Decoupling Perception and Calibration: Label-Efficient Image Quality Assessment Framework
作者: Xinyue Li, Zhichao Zhang, Zhiming Xu, Shubo Xu, Xiongkuo Min, Yitong Chen, Guangtao Zhai
分类: cs.CV, cs.AI
发布日期: 2026-01-28
💡 一句话要点
提出LEAF框架,解耦感知与校准,实现标签高效的图像质量评估
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像质量评估 多模态大语言模型 知识蒸馏 标签高效学习 平均意见得分
📋 核心要点
- 现有基于MLLM的IQA方法计算成本高昂,且依赖大量的MOS标注,限制了其应用。
- LEAF框架解耦了质量感知和MOS尺度校准,利用MLLM教师模型蒸馏知识到轻量级学生模型。
- 实验表明,LEAF框架在显著减少人工标注需求的同时,保持了与MOS对齐的良好相关性。
📝 摘要(中文)
本文提出了一种标签高效的图像质量评估框架LEAF,旨在解决基于多模态大语言模型(MLLM)的IQA任务中计算成本高昂和依赖大量平均意见得分(MOS)标注的问题。LEAF框架的核心思想是将质量感知和MOS尺度校准解耦。该框架首先从MLLM教师模型中提炼感知质量先验知识到一个轻量级的学生回归器中,然后利用少量的MOS标注进行校准。教师模型通过逐点判断和成对偏好进行密集监督,并估计决策可靠性。在这些信号的指导下,学生模型通过联合蒸馏学习教师的质量感知模式,并在一个小的MOS子集上进行校准,以与人类标注对齐。在用户生成和AI生成的IQA基准上的实验表明,该方法显著减少了对人类标注的需求,同时保持了与MOS对齐的强相关性,使得轻量级IQA在有限的标注预算下成为可能。
🔬 方法详解
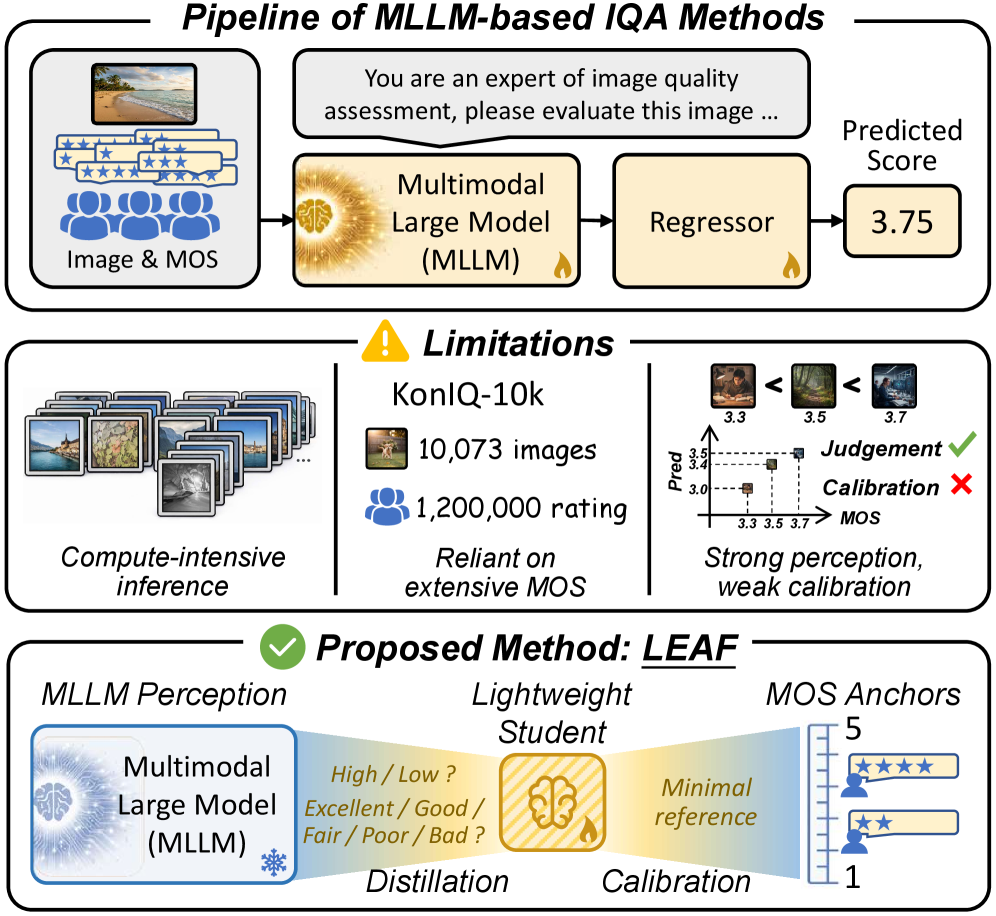
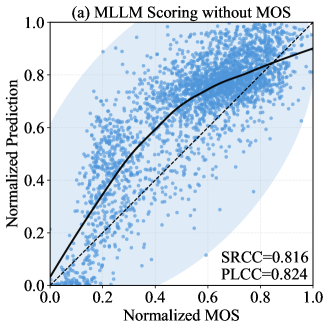
问题定义:现有基于多模态大语言模型(MLLM)的图像质量评估(IQA)方法,虽然展现出强大的能力,但计算资源消耗巨大,并且仍然需要大量的平均意见得分(MOS)标注数据进行训练。这使得它们在标注资源有限的情况下难以应用,阻碍了轻量级IQA模型的发展。
核心思路:论文的核心思路是将IQA任务解耦为两个独立的子任务:质量感知和MOS尺度校准。论文认为,MLLM本身已经具备较强的质量感知能力,因此主要的瓶颈在于如何将MLLM的感知结果校准到与人类主观评价一致的MOS尺度上。因此,通过知识蒸馏将MLLM的感知能力迁移到轻量级模型,然后仅使用少量MOS数据进行校准,可以显著降低标注成本。
技术框架:LEAF框架包含两个主要阶段:教师模型指导下的学生模型训练和MOS尺度校准。首先,利用MLLM教师模型对图像进行质量评估,生成逐点判断、成对偏好以及决策可靠性估计等密集监督信号。然后,利用这些信号,通过联合蒸馏的方式训练一个轻量级的学生回归器,使其学习教师模型的质量感知模式。最后,使用少量的MOS标注数据,对学生模型进行校准,使其输出与人类主观评价对齐。
关键创新:LEAF框架的关键创新在于解耦了质量感知和MOS尺度校准,并提出了一种标签高效的知识蒸馏方法。通过利用MLLM教师模型的密集监督信号,学生模型可以有效地学习质量感知能力,从而减少了对大量MOS标注数据的依赖。此外,决策可靠性估计的引入,使得蒸馏过程更加关注教师模型置信度高的样本,提高了学生模型的学习效率。
