MMSF: Multitask and Multimodal Supervised Framework for WSI Classification and Survival Analysis
作者: Chengying She, Chengwei Chen, Xinran Zhang, Ben Wang, Lizhuang Liu, Chengwei Shao, Yun Bian
分类: cs.CV
发布日期: 2026-01-28
备注: Submitted to "Biomedical Signal Processing and Control"
💡 一句话要点
MMSF:用于WSI分类和生存分析的多任务多模态监督框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全切片图像 多模态融合 生存分析 多任务学习 计算病理学
📋 核心要点
- 现有方法难以有效整合全切片图像(WSI)和临床数据等异构信息,因为它们具有不同的统计特性和尺度。
- MMSF通过显式分解和融合跨模态信息,并利用基于Mamba的MIL编码器,实现了更有效的多模态特征学习。
- 在多个数据集上的实验表明,MMSF在WSI分类、生存分析等任务上显著优于现有方法,C-index最高提升9.8%。
📝 摘要(中文)
多模态证据在计算病理学中至关重要:千兆像素的全切片图像捕获肿瘤形态,而患者级别的临床描述符保留了用于预后的补充上下文。整合这种异构信号仍然具有挑战性,因为特征空间表现出不同的统计数据和尺度。我们引入了MMSF,这是一个建立在线性复杂度MIL骨干上的多任务和多模态监督框架,它显式地分解和融合跨模态信息。MMSF包括一个图特征提取模块,用于嵌入patch级别的组织拓扑;一个临床数据嵌入模块,用于标准化患者属性;一个特征融合模块,用于对齐模态共享和模态特定的表示;以及一个基于Mamba的MIL编码器,带有用于多任务预测的头部。在CAMELYON16和TCGA-NSCLC上的实验表明,与竞争基线相比,准确率提高了2.1-6.6%,AUC提高了2.2-6.9%;对五个TCGA生存队列的评估表明,与单模态方法相比,C-index提高了7.1-9.8%,与多模态替代方案相比,提高了5.6-7.1%。
🔬 方法详解
问题定义:论文旨在解决如何有效融合全切片病理图像(WSI)和患者临床数据,以提高肿瘤分类和生存分析的准确性。现有方法难以处理WSI图像的超高分辨率和计算复杂度,以及不同模态数据之间的异构性,导致模型性能受限。
