Physically Guided Visual Mass Estimation from a Single RGB Image
作者: Sungjae Lee, Junhan Jeong, Yeonjoo Hong, Kwang In Kim
分类: cs.CV, cs.AI
发布日期: 2026-01-28
💡 一句话要点
提出一种物理引导的单RGB图像物体质量估计框架,提升质量预测精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 质量估计 单目深度估计 视觉-语言模型 物理引导 实例自适应 三维重建
📋 核心要点
- 现有方法难以仅从RGB图像准确估计物体质量,因为质量与物体的体积和密度相关,而密度难以直接观测。
- 该论文提出一种物理引导的框架,利用单目深度估计恢复几何信息,并结合视觉-语言模型提取材料语义,从而推断体积和密度。
- 实验结果表明,该方法在image2mass和ABO-500数据集上优于当前最优方法,证明了其有效性。
📝 摘要(中文)
从视觉输入估计物体质量极具挑战,因为质量取决于几何体积和材料相关的密度,而这两者都无法直接从RGB图像中观察到。因此,从像素预测质量是一个不适定的问题,需要物理上有意义的表示来约束合理的解空间。本文提出了一种物理结构化的单图像质量估计框架,通过将视觉线索与控制质量的物理因素对齐来解决这种模糊性。从单张RGB图像中,我们通过单目深度估计恢复以物体为中心的三维几何信息以推断体积,并使用视觉-语言模型提取粗略的材料语义以指导与密度相关的推理。这些几何、语义和外观表示通过实例自适应门控机制融合,并且两个物理引导的潜在因子(与体积和密度相关)通过仅在质量监督下的单独回归头进行预测。在image2mass和ABO-500上的实验表明,所提出的方法始终优于最先进的方法。
🔬 方法详解
问题定义:论文旨在解决仅使用单张RGB图像精确估计物体质量的问题。现有方法难以同时准确估计物体的体积和密度,导致质量预测不准确。特别是,材料密度与外观的关联性复杂,难以直接从像素信息推断。
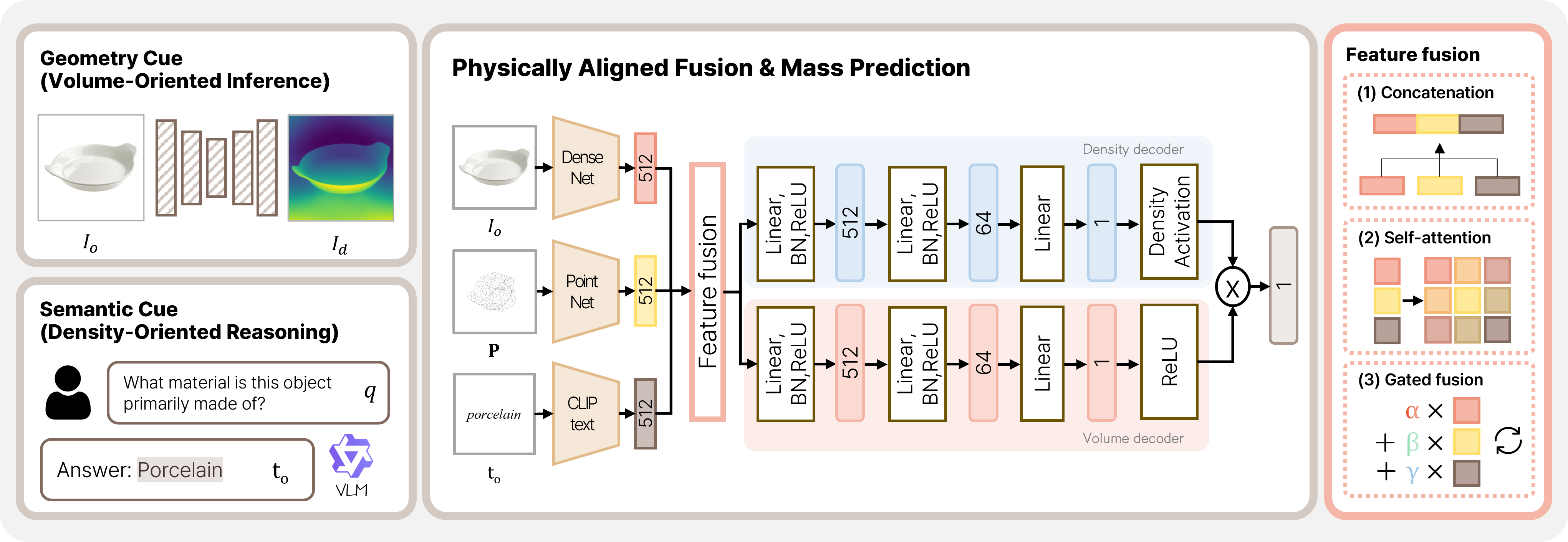
核心思路:论文的核心思路是将视觉信息与物理因素对齐,利用单目深度估计推断物体体积,并结合视觉-语言模型提取材料语义以指导密度估计。通过将质量估计分解为体积和密度两个物理相关的潜在因子,并分别进行预测,从而降低了问题的复杂度。
技术框架:该方法包含以下主要模块:1) 单目深度估计模块,用于从RGB图像中恢复物体的三维几何信息,从而估计体积;2) 视觉-语言模型,用于提取图像的材料语义信息,指导密度估计;3) 实例自适应门控机制,用于融合几何、语义和外观表示;4) 两个独立的回归头,分别预测与体积和密度相关的潜在因子,最终预测物体质量。
关键创新:该方法最重要的创新点在于其物理引导的框架,将质量估计分解为体积和密度两个物理相关的潜在因子,并利用单目深度估计和视觉-语言模型分别进行估计。此外,实例自适应门控机制能够有效地融合不同模态的信息,提升了预测精度。
关键设计:单目深度估计采用现有的成熟模型,视觉-语言模型采用CLIP等模型提取图像的语义信息。实例自适应门控机制使用注意力机制,根据输入图像的特征动态调整不同模态信息的权重。损失函数主要包括质量预测的回归损失,以及可选的深度预测损失。具体的网络结构和参数设置在论文中有详细描述,但具体数值未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在image2mass和ABO-500数据集上均取得了优于当前最优方法的结果。具体性能提升幅度未知,但摘要中提到是“consistently outperforms state-of-the-art methods”,表明性能提升具有一致性。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、智能仓储等领域。例如,机器人可以利用该方法估计物体的质量,从而更安全有效地抓取和搬运物体。在自动驾驶领域,可以用于估计车辆载重,从而优化车辆控制策略。此外,该方法还可以用于商品识别和库存管理,提升效率。
📄 摘要(原文)
Estimating object mass from visual input is challenging because mass depends jointly on geometric volume and material-dependent density, neither of which is directly observable from RGB appearance. Consequently, mass prediction from pixels is ill-posed and therefore benefits from physically meaningful representations to constrain the space of plausible solutions. We propose a physically structured framework for single-image mass estimation that addresses this ambiguity by aligning visual cues with the physical factors governing mass. From a single RGB image, we recover object-centric three-dimensional geometry via monocular depth estimation to inform volume and extract coarse material semantics using a vision-language model to guide density-related reasoning. These geometry, semantic, and appearance representations are fused through an instance-adaptive gating mechanism, and two physically guided latent factors (volume- and density-related) are predicted through separate regression heads under mass-only supervision. Experiments on image2mass and ABO-500 show that the proposed method consistently outperforms state-of-the-art methods.