Efficient Token Pruning for LLaDA-V
作者: Zhewen Wan, Tianchen Song, Chen Lin, Zhiyong Zhao, Xianpeng Lang
分类: cs.CV
发布日期: 2026-01-28
💡 一句话要点
针对LLaDA-V,提出一种高效的Token剪枝策略,显著降低计算成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLaDA-V Token剪枝 多模态模型 扩散模型 计算效率 视觉语言理解 模型优化
📋 核心要点
- LLaDA-V等扩散模型在多模态任务中表现出色,但其双向注意力机制和迭代去噪过程带来巨大的计算负担。
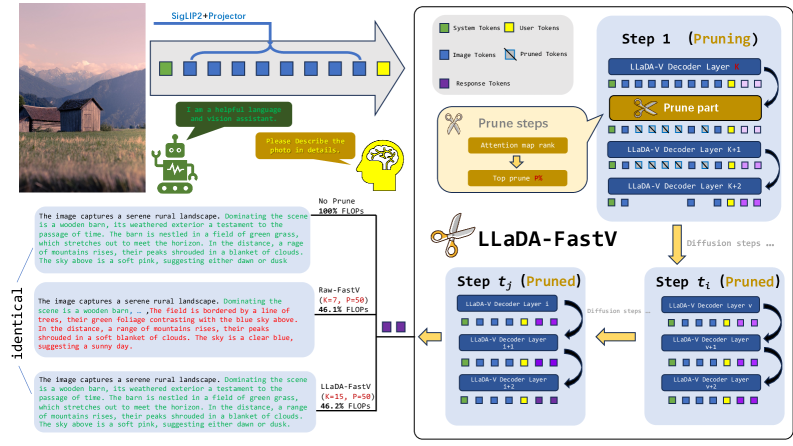
- 论文提出一种结构化Token剪枝策略,选择性地移除LLaDA-V中后层的视觉Token,以减少计算量,同时保留关键语义信息。
- 实验表明,该方法在降低高达65%计算成本的同时,仍能保持平均95%的任务性能,验证了其有效性。
📝 摘要(中文)
本文针对基于扩散的大型多模态模型LLaDA-V,其双向注意力机制和扩散式迭代去噪范式导致计算开销巨大。通过深入的注意力分析,发现LLaDA-V主要在中后层聚合跨模态信息,导致语义对齐延迟。受此启发,本文提出一种受FastV启发的结构化Token剪枝策略,选择性地移除指定层的部分视觉Token,以减少FLOPs,同时保留关键语义信息。据我们所知,这是首个在基于扩散的大型多模态模型中研究结构化Token剪枝的工作。与FastV专注于浅层剪枝不同,我们的方法针对第一个去噪步骤的中后层,以适应LLaDA-V的延迟注意力聚合,从而保持输出质量,并且第一步剪枝策略减少了所有后续步骤的计算。我们的框架为高效的LLaDA-V推理提供了经验基础,并突出了视觉感知剪枝在基于扩散的多模态模型中的潜力。在多个基准测试中,我们最佳配置将计算成本降低高达65%,同时保持平均95%的任务性能。
🔬 方法详解
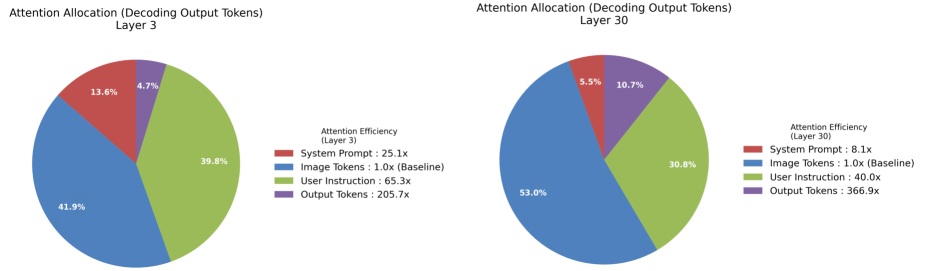
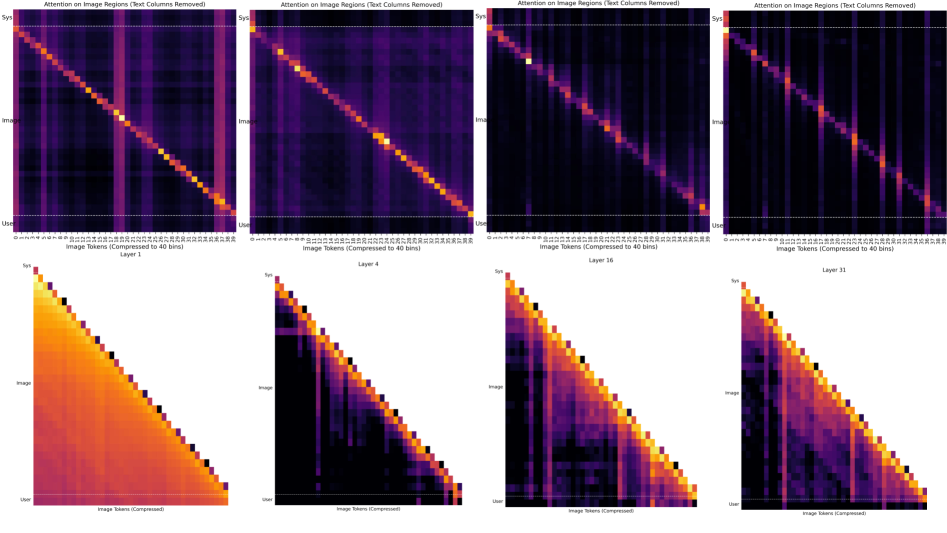
问题定义:LLaDA-V等基于扩散的大型多模态模型,由于其双向注意力机制和扩散式迭代去噪范式,在视觉Token的处理上存在大量的冗余计算,导致计算开销巨大。现有方法缺乏针对此类模型的有效优化策略,尤其是在Token层面的剪枝。
核心思路:论文的核心思路是观察到LLaDA-V的跨模态信息聚合主要发生在中后层,因此针对这些层进行Token剪枝,可以在减少计算量的同时,最大程度地保留关键的语义信息。通过在第一个去噪步骤中进行剪枝,可以减少所有后续步骤的计算。
技术框架:该方法基于LLaDA-V模型,并引入了一个结构化的Token剪枝模块。该模块在指定的中间到后层选择性地移除一部分视觉Token。具体流程包括:首先,对输入图像进行Token化处理;然后,在LLaDA-V的encoder中,经过若干层处理后,进入Token剪枝模块;该模块根据预设的剪枝比例,移除一部分视觉Token;最后,将剪枝后的Token输入到LLaDA-V的后续层进行处理,完成多模态信息的融合和生成。
关键创新:该方法的主要创新在于:1) 首次将结构化Token剪枝应用于基于扩散的大型多模态模型LLaDA-V;2) 针对LLaDA-V的特性,提出了在中后层进行剪枝的策略,与FastV等浅层剪枝方法不同;3) 通过在第一个去噪步骤进行剪枝,实现了对所有后续步骤的计算加速。
关键设计:关键设计包括:1) 剪枝比例的选择:需要根据具体的任务和模型进行调整,以在计算成本和性能之间取得平衡;2) 剪枝位置的选择:论文选择在第一个去噪步骤的中后层进行剪枝,以适应LLaDA-V的注意力聚合特性;3) 结构化剪枝:保证剪枝后的Token分布均匀,避免影响模型的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多个基准测试中,能够在降低高达65%计算成本的同时,保持平均95%的任务性能。这表明该方法能够在显著降低计算负担的同时,有效地保留模型的性能,具有很高的实用价值。该方法在视觉问答、图像字幕等任务上均取得了显著的加速效果。
