MARE: Multimodal Alignment and Reinforcement for Explainable Deepfake Detection via Vision-Language Models
作者: Wenbo Xu, Wei Lu, Xiangyang Luo, Jiantao Zhou
分类: cs.CV
发布日期: 2026-01-28
💡 一句话要点
提出MARE,通过多模态对齐与强化学习,实现可解释的Deepfake检测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Deepfake检测 视觉-语言模型 多模态对齐 强化学习 可解释性 伪造解耦 人脸语义
📋 核心要点
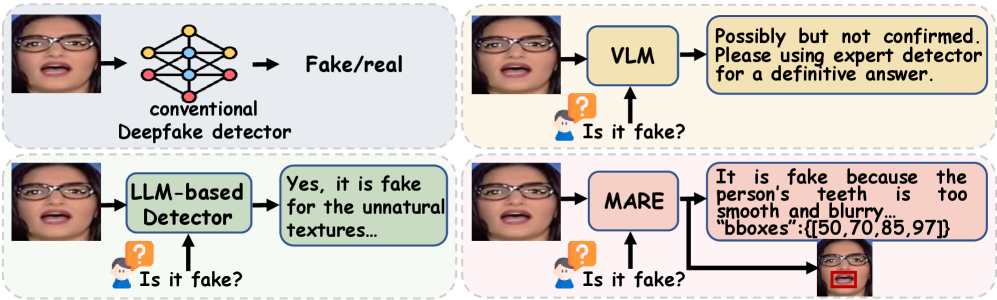
- 现有Deepfake检测方法主要集中于分类或空间定位,难以应对生成模型快速发展带来的新挑战。
- MARE通过多模态对齐与强化学习,激励视觉-语言模型生成文本-空间对齐的推理内容,提升检测可靠性。
- 实验结果表明,MARE在准确性和可靠性方面均达到SOTA,验证了其在Deepfake检测中的有效性。
📝 摘要(中文)
深度伪造检测是一个被广泛研究的课题,对于打击恶意内容的传播至关重要。现有的方法主要将该问题建模为分类或空间定位问题。生成模型的快速发展对深度伪造检测提出了新的要求。本文提出了一种用于可解释深度伪造检测的多模态对齐与强化学习方法,称为MARE,旨在提高视觉-语言模型(VLM)在深度伪造检测和推理中的准确性和可靠性。具体来说,MARE设计了全面的奖励函数,结合来自人类反馈的强化学习(RLHF),以激励生成符合人类偏好的文本-空间对齐的推理内容。此外,MARE引入了一个伪造解耦模块,从高层人脸语义中捕获内在的伪造痕迹,从而提高其真实性检测能力。我们对MARE生成的推理内容进行了全面的评估。定量和定性的实验结果表明,MARE在准确性和可靠性方面都达到了最先进的性能。
🔬 方法详解
问题定义:当前的Deepfake检测方法,例如分类和空间定位,难以有效应对快速发展的生成模型所制造的复杂Deepfake。这些方法缺乏可解释性,难以提供伪造的理由,并且在面对新的伪造技术时泛化能力较弱。因此,需要一种更准确、可靠且可解释的Deepfake检测方法。
核心思路:MARE的核心思路是利用视觉-语言模型(VLM)的强大推理能力,通过多模态对齐和强化学习,使模型能够生成文本-空间对齐的推理内容,从而提高Deepfake检测的准确性和可解释性。通过引入人类反馈的强化学习(RLHF),使模型的推理过程更符合人类的偏好,从而提高检测的可靠性。
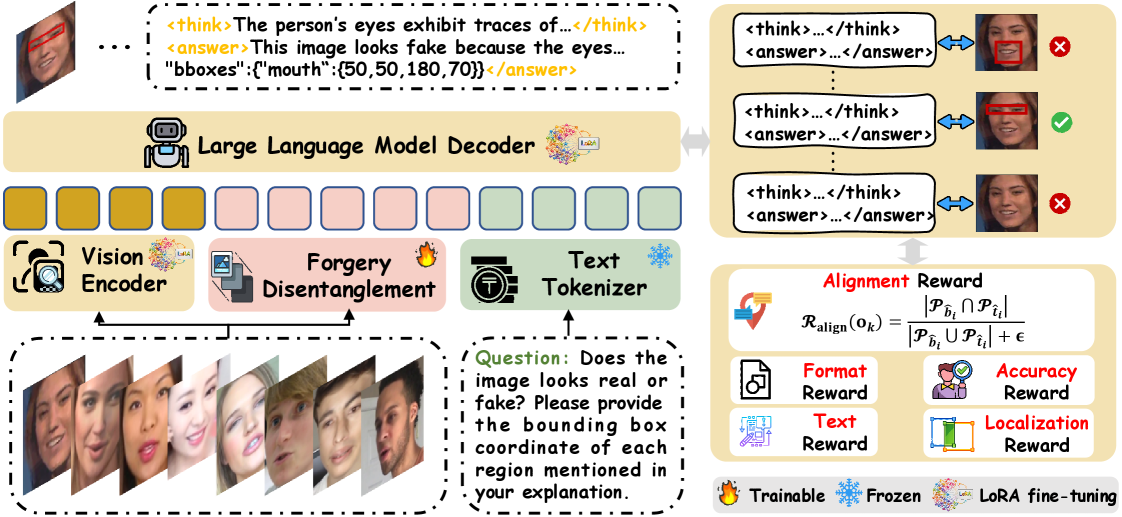
技术框架:MARE的整体框架包含以下几个主要模块:1) 视觉-语言模型(VLM):作为基础模型,用于提取图像和文本特征,并进行多模态融合。2) 伪造解耦模块:用于从高层人脸语义中捕获内在的伪造痕迹。3) 奖励函数设计:设计全面的奖励函数,用于指导强化学习过程,包括准确性奖励、对齐奖励和人类偏好奖励。4) 强化学习模块:利用RLHF,根据奖励函数优化VLM的推理策略。
关键创新:MARE的关键创新在于:1) 提出了多模态对齐和强化学习相结合的方法,用于提高VLM在Deepfake检测中的准确性和可靠性。2) 设计了全面的奖励函数,结合人类反馈,使模型的推理过程更符合人类的偏好。3) 引入了伪造解耦模块,从高层人脸语义中捕获内在的伪造痕迹,从而提高其真实性检测能力。
