental objective like visual coding: maximizing semantic information fidelity during the representation learning while minimizing computational cost. Therefore, this paper provides a comprehensive overview of two dominant technique families first -- Visual Coding and Vision Token Technology -- then we further unify them from the aspect of optimization, discussing the essence of compression efficiency and model performance trade-off behind. Next, based on the proposed unified formulation bridging visual coding andvisual token technology, we synthesize bidirectional insights of themselves and forecast the next-gen visual codec and token techniques. Last but not least, we experimentally show a large potential of the task-oriented token developments in the more practical tasks like multimodal LLMs (MLLMs), AI-generated content (AIGC), and embodied AI, as well as shedding light on the future possibility of standardizing a general token technology like the traditional codecs (e.g., H.264/265) with high efficiency for a wide range of intelligent tasks in a unified and effective manner.