关键设计:在教师模型指导下,学生模型通过最小化以下损失函数进行训练:L = L_point + L_pair + L_mos。其中,L_point是逐点判断损失,L_pair是成对偏好损失,L_mos是MOS校准损失。L_point和L_pair用于从教师模型中蒸馏质量感知知识,L_mos用于将学生模型的输出校准到MOS尺度。具体而言,L_point采用均方误差损失,L_pair采用hinge loss,L_mos也采用均方误差损失。学生模型采用轻量级的卷积神经网络结构,以降低计算成本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LEAF框架在用户生成内容(UGC)和AI生成内容(AIGC)的IQA基准上均取得了显著的性能提升。例如,在LIVE-Qualcomm数据集上,LEAF框架仅使用10%的MOS标注数据,即可达到与使用全部MOS标注数据训练的基线方法相当的性能。此外,LEAF框架在AIGCIQA数据集上也取得了领先的结果,证明了其在评估AI生成图像质量方面的有效性。
🎯 应用场景
LEAF框架可应用于各种需要图像质量评估的场景,例如图像/视频压缩、图像/视频增强、图像/视频传输等。该框架尤其适用于标注资源有限的场景,例如用户生成内容(UGC)的质量评估。通过减少对人工标注的依赖,LEAF框架可以降低IQA系统的部署成本,并加速其在实际应用中的落地。
📄 摘要(原文)
Recent multimodal large language models (MLLMs) have demonstrated strong capabilities in image quality assessment (IQA) tasks. However, adapting such large-scale models is computationally expensive and still relies on substantial Mean Opinion Score (MOS) annotations. We argue that for MLLM-based IQA, the core bottleneck lies not in the quality perception capacity of MLLMs, but in MOS scale calibration. Therefore, we propose LEAF, a Label-Efficient Image Quality Assessment Framework that distills perceptual quality priors from an MLLM teacher into a lightweight student regressor, enabling MOS calibration with minimal human supervision. Specifically, the teacher conducts dense supervision through point-wise judgments and pair-wise preferences, with an estimate of decision reliability. Guided by these signals, the student learns the teacher's quality perception patterns through joint distillation and is calibrated on a small MOS subset to align with human annotations. Experiments on both user-generated and AI-generated IQA benchmarks demonstrate that our method significantly reduces the need for human annotations while maintaining strong MOS-aligned correlations, making lightweight IQA practical under limited annotation budgets.