HINT: Hierarchical Interaction Modeling for Autoregressive Multi-Human Motion Generation
作者: Mengge Liu, Yan Di, Gu Wang, Yun Qu, Dekai Zhu, Yanyan Li, Xiangyang Ji
分类: cs.CV
发布日期: 2026-01-28
💡 一句话要点
HINT:用于自回归多人运动生成的层级交互建模框架
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 多人运动生成 自回归模型 层级交互建模 扩散模型 文本驱动 运动表征学习 滑动窗口 人机交互
📋 核心要点
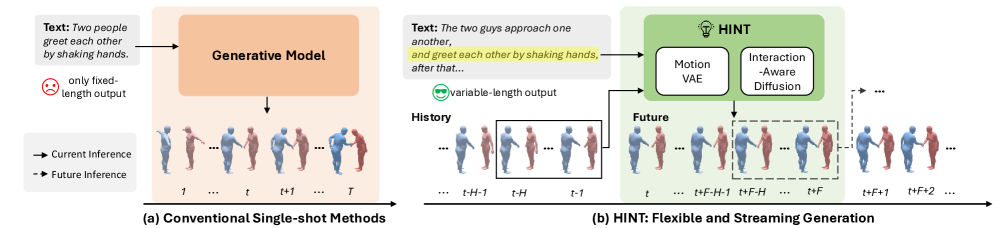
- 现有离线方法难以处理长文本或可变文本,以及变化的人员数量,限制了其在复杂交互场景下的应用。
- HINT通过层级交互建模,解耦运动表征,并采用滑动窗口策略,实现高效的自回归多人运动生成。
- 实验表明,HINT在InterHuman数据集上取得了显著的性能提升,FID指标从5.154降低到3.100。
📝 摘要(中文)
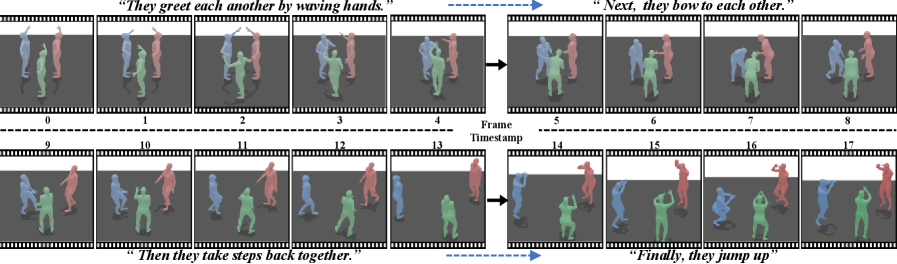
本文提出HINT,一个用于多人运动生成的自回归框架,该框架通过层级交互建模在扩散模型中实现。HINT利用解耦的运动表征,在规范化的潜在空间中将局部运动语义与人际交互分离,从而直接适应不同数量的人员参与,无需额外优化。HINT采用滑动窗口策略进行高效的在线生成,并聚合窗口内的局部条件和窗口间的全局条件,以捕捉过去的人类历史、人际依赖关系并与文本指导对齐。该策略不仅实现了窗口内的细粒度交互建模,还保持了长序列的连贯性。在公共基准测试上的大量实验表明,HINT的性能与强大的离线模型相匹配,并超过了自回归基线。特别是在InterHuman数据集上,HINT实现了3.100的FID,显著优于之前5.154的最优结果。
🔬 方法详解
问题定义:本文旨在解决文本驱动的多人运动生成问题,尤其关注复杂交互场景。现有离线方法通常生成固定长度的运动,且参与者数量固定,难以处理长文本或可变文本,以及不同数量的智能体。自回归方法是解决这些限制的自然选择,但如何有效地建模人际交互和保持长时序一致性仍然是一个挑战。
核心思路:HINT的核心思路是利用层级交互建模,将局部运动语义与人际交互解耦,并在自回归框架中逐步预测未来运动。通过规范化的潜在空间,模型可以灵活地适应不同数量的参与者。滑动窗口策略则用于高效的在线生成,并聚合局部和全局条件,以捕捉过去的历史、人际依赖关系和文本指导。
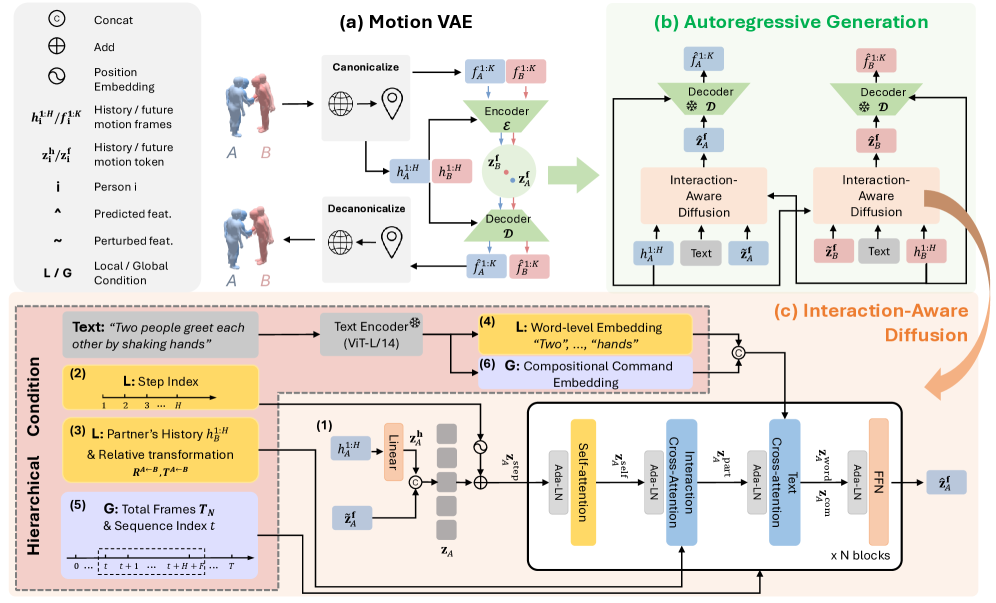
技术框架:HINT的整体框架包含以下几个主要模块:1) 运动表征模块,用于将原始运动数据编码到解耦的潜在空间中;2) 交互建模模块,利用滑动窗口策略,在局部窗口内建模细粒度的人际交互,并在全局范围内保持长时序一致性;3) 扩散模型,用于在自回归过程中逐步生成未来运动。模型首先将文本和历史运动作为条件输入,然后通过扩散过程逐步生成下一帧的运动。
关键创新:HINT的关键创新在于其层级交互建模方法。通过解耦运动表征,模型可以灵活地适应不同数量的参与者,而无需额外的微调。滑动窗口策略则允许模型在局部窗口内建模细粒度的人际交互,并在全局范围内保持长时序一致性。此外,HINT是第一个用于多人运动生成的自回归扩散模型。
关键设计:HINT采用变分自编码器(VAE)来学习解耦的运动表征。滑动窗口的大小是一个重要的参数,需要根据具体的应用场景进行调整。损失函数包括重构损失、KL散度和对抗损失,用于训练VAE和扩散模型。扩散模型采用U-Net结构,并引入了注意力机制来建模文本和历史运动之间的关系。
🖼️ 关键图片
📊 实验亮点
HINT在InterHuman数据集上取得了显著的性能提升,FID指标从之前的最佳结果5.154降低到3.100,表明其生成的运动更加逼真和自然。此外,实验还表明HINT的性能与强大的离线模型相匹配,并超过了自回归基线,验证了其有效性和优越性。