核心思路:论文的核心思路是设计一个多任务多模态的监督学习框架,该框架能够显式地分解和融合跨模态信息,同时利用线性复杂度的MIL(Multiple Instance Learning)骨干网络来处理WSI图像。通过对模态共享和模态特定的表示进行对齐,从而更好地利用不同模态数据之间的互补信息。
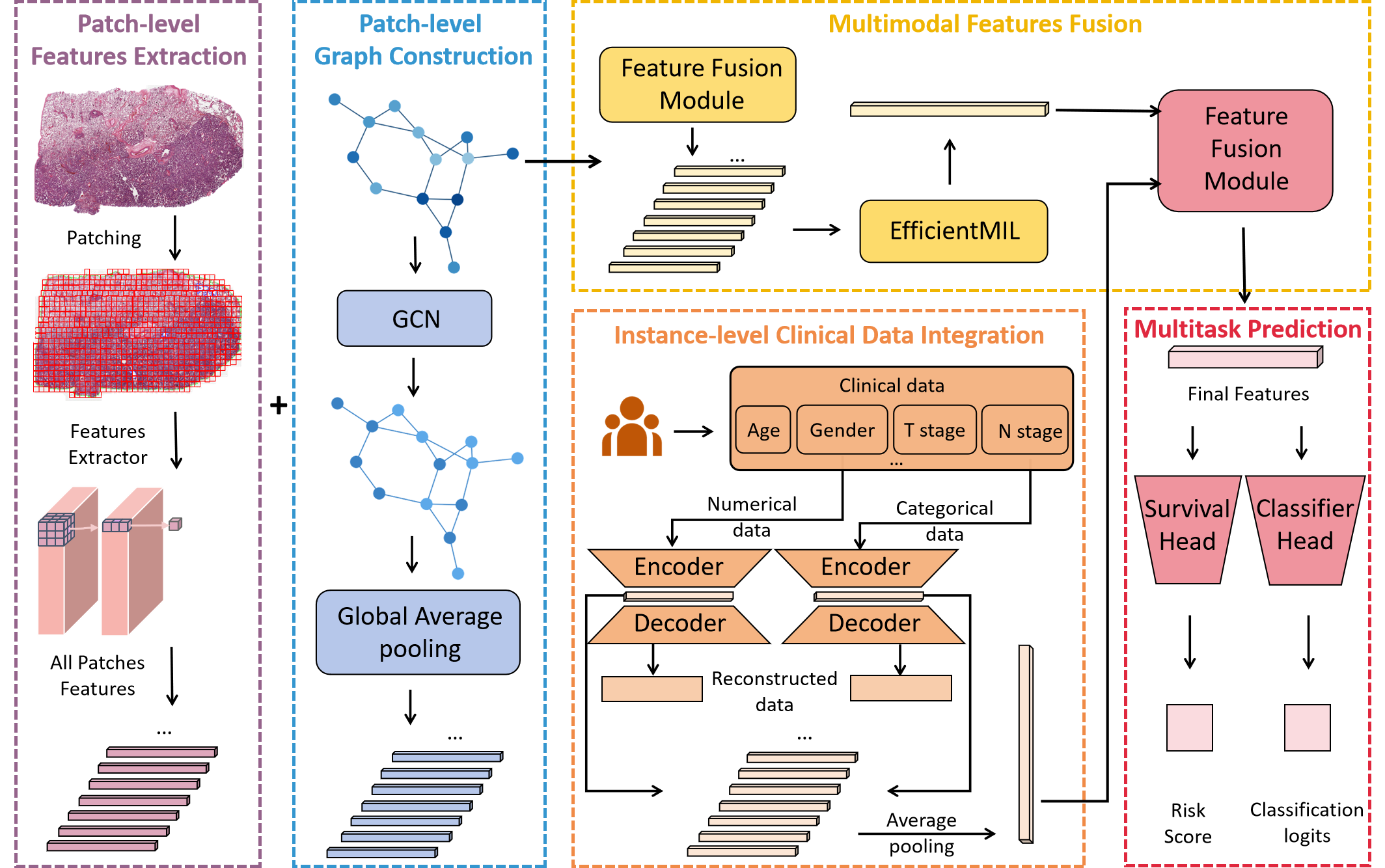
技术框架:MMSF框架包含四个主要模块:1) 图特征提取模块,用于提取WSI图像patch级别的组织拓扑信息;2) 临床数据嵌入模块,用于标准化患者的临床属性;3) 特征融合模块,用于对齐模态共享和模态特定的表示;4) 基于Mamba的MIL编码器,用于学习WSI图像的全局表示,并进行多任务预测(如肿瘤分类和生存分析)。
关键创新:论文的关键创新在于:1) 显式地分解和融合跨模态信息,从而更好地利用不同模态数据之间的互补信息;2) 采用基于Mamba的MIL编码器,该编码器具有线性复杂度,能够有效处理WSI图像;3) 设计了一个多任务学习框架,能够同时进行肿瘤分类和生存分析。
关键设计:图特征提取模块使用图神经网络来学习patch级别的组织拓扑信息。临床数据嵌入模块使用全连接神经网络来标准化患者的临床属性。特征融合模块使用注意力机制来对齐模态共享和模态特定的表示。基于Mamba的MIL编码器使用Mamba架构来学习WSI图像的全局表示。损失函数包括分类损失和生存分析损失,通过加权求和的方式进行优化。
🖼️ 关键图片

📊 实验亮点
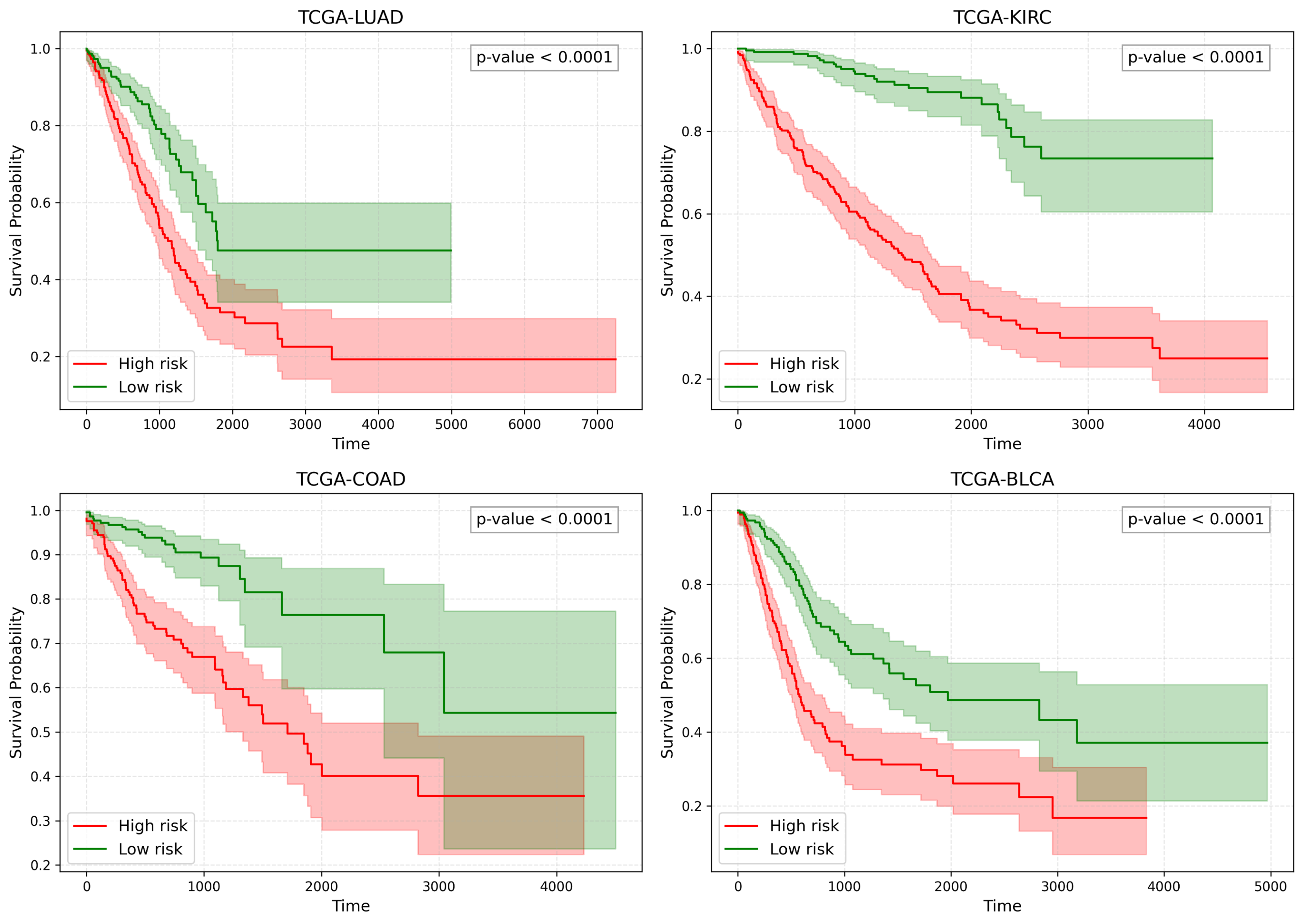
MMSF在CAMELYON16和TCGA-NSCLC数据集上,相比现有基线方法,分类准确率提升了2.1-6.6%,AUC提升了2.2-6.9%。在五个TCGA生存队列上,相比单模态方法,C-index提升了7.1-9.8%,相比多模态替代方案,提升了5.6-7.1%。实验结果表明,MMSF能够有效融合多模态信息,显著提高肿瘤分类和生存分析的性能。
🎯 应用场景
该研究成果可应用于辅助病理诊断,提高肿瘤分类和预后预测的准确性。通过整合病理图像和临床数据,可以为医生提供更全面的信息,从而制定更个性化的治疗方案。未来,该方法有望推广到其他疾病的诊断和预后预测中,具有重要的临床应用价值。
📄 摘要(原文)
Multimodal evidence is critical in computational pathology: gigapixel whole slide images capture tumor morphology, while patient-level clinical descriptors preserve complementary context for prognosis. Integrating such heterogeneous signals remains challenging because feature spaces exhibit distinct statistics and scales. We introduce MMSF, a multitask and multimodal supervised framework built on a linear-complexity MIL backbone that explicitly decomposes and fuses cross-modal information. MMSF comprises a graph feature extraction module embedding tissue topology at the patch level, a clinical data embedding module standardizing patient attributes, a feature fusion module aligning modality-shared and modality-specific representations, and a Mamba-based MIL encoder with multitask prediction heads. Experiments on CAMELYON16 and TCGA-NSCLC demonstrate 2.1--6.6\% accuracy and 2.2--6.9\% AUC improvements over competitive baselines, while evaluations on five TCGA survival cohorts yield 7.1--9.8\% C-index improvements compared with unimodal methods and 5.6--7.1\% over multimodal alternatives.