🎯 应用场景
该研究成果可应用于各种需要高效多模态理解和生成的场景,例如智能客服、图像描述、视频编辑、机器人导航等。通过降低计算成本,该方法使得LLaDA-V等大型多模态模型能够在资源受限的设备上运行,从而扩展了其应用范围。未来,该方法可以进一步推广到其他基于扩散的多模态模型中。
📄 摘要(原文)
Diffusion-based large multimodal models, such as LLaDA-V, have demonstrated impressive capabilities in vision-language understanding and generation. However, their bidirectional attention mechanism and diffusion-style iterative denoising paradigm introduce significant computational overhead, as visual tokens are repeatedly processed across all layers and denoising steps. In this work, we conduct an in-depth attention analysis and reveal that, unlike autoregressive decoders, LLaDA-V aggregates cross-modal information predominantly in middle-to-late layers, leading to delayed semantic alignment. Motivated by this observation, we propose a structured token pruning strategy inspired by FastV, selectively removing a proportion of visual tokens at designated layers to reduce FLOPs while preserving critical semantic information. To the best of our knowledge, this is the first work to investigate structured token pruning in diffusion-based large multimodal models. Unlike FastV, which focuses on shallow-layer pruning, our method targets the middle-to-late layers of the first denoising step to align with LLaDA-V's delayed attention aggregation to maintain output quality, and the first-step pruning strategy reduces the computation across all subsequent steps. Our framework provides an empirical basis for efficient LLaDA-V inference and highlights the potential of vision-aware pruning in diffusion-based multimodal models. Across multiple benchmarks, our best configuration reduces computational cost by up to 65% while preserving an average of 95% task performance.