🎯 应用场景
HINT在虚拟现实、游戏、电影制作等领域具有广泛的应用前景。它可以用于生成逼真和自然的虚拟人物互动场景,例如,模拟人群在街道上的行走、人们在会议室中的交流等。此外,HINT还可以用于人机交互,例如,根据用户的语音或文本指令,生成相应的机器人运动。
📄 摘要(原文)
Text-driven multi-human motion generation with complex interactions remains a challenging problem. Despite progress in performance, existing offline methods that generate fixed-length motions with a fixed number of agents, are inherently limited in handling long or variable text, and varying agent counts. These limitations naturally encourage autoregressive formulations, which predict future motions step by step conditioned on all past trajectories and current text guidance. In this work, we introduce HINT, the first autoregressive framework for multi-human motion generation with Hierarchical INTeraction modeling in diffusion. First, HINT leverages a disentangled motion representation within a canonicalized latent space, decoupling local motion semantics from inter-person interactions. This design facilitates direct adaptation to varying numbers of human participants without requiring additional refinement. Second, HINT adopts a sliding-window strategy for efficient online generation, and aggregates local within-window and global cross-window conditions to capture past human history, inter-person dependencies, and align with text guidance. This strategy not only enables fine-grained interaction modeling within each window but also preserves long-horizon coherence across all the long sequence. Extensive experiments on public benchmarks demonstrate that HINT matches the performance of strong offline models and surpasses autoregressive baselines. Notably, on InterHuman, HINT achieves an FID of 3.100, significantly improving over the previous state-of-the-art score of 5.154.