Context Tokens are Anchors: Understanding the Repetition Curse in dMLLMs from an Information Flow Perspective
作者: Qiyan Zhao, Xiaofeng Zhang, Shuochen Chang, Qianyu Chen, Xiaosong Yuan, Xuhang Chen, Luoqi Liu, Jiajun Zhang, Xu-Yao Zhang, Da-Han Wang
分类: cs.CV
发布日期: 2026-01-28
备注: Accepted in ICLR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出CoTA,通过增强上下文token信息流缓解dMLLM中的重复生成问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 扩散模型 重复生成 信息流 上下文Token
📋 核心要点
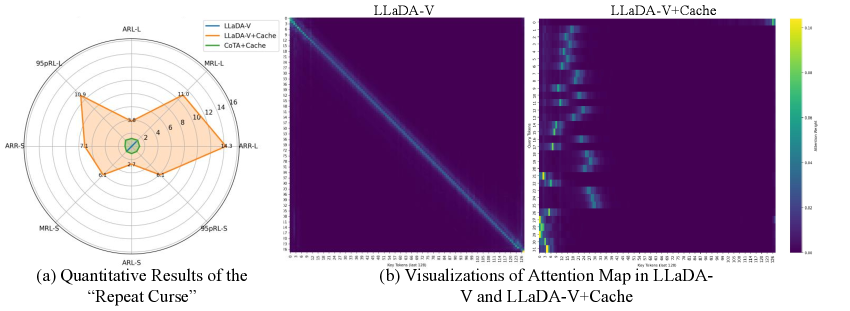
- dMLLM依赖缓存加速解码,但易出现重复生成,即“重复诅咒”。
- CoTA增强上下文token的注意力,并引入置信度惩罚,缓解重复生成。
- 实验表明CoTA能有效缓解重复,并在通用任务上提升性能。
📝 摘要(中文)
近期的基于扩散的多模态大语言模型(dMLLMs)面临着高推理延迟的问题,因此依赖缓存技术来加速解码。然而,缓存机制的应用常常导致不期望的重复文本生成,我们称之为 extbf{重复诅咒}。为了更好地研究这个问题背后的潜在机制,我们从信息流的角度分析了重复生成。我们的工作揭示了三个关键发现:(1)上下文token聚合语义信息作为锚点并指导最终预测;(2)随着信息在层间传播,上下文token的熵在更深层收敛,反映了模型预测确定性的增长;(3)重复通常与上下文token信息流的中断以及它们在更深层熵无法收敛有关。基于这些见解,我们提出 extbf{CoTA},一种用于缓解重复的即插即用方法。CoTA增强上下文token的注意力以保留内在的信息流模式,同时在解码期间引入置信度惩罚项,以避免由不确定的上下文token驱动的输出。通过广泛的实验,CoTA在缓解重复方面表现出显著的有效性,并在通用任务上实现了持续的性能提升。
🔬 方法详解
问题定义:论文旨在解决扩散模型为基础的多模态大语言模型(dMLLMs)在推理过程中,由于使用缓存机制加速解码而产生的重复文本生成问题,即“重复诅咒”。现有方法未能充分理解重复生成背后的机制,导致缓解效果不佳。
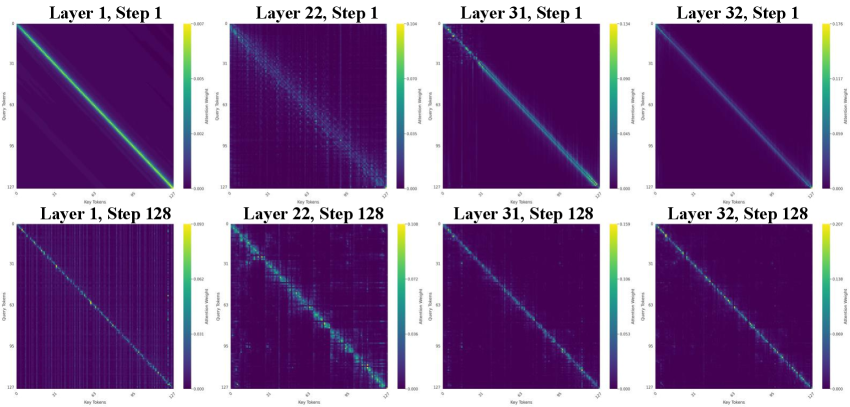
核心思路:论文的核心思路是从信息流的角度分析重复生成的原因。作者认为上下文token在模型中扮演着“锚点”的角色,聚合语义信息并指导最终预测。重复生成通常与上下文token信息流的中断以及熵无法收敛有关。因此,通过增强上下文token的注意力,保持其信息流的完整性,并对不确定的上下文token进行惩罚,可以有效缓解重复生成。
技术框架:CoTA是一个即插即用的方法,可以应用于现有的dMLLM架构中。它主要包含两个模块:1) 上下文token注意力增强模块:通过调整注意力机制,增强模型对上下文token的关注,从而更好地保留其信息流模式。2) 置信度惩罚模块:在解码过程中,对由不确定的上下文token驱动的输出进行惩罚,降低其被选择的概率。
关键创新:该论文的关键创新在于从信息流的角度理解重复生成问题,并提出了相应的解决方案。与以往主要关注解码策略或模型结构的改进不同,CoTA直接针对上下文token的信息流进行干预,从而更有效地缓解重复生成。
关键设计:CoTA的关键设计包括:1) 上下文token注意力增强的具体实现方式(例如,通过调整注意力权重或引入额外的注意力头)。2) 置信度惩罚项的具体形式和参数设置(例如,惩罚系数的大小)。这些设计旨在平衡模型生成的多样性和避免重复生成。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CoTA能够显著缓解dMLLM中的重复生成问题,并在通用任务上实现了持续的性能提升。具体的性能数据和对比基线在论文中给出,表明CoTA是一种有效的缓解重复生成的方法。
🎯 应用场景
该研究成果可应用于各种基于扩散模型的多模态大语言模型,提升其文本生成质量和用户体验。例如,在图像描述、视频字幕、对话生成等任务中,可以有效减少重复文本的出现,提高生成内容的可读性和流畅性。此外,该方法还可以应用于其他类型的生成模型,例如文本生成、代码生成等,具有广泛的应用前景。
📄 摘要(原文)
Recent diffusion-based Multimodal Large Language Models (dMLLMs) suffer from high inference latency and therefore rely on caching techniques to accelerate decoding. However, the application of cache mechanisms often introduces undesirable repetitive text generation, a phenomenon we term the \textbf{Repeat Curse}. To better investigate underlying mechanism behind this issue, we analyze repetition generation through the lens of information flow. Our work reveals three key findings: (1) context tokens aggregate semantic information as anchors and guide the final predictions; (2) as information propagates across layers, the entropy of context tokens converges in deeper layers, reflecting the model's growing prediction certainty; (3) Repetition is typically linked to disruptions in the information flow of context tokens and to the inability of their entropy to converge in deeper layers. Based on these insights, we present \textbf{CoTA}, a plug-and-play method for mitigating repetition. CoTA enhances the attention of context tokens to preserve intrinsic information flow patterns, while introducing a penalty term to the confidence score during decoding to avoid outputs driven by uncertain context tokens. With extensive experiments, CoTA demonstrates significant effectiveness in alleviating repetition and achieves consistent performance improvements on general tasks. Code is available at https://github.com/ErikZ719/CoTA