关键设计:奖励函数的设计是关键。准确性奖励用于衡量模型预测的准确性;对齐奖励用于衡量模型生成的文本推理内容与图像的空间区域是否对齐;人类偏好奖励则通过RLHF学习人类对推理内容的偏好。伪造解耦模块的具体实现方式未知,但推测可能使用了某种形式的注意力机制或特征解耦技术。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MARE在Deepfake检测的准确性和可靠性方面均达到了SOTA性能。具体性能数据未知,但论文强调了MARE在生成可解释推理内容方面的优势,并通过定量和定性实验验证了其有效性。与现有方法相比,MARE能够提供更可靠的Deepfake检测结果,并能够解释伪造的原因。
🎯 应用场景
MARE可应用于社交媒体平台、新闻媒体机构等,用于自动检测和标记Deepfake内容,从而减少虚假信息的传播,维护网络安全。该研究还有助于提高公众对Deepfake技术的认知,增强防范意识,并为相关法律法规的制定提供技术支持。未来,该技术可进一步扩展到其他类型的多媒体内容伪造检测。
📄 摘要(原文)
Deepfake detection is a widely researched topic that is crucial for combating the spread of malicious content, with existing methods mainly modeling the problem as classification or spatial localization. The rapid advancements in generative models impose new demands on Deepfake detection. In this paper, we propose multimodal alignment and reinforcement for explainable Deepfake detection via vision-language models, termed MARE, which aims to enhance the accuracy and reliability of Vision-Language Models (VLMs) in Deepfake detection and reasoning. Specifically, MARE designs comprehensive reward functions, incorporating reinforcement learning from human feedback (RLHF), to incentivize the generation of text-spatially aligned reasoning content that adheres to human preferences. Besides, MARE introduces a forgery disentanglement module to capture intrinsic forgery traces from high-level facial semantics, thereby improving its authenticity detection capability. We conduct thorough evaluations on the reasoning content generated by MARE. Both quantitative and qualitative experimental results demonstrate that MARE achieves state-of-the-art performance in terms of accuracy and reliability.